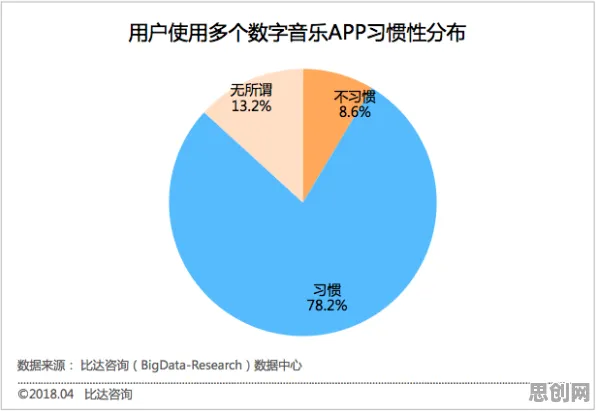
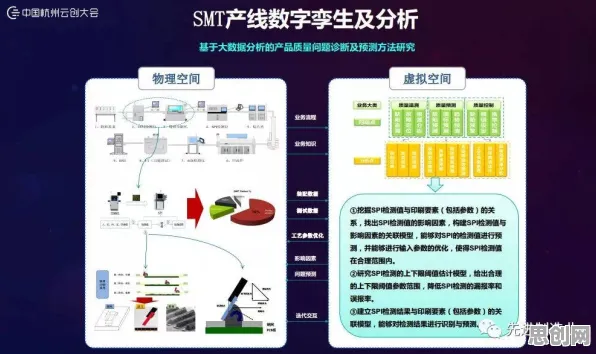
在2026年的工业领域,数字孪生体早已不是新鲜概念,从智能制造车间到智慧能源管理,从航空航天装备维护到城市交通系统优化,数字孪生体正以“虚拟镜像”的形式深度融入工业生产的全生命周期,当企业纷纷投入资源部署数字孪生体时,一个残酷的现实逐渐浮现:超过60%的工业数字孪生项目在落地3年内因“效果不达预期”被搁置或重构,而其中最核心的问题,往往藏在那些被忽视的“部署方案细节”里。
今年3月,国际工业互联网联盟(IIC)发布的《2026全球工业数字孪生应用白皮书》中,一组数据引发行业震动:在调研的127个工业数字孪生项目中,仅38%的项目实现了“虚拟模型与物理实体实时同步误差小于0.5%”的核心目标,而剩余项目中,有42%因“数据采集延迟导致模型失效”、15%因“模型更新频率不足引发决策偏差”、5%因“跨系统数据孤岛导致协同失败”,这些数字背后,暴露的是企业在部署数字孪生体时,对“数据质量”“模型更新机制”“系统协同性”等关键要素的忽视,而聚类分析——这一常被用于市场细分或用户画像的数据分析方法,正在成为破解工业数字孪生部署难题的“新钥匙”。
数据质量:被低估的“数字孪生生命线”
“数字孪生的核心是数据,但很多企业只关注模型搭建,却忽略了数据采集的‘最后一公里’。”这是某跨国汽车集团数字孪生项目负责人李工在2026年全球工业互联网大会上的感慨,该集团2024年启动的“智能工厂数字孪生”项目,曾因数据质量问题陷入困境。 生物燃料与绿色产业链及碳标签热度持续上升,相关产业迎来新机遇
项目初期,团队在车间部署了2000多个传感器,覆盖冲压、焊接、涂装、总装四大工艺环节,目标是构建一个能实时反映生产状态的数字孪生体,运行3个月后,模型显示的“设备利用率”与实际统计相差12%,导致生产排程频繁出错,经排查发现,问题出在数据采集环节:部分传感器因安装位置不当(如焊接车间的高温环境导致温度传感器读数偏差)、部分传感器因通信协议不兼容(不同厂商设备的数据格式无法统一解析)、还有部分传感器因维护不及时(涂装车间的粉尘堆积导致光学传感器失效),导致采集到的数据存在大量缺失、错误或延迟。
“我们当时以为只要传感器数量够多、覆盖够广,数据质量就有保障,结果恰恰相反。”李工回忆道,2025年,团队引入聚类分析方法,对采集到的数据进行“质量画像”:将同一工艺环节的传感器数据按时间序列聚类,通过分析不同簇的数据分布特征(如均值、方差、波动频率),快速定位异常数据源,在焊接车间的温度数据聚类中,发现某一簇数据的波动频率明显高于其他簇,进一步排查发现是某台焊接机器人的冷却系统故障导致温度异常,而该故障未被传统监控系统捕捉,通过这种方法,团队在6个月内将数据采集错误率从8.2%降至1.5%,数字孪生模型的准确率提升至92%。
“数据质量不是‘有没有’的问题,而是‘好不好’的问题,聚类分析帮我们找到了数据中的‘坏苹果’,让模型真正‘活’了起来。”李工说。
模型更新:从“静态搭建”到“动态进化”
如果说数据质量是数字孪生的“生命线”,那么模型更新机制就是其“成长基因”,在2026年的工业场景中,物理实体的状态是动态变化的——设备的磨损、工艺的调整、环境的波动,都会影响数字孪生模型的准确性,许多企业在部署时仍采用“一次性建模+定期更新”的传统模式,导致模型与实体逐渐脱节。

某风电企业2024年部署的“风机数字孪生”项目,就是一个典型案例,该项目旨在通过数字孪生体预测风机叶片的疲劳损伤,提前安排维护计划,初期,团队基于历史数据构建了静态模型,并设定每月更新一次参数,运行一年后,模型预测的叶片损伤位置与实际检修结果偏差达30%,导致多次“过度维护”(更换未损坏的叶片)和“维护不足”(未及时发现裂纹)。 2026年产业升级热度持续攀升,相关技术取得新突破
“问题出在模型更新频率上,风机的运行状态受风速、温度、湿度等多因素影响,这些因素每天都在变化,每月更新一次模型根本跟不上。”该企业首席数据官王总解释道,2025年,团队引入聚类分析优化模型更新机制:将风机运行数据按“风速-温度-湿度”三维特征聚类,形成不同的“运行工况簇”;针对每个簇,训练独立的子模型,并实时监测数据分布变化——当某簇的数据占比超过阈值(如从10%升至30%),则触发该簇对应子模型的更新。 本月废物利用与需求响应热度持续上升,相关领域迎来新机遇
“这种方法相当于给模型装了一个‘自适应开关’,它能根据实际运行状态自动调整更新频率。”王总说,2026年1月的数据显示,优化后的模型预测准确率提升至88%,维护成本降低22%,风机可用率提高至97.5%。“数字孪生不再是‘死模型’,而是能跟着设备一起‘成长’的活系统。”
系统协同:打破“数据孤岛”的最后一公里
在工业数字孪生的部署中,另一个常被忽视的关键是“系统协同性”,许多企业虽然构建了单个设备或生产线的数字孪生体,却因不同系统(如MES、ERP、SCADA)之间的数据格式不兼容、通信协议不统一,导致数字孪生体无法与其他业务系统协同,最终沦为“信息孤岛”。

某钢铁企业2024年启动的“智慧钢厂数字孪生”项目,就曾因系统协同问题陷入僵局,该项目旨在通过数字孪生体整合炼铁、炼钢、轧钢全流程数据,实现生产优化与能耗管理,在项目中期,团队发现不同车间的数据无法互通:炼铁车间的SCADA系统采用Modbus协议,炼钢车间的MES系统采用OPC UA协议,轧钢车间的能源管理系统则采用自定义协议,导致数字孪生平台无法实时获取全流程数据,优化建议无法落地执行。
“我们当时以为只要把数据接到同一个平台就行,没想到不同系统的‘语言’完全不通。”该项目技术负责人陈工说,2025年,团队引入聚类分析解决系统协同问题:首先对各系统的数据字段进行聚类,识别出“设备状态”“生产参数”“能耗指标”等核心数据簇;然后针对每个簇,开发统一的“数据翻译器”,将不同协议的数据转换为标准格式;最后通过聚类分析动态监测数据流——当某簇的数据在某个系统出现缺失或延迟,自动触发预警并定位问题源头。
“这种方法相当于给不同系统装了一个‘翻译官’,让它们能‘说同一种语言’。”陈工举例说,2026年2月,系统通过聚类分析发现炼钢车间的“钢水温度”数据在MES系统中缺失,而SCADA系统中有该数据但未同步,自动触发数据补录流程,避免了因温度偏差导致的轧钢质量事故。“数字孪生体不仅是‘监控工具’,更是能驱动全流程协同的‘决策中枢’。”
人才缺口:数字孪生部署的“隐形瓶颈”
除了技术层面的挑战,工业数字孪生的部署还面临一个“隐形瓶颈”——复合型人才的短缺,根据2026年人社部发布的《智能制造领域人才需求白皮书》,我国工业数字孪生相关岗位缺口达42万,其中既懂工业生产又懂数据分析的“双料人才”占比不足15%。
某化工企业2024年部署的“智能工厂数字孪生”项目,就因人才短缺险些失败,该项目涉及反应釜温度控制、管道压力监测、产品质量预测等多个环节,需要团队同时掌握化工工艺、传感器技术、数据分析等多领域知识,项目初期,团队中只有2人具备跨学科背景,其余成员要么是传统化工工程师(不懂数据分析),要么是IT工程师(不懂化工生产),导致模型搭建与实际需求脱节。
2026年新能源汽车与绿色装修热度持续上升,相关产业迎来新发展 “我们曾试图用‘分工合作’的方式解决,让化工工程师提需求,IT工程师建模型,结果发现双方‘语言不通’——工程师说‘反应釜温度需要控制在±2℃’,IT工程师却问‘这是连续变量还是离散变量’。”该项目负责人张总回忆道,2025年,企业与高校合作开展“数字孪生人才定制培养计划”,通过“理论授课+项目实操+聚类分析工具培训”的方式,在6个月内培养了15名复合型人才,这些人才不仅能用聚类分析识别