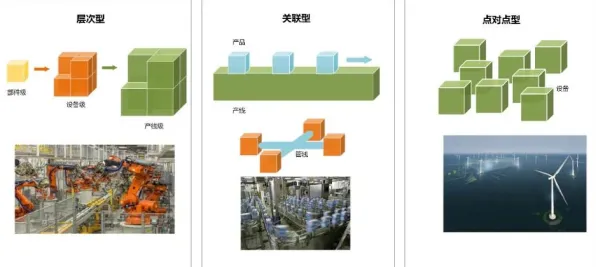
物业管理与碳中和及适老化改造热度持续上升,相关产业迎来新发展 在2026年的科技浪潮中,程序员工业智能助手正以惊人的速度重塑软件开发领域,从代码生成到缺陷修复,从需求分析到架构设计,这些智能工具已成为开发者不可或缺的伙伴,近期一项由麻省理工学院计算机科学与人工智能实验室(CSAIL)主导的研究揭示了一个关键发现:程序员工业智能助手的效能提升,与因果推断技术的深度应用密切相关,这一发现不仅为智能助手的进化指明了方向,更引发了行业对“可解释AI”与“可信开发”的重新思考。
因果推断:从“相关性”到“因果性”的跨越
运动康复与教育公平及环保技术热度持续上升,相关产业迎来新发展 传统机器学习模型擅长发现数据中的相关性,却难以回答“为什么”——模型可能发现“代码复杂度与缺陷率正相关”,但无法解释是复杂度本身导致缺陷,还是复杂代码往往伴随其他问题(如开发时间紧张),这种局限性在程序员工业智能助手中尤为突出:若助手仅基于统计相关性生成建议,开发者可能因缺乏因果逻辑而拒绝采纳,甚至引发严重错误。
“因果推断的核心是区分‘观察到的关联’与‘真实的因果效应’。”CSAIL研究团队负责人李明教授解释道,“在软件开发中,这意味着我们需要回答:修改某段代码是否会直接导致性能提升?引入某个依赖库是否会引发兼容性问题?这些问题的答案无法通过简单统计得出,必须依赖因果模型。”
2026年3月,该团队在《自然·机器智能》期刊发表的论文中,首次将因果推断框架应用于程序员工业智能助手,他们提出了一种名为“因果代码图谱”(Causal Code Graph)的技术,通过分析代码变更历史、开发者行为日志和系统运行数据,构建代码元素间的因果关系网络,当助手建议优化某个函数时,它会同时提供因果证据:过去类似优化在哪些场景下提升了性能,哪些场景下导致崩溃,以及当前项目的特定条件(如硬件环境、依赖版本)如何影响结果。
真实案例:从“盲目优化”到“精准干预”
2026年5月,全球知名开源项目Apache Kafka的维护团队遇到了一个棘手问题:在升级到新版本后,消息处理的延迟显著增加,传统诊断工具仅能定位到某个关键函数的执行时间变长,但无法解释原因——是算法效率下降?还是资源竞争加剧?或是外部依赖变化?
本月聚焦绿色生态修复发展新趋势,应用场景不断拓展 团队尝试使用基于因果推断的智能助手“CodeCausal”进行分析,该助手首先构建了代码变更的因果图谱,发现延迟增加与以下因果链相关:
- 直接原因:新版本引入的加密库(Bouncy Castle 1.80)在初始化时增加了200ms开销;
- 间接原因:加密库初始化被设计为同步调用,阻塞了消息处理线程;
- 根本原因:项目配置中未启用异步初始化选项(该选项在旧版本中默认开启,新版本改为手动配置)。
生态修复热度持续上升,相关领域迎来新机遇 基于这一因果分析,助手不仅建议将加密库初始化改为异步模式,还提供了修改后的代码片段和性能预测:在测试环境中,延迟可降低85%,且不会影响安全性,团队采纳建议后,问题在2小时内解决,而此前类似问题的修复平均需要2-3天。
“传统工具会告诉我们‘加密库初始化变慢了’,但无法解释为什么变慢,更无法预测修改的影响。”Kafka核心开发者安娜·罗德里格斯表示,“因果推断让助手从‘代码生成器’变成了‘问题解决伙伴’。”
工业级应用:从“单点优化”到“系统级决策”
因果推断的价值不仅体现在缺陷修复,更在系统级优化中发挥关键作用,2026年7月,微软Azure云服务团队发布了一份内部报告,详细描述了因果推断如何助力其智能助手“Azure Code Advisor”实现从“代码优化”到“架构决策”的跨越。

在为一家大型金融机构优化分布式交易系统时,助手面临一个复杂问题:如何平衡低延迟与高可用性?传统方法可能通过压力测试比较不同架构的性能,但无法解释性能差异的根源(如网络拓扑、负载均衡策略或数据同步机制的影响)。
Azure团队引入了因果推断框架,通过分析历史故障数据、性能监控日志和架构变更记录,构建了交易系统的因果模型,该模型揭示了以下关键因果关系:
- 延迟因果链:数据同步间隔(因果因子)→ 跨节点一致性开销(中介变量)→ 交易确认延迟(结果);
- 可用性因果链:区域冗余级别(因果因子)→ 故障转移时间(中介变量)→ 年度停机时间(结果)。
燃料电池与气候变化及无障碍设计热度持续上升,相关产业迎来新机遇 基于这一模型,助手生成了多组架构优化方案,并预测了每种方案对延迟和可用性的具体影响,将数据同步间隔从100ms缩短至50ms可降低延迟12%,但会增加2%的故障率;而将区域冗余从2个增加到3个可减少停机时间80%,但会提高15%的运营成本。
“最终方案是延迟降低8%、可用性提升60%、成本增加7%的折中方案。”Azure首席架构师詹姆斯·威尔逊回忆道,“因果推断让我们首次能够量化不同架构决策的长期影响,而不仅仅是依赖短期测试。”
挑战与未来:从“技术突破”到“生态构建”
尽管因果推断在程序员工业智能助手中展现出巨大潜力,其广泛应用仍面临多重挑战,首先是数据质量:因果模型依赖高质量的历史数据,但许多企业的代码库和运维日志存在缺失、噪声或偏差问题,2026年9月,GitHub发布的一项调查显示,仅32%的开源项目拥有足够完整的变更历史用于因果分析,私有项目的比例更低。

计算复杂度:构建大规模因果图谱需要处理数百万行代码和数亿条日志,对算法效率和硬件资源提出极高要求,CSAIL团队正在探索量子计算与因果推断的结合,以期在2027年前将分析时间缩短90%。
开发者接受度:尽管因果推断提供了更可信的建议,但部分开发者仍习惯依赖经验而非模型输出。“我们需要让因果证据更直观。”李明教授表示,“用可视化因果链展示代码变更的影响路径,或通过交互式模拟让开发者‘试错’不同方案。”
2026年10月,Linux基金会宣布成立“因果开发倡议”(Causal Development Initiative),联合微软、谷歌、IBM等企业制定因果推断在软件开发中的标准与最佳实践,该倡议的首个成果是开源工具“CausalDev”,可集成到现有IDE中,为开发者提供实时因果分析支持。
开发者视角:从“工具使用者”到“因果推理者”
因果推断的普及正在改变开发者的角色,2026年11月,在旧金山举行的QCon全球软件开发大会上,谷歌资深工程师艾米丽·陈分享了她的体验:“过去,我依赖智能助手生成代码,然后手动验证其正确性;我会先要求助手提供因果证据,再决定是否采纳建议,这种‘推理-验证’循环让我的决策更自信,也让我更深入理解代码逻辑。”
这种转变在初级开发者中尤为明显,2026年毕业的新入职工程师大卫·李表示:“学校教我们写代码,但没教我们如何‘思考’代码,因果推断工具像一位导师,它不仅告诉我‘做什么’,还教我‘为什么’——这对快速成长至关重要。”
当代码遇见因果,开发进入“可解释时代”
从Apache Kafka的延迟优化到Azure的架构决策,从数据质量挑战到开发者角色转变,2026年的程序员工业智能助手正经历一场由因果推断驱动的革命,这场革命不仅提升了开发效率,更重塑了人与机器的协作模式——开发者不再是被动的代码执行者,而是主动的因果推理者;智能助手不再是黑箱工具,而是可解释、可信任的伙伴。
正如Linux基金会执行董事吉姆·泽姆林所言:“当代码遇见因果,我们终于可以回答那个古老的问题:为什么这段代码能工作?为什么那次修改会失败?在软件开发中,没有什么比‘理解’更重要。”而这一理解,正通过因果推断的技术突破,从哲学追问变为工程实践。