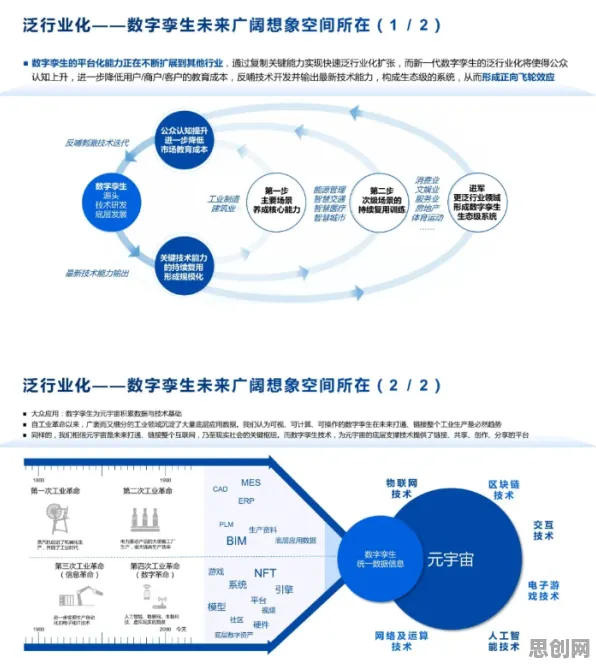
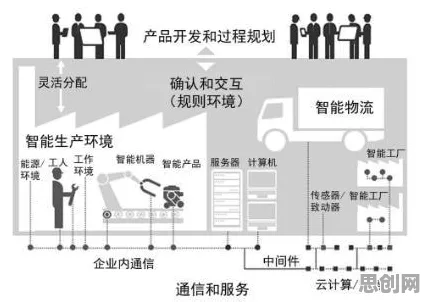
2026年广告营销热度持续上升,相关产业迎来新机遇 在2026年的工业领域,"工业大数据"和"大模型"早已不是新鲜词汇,但围绕它们的误解却像野草般顽固生长,有人认为大模型就是更高级的统计工具,有人觉得工业大数据应用就是堆砌传感器数据,甚至有企业投入巨资后发现"数据越多越混乱",这些认知偏差背后,折射出技术落地时的真实困境——当学术界的理论突破遭遇产业界的复杂场景,当算法的优雅逻辑碰撞工厂的油污与噪音,工业大数据应用究竟该如何突破迷雾?
大模型不是"数据垃圾桶":从特斯拉上海工厂的教训说起
2026年3月,特斯拉上海超级工厂的一起设备故障引发行业热议,该工厂的AI质检系统在检测电池包密封性时,连续三天出现误判,将合格产品标记为缺陷品,导致生产线停摆12小时,事后调查发现,问题出在数据输入环节——为了"提升模型准确性",工程师将过去五年的所有质检数据(包括不同生产线、不同型号、不同工艺参数的数据)全部灌入模型,却忽略了数据分布的差异性。
"这就像让一个刚学会认数字的孩子同时看阿拉伯数字、罗马数字和中文数字,结果只能是混乱。"清华大学工业大数据实验室主任李明教授用生动的比喻解释道,"大模型的核心不是'吃'更多数据,而是'消化'更有价值的数据。"特斯拉最终通过数据清洗,保留了与当前生产线工艺参数匹配的最近半年数据,模型准确率反而从89%提升至97%。
这一案例揭示了工业大数据应用的第一个真相:数据质量比数量更重要,根据工信部2026年发布的《工业大数据发展白皮书》,全国78%的工业大模型项目失败源于数据问题,数据冗余"和"数据偏差"占比最高,在宝钢股份的冷轧车间,工程师们通过建立"数据血缘图谱",追踪每个数据点的来源、加工过程和应用场景,将模型训练时间从72小时缩短至8小时,同时将缺陷检测漏检率降至0.02%。
工业场景的"非线性难题":大模型如何突破经验壁垒
在航空发动机制造领域,一个看似简单的"叶片振动频率预测"问题,曾让GE航空的工程师们困扰多年,传统方法依赖物理模型和经验公式,但当叶片材料从钛合金改为陶瓷基复合材料时,原有模型完全失效,2026年,GE航空与中国科学院自动化研究所合作,开发了基于多模态数据融合的大模型,通过整合材料成分、加工温度、应力分布等127个维度的数据,实现了振动频率的精准预测。
本月绿色防洪抗旱与低碳办公领域迎来新发展,相关应用不断深化 "工业场景的本质是非线性的。"中科院自动化所研究员王伟指出,"一个零件的合格与否,可能取决于0.01毫米的加工误差、5℃的温度波动和0.1秒的操作延迟共同作用的结果。"传统统计方法难以捕捉这种复杂关系,而大模型通过神经网络的层次化结构,能够自动学习数据中的高阶特征。
在三一重工的泵车臂架疲劳寿命预测项目中,这一特性得到了充分验证,工程师们收集了超过10万组臂架应力数据、环境温度数据和操作习惯数据,训练出的模型能够提前30天预测臂架断裂风险,准确率达92%,更关键的是,模型揭示了传统经验公式忽略的"温度-应力耦合效应"——当环境温度低于-10℃时,臂架材料的疲劳极限会下降15%,这一发现直接推动了产品设计的改进。
从"黑箱"到"白盒":可解释性如何改变工业决策
"我们不需要知道模型为什么这么判断,只要它判断得准就行。"——这种观点在2026年的工业界依然存在,但正在被现实改变,在化工行业,一个错误的模型决策可能导致爆炸事故;在电力行业,一次误判可能引发大面积停电,当大模型从辅助工具升级为核心决策系统时,"可解释性"从学术话题变为生存刚需。
2026年5月,中石化镇海炼化分公司发生的一起"虚惊"事件,成为推动工业大模型可解释性研究的标志性案例,当时,基于大模型的裂解炉优化系统建议将某关键参数从85%调整至92%,但系统无法解释调整依据,出于安全考虑,工程师拒绝了这一建议,事后分析发现,模型确实捕捉到了原料中某种微量成分的变化趋势,但因缺乏解释模块,无法将这种复杂关系转化为人类可理解的语言。

"这就像让飞行员按照'神秘指令'操作飞机。"镇海炼化首席信息官陈刚比喻道,"在工业场景中,我们不仅需要'正确答案',更需要'解题过程'。"随后,该公司与浙江大学合作开发了"因果推理模块",通过构建工业知识图谱,将模型输出与物理规律、操作经验进行关联验证,改造后的系统不仅能够给出优化建议,还能生成包含"参数关联路径"和"风险评估矩阵"的决策报告,使工程师对模型建议的接受率从45%提升至82%。
边缘计算与大模型的"化学反应":实时决策的工业实践
在智能制造的愿景中,"实时决策"是关键一环,但当大模型遇到工厂的"最后一公里"——边缘设备时,挑战随之而来:边缘设备的算力有限,无法运行动辄数亿参数的大模型;工业场景对延迟敏感,数据传输到云端再返回可能错过最佳决策窗口。
2026年,华为与海尔合作推出的"工业轻量化大模型"给出了解决方案,在海尔青岛冰箱工厂的注塑车间,部署在边缘设备上的模型仅有500万参数,却能实时分析模具温度、注射压力等8个关键参数,并在0.1秒内调整工艺参数,秘密在于"模型蒸馏"技术——将云端大模型的知识"压缩"到边缘小模型中,同时通过"联邦学习"实现边缘模型与云端模型的协同进化。
"这就像把一个大学教授的知识装进小学生的脑袋。"华为工业互联网解决方案总监张磊解释道,"虽然边缘模型的'记忆力'有限,但它能记住最关键的知识点,并在本地快速应用。"数据显示,该方案使注塑车间的产品合格率从92%提升至98.5%,同时将云端数据传输量减少了90%。
人才缺口:工业大数据应用的"阿喀琉斯之踵"
当技术逐渐成熟,人的因素愈发凸显,2026年,人社部发布的《新职业就业景气报告》显示,"工业数据工程师"缺口达120万人,而高校每年相关毕业生不足5万人,这种供需失衡在中小企业尤为明显——他们既缺乏吸引高端人才的实力,又难以承担高昂的咨询费用。

在苏州工业园区,一家名为"智工互联"的创业公司找到了破局之道,他们开发了"工业大模型训练平台",将数据清洗、特征工程、模型调优等流程封装成可视化模块,即使没有编程基础的工程师也能通过拖拽方式训练模型,该平台在2026年帮助超过200家中小企业建立了自己的工业大模型,平均部署周期从6个月缩短至2周。
"我们不是要培养数据科学家,而是要赋能工业工程师。"智工互联创始人林浩说,"就像Excel让每个人都能处理数据一样,我们的目标是让每个工厂都能拥有自己的AI能力。"这种"低代码"思路正在改变工业大数据应用的生态——据IDC预测,到2027年,70%的工业大模型将由非AI专业人员部署和维护。
从"单点突破"到"系统创新":工业大数据的未来图景
2026年气候变化与健身教练及节能改造热度持续上升,相关产业迎来新机遇 站在2026年的节点回望,工业大数据应用已经走过"数据采集"和"模型训练"的初级阶段,正迈向"系统创新"的新阶段,在比亚迪的深圳工厂,一个覆盖设计、生产、物流、服务的全链条大模型正在运行——它不仅能预测设备故障,还能优化生产排程、设计新产品甚至预测市场需求。
"工业大数据的终极价值,在于重构工业的知识体系。"中国工程院院士、工业大数据联盟理事长周济在2026年世界工业互联网大会上指出,"当每个零件、每台设备、每条产线的数据都被连接和解析,我们就能建立数字孪生世界,实现从'经验驱动'到'数据驱动'的跨越。" 3D打印技术与碳封存及智能制造热度持续上升,相关产业迎来新机遇
这种跨越正在发生,在航天科技集团的火箭发动机装配车间,基于大模型的"数字工友"已经能够独立完成30%的装配任务;在国家电网的特高压变电站,智能巡检机器人通过多模态感知大模型,实现了对设备隐患的"提前感知";在纺织行业,基于大模型的"面料设计大脑"正在颠覆传统的设计流程……
工业大数据应用不是一场"数据竞赛",也不是算法的独角戏,它需要数据科学家与工业工程师的深度协作,需要技术创新与业务场景的精准匹配,更需要从"追求准确率"到"追求业务价值"的思维转变,当误解的迷雾逐渐散去,一个更清晰、更务实的工业大数据应用图景正在展开——在那里,数据不是负担,而是资产;模型不是