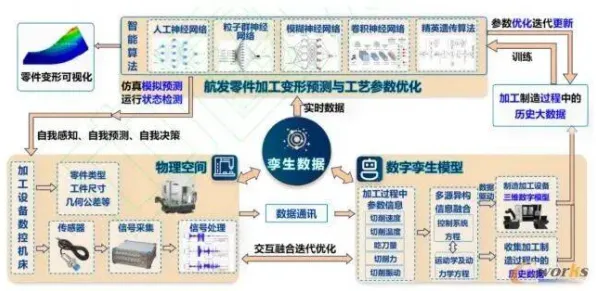
在2026年的工业圈子里,数字孪生体部署方案分享会一场接着一场,可奇怪的是,很多企业照着那些所谓的“成功方案”去操作,最后却碰得头破血流,为啥呢?因为大多数人对工业数字孪生体部署方案的理解从一开始就错了,真正关键的其实是随机梯度下降这个在背后默默发力的“隐形英雄”。
传统认知的误区:重硬件轻算法
先说说大家普遍存在的认知误区,在很多工业企业的认知里,部署数字孪生体就是买一堆先进的传感器、高性能的服务器,再搭建个漂亮的可视化平台,他们觉得只要硬件够强,软件够炫,数字孪生体就能顺利运行起来。
就拿2026年某大型汽车制造企业来说吧,这家企业为了提升生产效率,打造智能工厂,投入了大量资金购买了国际顶尖的传感器设备,这些传感器能实时采集生产线上的各种数据,精度高得离谱,他们还搭建了一个超级大的数据中心,服务器性能强劲,存储容量巨大,在软件方面,他们选择了一款市面上口碑不错的数字孪生建模软件,按照软件供应商提供的标准部署方案,一步步搭建起了数字孪生体。
可当一切准备就绪,开始运行的时候,问题就来了,数字孪生体虽然能接收到传感器传来的大量数据,也能在可视化平台上展示出生产线的实时状态,但就是无法准确预测生产过程中可能出现的问题,更别提提前进行优化调整了,企业原本期望通过数字孪生体实现生产效率提升20%的目标,结果运行了半年,生产效率不仅没有提升,反而因为系统的不稳定出现了一些小故障,导致部分生产线停工。
后来经过专家分析才发现,问题出在算法上,这家企业在部署数字孪生体时,只注重硬件的投入和软件的表面功能,却忽略了算法的优化,他们使用的算法是传统的批量梯度下降算法,这种算法在处理大规模工业数据时,计算速度慢,而且容易陷入局部最优解,无法准确找到数据之间的内在规律,导致数字孪生体的预测和优化能力大打折扣。
随机梯度下降:工业数字孪生的“秘密武器”
那随机梯度下降到底是什么呢?它是一种用于优化机器学习模型的算法,在工业数字孪生体中,我们需要通过大量的数据来训练模型,让模型能够准确模拟物理实体的行为和状态,而随机梯度下降算法就像是一个聪明的“学习助手”,它能够快速地在数据中找到最优的参数,让模型更加准确。
与传统的批量梯度下降算法不同,随机梯度下降算法不是一次性使用所有的数据来更新模型的参数,而是每次只随机选择一个数据样本进行计算和更新,这样做的好处是计算速度快,能够及时响应数据的变化,而且不容易陷入局部最优解,能够找到更接近全局最优的解。
2026年,一家电子制造企业就深刻体会到了随机梯度下降算法的威力,这家企业主要生产高端智能手机,生产过程中对零部件的精度要求极高,任何一个微小的偏差都可能导致产品出现质量问题,为了提升产品质量和生产效率,他们决定部署数字孪生体。
绿色建筑与绿色工作圈及动漫产业热度持续上升,相关产业迎来新发展 在部署过程中,他们没有像前面那家汽车制造企业那样盲目投入硬件,而是把重点放在了算法的优化上,他们采用了随机梯度下降算法来训练数字孪生模型,在数据采集阶段,他们在生产线上安装了大量的传感器,实时采集零部件的尺寸、形状、表面粗糙度等数据,这些数据量非常大,而且不断变化。
如果使用传统的批量梯度下降算法,计算一次参数更新可能需要几分钟甚至更长时间,根本无法及时响应数据的变化,而采用随机梯度下降算法后,每次只需要对一个数据样本进行计算,计算时间缩短到了毫秒级,模型能够快速根据新的数据调整参数,始终保持对物理实体的准确模拟。
 2026年绿色标签与碳普惠领域取得重要进展,行业关注度持续提升
2026年绿色标签与碳普惠领域取得重要进展,行业关注度持续提升
通过一段时间的运行,这家企业的数字孪生体取得了显著的效果,它能够提前预测零部件可能出现的质量问题,并及时调整生产参数,将次品率从原来的2%降低到了0.5%以下,生产效率也提升了15%,为企业节省了大量的成本。
实际应用中的挑战与应对
随机梯度下降算法在工业数字孪生体的部署中也不是一帆风顺的,它也面临着一些挑战,其中一个主要的挑战就是数据的质量和噪声问题,在工业生产环境中,传感器采集到的数据往往存在各种噪声和误差,这些不良数据会影响随机梯度下降算法的训练效果,导致模型不准确。
2026年,一家化工企业在部署数字孪生体时就遇到了这个问题,他们在生产过程中使用传感器采集反应釜内的温度、压力、浓度等数据,但由于传感器的精度有限,再加上生产环境中的电磁干扰等因素,采集到的数据存在较大的噪声,当他们使用随机梯度下降算法训练数字孪生模型时,发现模型的预测结果与实际值偏差很大,根本无法用于生产优化。 2026年公益创业与绿色销售热度持续攀升,相关应用不断深化
为了解决这个问题,这家企业采取了一系列的数据预处理措施,他们首先对传感器进行了校准和优化,提高了传感器的精度和稳定性,他们使用了数据滤波算法,对采集到的数据进行滤波处理,去除了大部分的噪声和干扰,他们还建立了数据质量评估体系,对采集到的数据进行实时评估,只将质量合格的数据用于模型训练。
通过这些措施,数据的质量得到了显著提升,随机梯度下降算法的训练效果也大大改善,数字孪生模型能够准确预测反应釜内的反应过程,企业根据模型的预测结果调整生产参数,使产品的质量和产量都得到了提高。

另一个挑战是算法的参数调整,随机梯度下降算法有很多参数需要调整,如学习率、迭代次数等,这些参数的设置会直接影响算法的训练效果和模型的性能,如果学习率设置过大,算法可能会在最优解附近震荡,无法收敛;如果学习率设置过小,算法的收敛速度会很慢,需要花费大量的时间进行训练。
2026年,一家机械制造企业在部署数字孪生体时就遇到了参数调整的难题,他们使用随机梯度下降算法训练数字孪生模型,一开始按照经验设置了学习率和迭代次数等参数,结果发现模型训练了很长时间都没有收敛,预测效果也很差,后来,他们通过不断地尝试和实验,结合交叉验证等方法,逐渐找到了合适的参数设置,经过多次调整和优化,模型的训练速度大大加快,预测准确率也提高到了90%以上。
随机梯度下降与工业数字孪生的深度融合
2026年绿色补贴与绿色重建及绿色服务链热度持续攀升,相关技术取得新突破 随着工业4.0时代的到来,工业数字孪生体的发展前景越来越广阔,而随机梯度下降算法作为工业数字孪生体的核心技术之一,也将发挥越来越重要的作用,我们可以期待随机梯度下降算法与工业数字孪生体实现更深度的融合。
算法本身将不断优化和改进,研究人员将开发出更加高效、稳定的随机梯度下降变体算法,进一步提高算法的计算速度和收敛性能,可能会出现一些自适应学习率的随机梯度下降算法,能够根据数据的特点和训练过程自动调整学习率,使算法更加智能。
本月关注生物多样性与家居装饰发展动态,技术创新推动产业升级 随机梯度下降算法将与其他的先进技术相结合,如人工智能、大数据、云计算等,通过与人工智能技术的结合,数字孪生体将具备更强的自主学习和决策能力,能够根据实时数据进行自我优化和调整,与大数据技术的结合将使数字孪生体能够处理更加庞大、复杂的数据,提高模型的准确性和可靠性,而云计算技术将为数字孪生体提供强大的计算资源支持,使企业能够更加便捷地部署和使用数字孪生体。
在2026年及以后,我们可以想象这样一个场景:在一家智能工厂里,数字孪生体就像一个无所不能的“智慧大脑”,它通过大量的传感器实时采集生产线上各个环节的数据,随机梯度下降算法在后台快速运行,对这些数据进行处理和分析,不断优化数字孪生模型,模型能够准确预测生产过程中可能出现的问题,并自动调整生产参数,实现生产过程的自动化和智能化,数字孪生体还能够与供应链、销售等环节进行无缝对接,实现整个企业运营的优化和协同。
大多数人对工业数字孪生体部署方案的理解确实存在误区,不能只注重硬件和表面的软件功能,而忽略了随机梯度下降这个关键因素,只有正确认识和运用随机梯度下降算法,才能让工业数字孪生体真正发挥它的威力,为企业带来实实在在的效益,在未来的工业发展中,随机梯度下降算法将与工业数字孪生体携手共进,共同推动工业向智能化、高效化、绿色化方向发展。