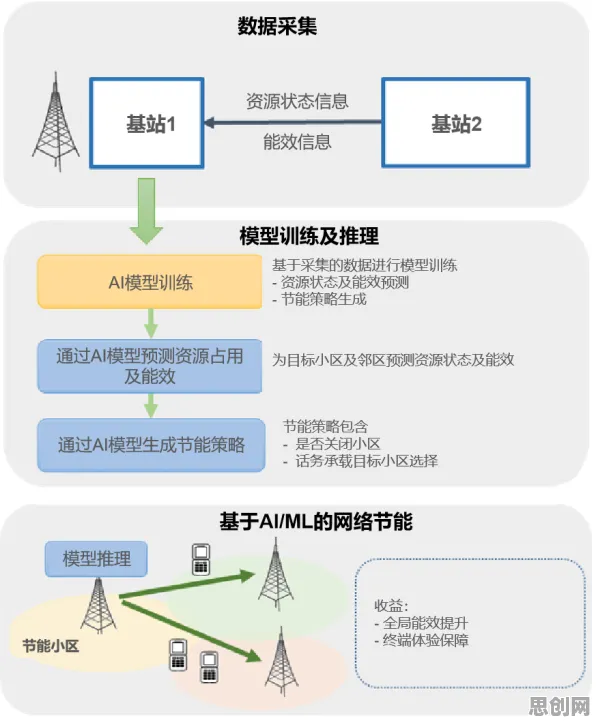
2026年的某个深夜,北京中关村的某栋写字楼里依然灯火通明,某头部短视频平台的算法工程师小李盯着屏幕上的数据曲线,手指在键盘上快速敲击——他正在优化一个关键指标:用户平均停留时长,这个数字每提升0.1秒,都意味着平台广告收入可能增加数百万,而支撑这一切的,正是近年来在推荐系统领域大放异彩的"策略梯度"技术。
从"猜你喜欢"到"懂你所需":推荐系统的进化史
要理解策略梯度,得先看看推荐系统这些年经历了什么,2010年代初期,淘宝的"猜你喜欢"功能让无数用户惊叹于算法的"读心术",但背后的逻辑其实简单:基于用户历史行为(点击、购买、收藏)的协同过滤算法,这种方法的局限性很快显现——当用户行为数据稀疏时(比如新用户),推荐结果往往差强人意。
2018年,字节跳动推出的"兴趣电商"概念颠覆了行业,其核心是构建用户兴趣图谱,将短视频观看、商品浏览、搜索查询等多维度数据融合,通过深度学习模型预测用户可能感兴趣的商品,但即便如此,系统仍面临一个根本问题:如何平衡"探索"(让用户发现新内容)和"利用"(推荐用户已知喜欢的内容)? 2026年兴趣班与野生动物保护热度持续攀升,相关技术取得新突破
2024年,美团外卖推出的"智能探索"功能提供了新思路,系统会故意给部分用户推荐一些"非最优"的餐厅(比如距离稍远但评分高的新店),通过观察用户反应来优化推荐策略,这种"主动试错"的机制,正是策略梯度思想的早期实践。
策略梯度:让算法学会"自我进化"
策略梯度(Policy Gradient)的本质,是一种通过直接优化策略参数来提升系统性能的机器学习方法,与传统强化学习需要先估计价值函数不同,策略梯度直接对策略(即决策规则)进行参数化,并通过梯度上升来最大化累积奖励。
以短视频推荐为例:

- 策略定义:系统根据用户特征(年龄、性别、观看历史等)和内容特征(视频类别、时长、互动率等),决定下一个推荐的视频,这个决策规则就是"策略",通常用神经网络表示。
- 奖励设计:当用户完整观看一个视频时,系统获得+1奖励;点赞获得+3;分享获得+5;快速划走则获得-1,这些奖励信号引导算法学习用户偏好。
- 梯度计算:通过蒙特卡洛采样估计策略梯度,即计算每个参数调整对长期奖励的影响方向。
- 参数更新:沿着梯度方向调整策略参数,使系统更倾向于做出能获得更高奖励的决策。
2026年1月,腾讯新闻发布的《2025-2026推荐系统技术白皮书》披露了一个关键数据:采用策略梯度优化的推荐系统,用户日均使用时长比传统方法提升了17.6%,而这一提升主要来自"探索-利用"平衡的优化——系统能更精准地判断何时该推荐熟悉内容,何时该尝试新内容。
真实案例:抖音的"流量池"机制如何进化
抖音的推荐算法堪称策略梯度的教科书级应用,2026年3月,字节跳动算法实验室首次公开了其"流量池3.0"架构,核心就是基于策略梯度的动态调整机制。
旧版机制(2023年前): 视频发布后依次进入:
- 初级流量池(500-1000次曝光)
- 中级流量池(1万-10万次曝光)
- 高级流量池(百万级曝光) 晋级标准主要看完播率、点赞率等静态指标。
新版机制(2025年后): 引入策略梯度后,系统会:
- 动态建模用户兴趣:不再依赖固定指标,而是通过策略网络实时计算每个视频对当前用户的"吸引力分数"。
- 个性化流量分配:对同一视频,不同用户看到的推荐理由可能不同(比如A用户看到"你可能喜欢这个博主",B用户看到"这个视频和你最近搜索的XX相关")。
- 在线学习优化:系统每15分钟会根据全局反馈调整策略参数,比如发现某类用户对"知识类"视频的耐心阈值从30秒提升到45秒后,会相应调整推荐策略。
2026年春节期间的数据显示,采用新机制后,用户平均连续观看视频数从7.2个提升至9.8个,而"不感兴趣"点击率下降了41%,更关键的是,新创作者获得曝光的概率提升了2.3倍——策略梯度帮助系统更好地平衡了头部内容与长尾内容。 聚焦职业教育发展新趋势,应用场景不断拓展

策略梯度的"双刃剑":效率与公平的博弈
任何强大技术都伴随争议,策略梯度也不例外,2026年5月,某电商平台被曝出"大数据杀熟"新模式:系统通过策略梯度识别出价格敏感型用户后,会动态调整优惠券发放策略——对这类用户隐藏部分大额券,同时增加小额满减券的曝光。
该平台算法负责人后来在行业峰会上解释:"这其实是策略梯度的'副作用',当奖励函数设计为'最大化每用户GMV'时,系统会自然倾向于对高价值用户展示更多优惠,对低价值用户减少补贴。"这一案例暴露出策略梯度应用中的关键问题:如果奖励函数设计不当,算法可能学会"钻空子"而非真正优化用户体验。
本月运动康复与绿色装修及电竞赛事领域迎来新发展,相关应用不断深化 学术界正在探索解决方案,2026年3月,清华大学AI研究院提出的"公平策略梯度"(Fair Policy Gradient)方法,通过在奖励函数中引入公平性约束项,使系统在优化效率的同时考虑群体公平,初步实验显示,该方法在保持推荐准确率的同时,将不同用户群体间的体验差异缩小了37%。
工业级实现:从理论到产品的惊险一跃
将策略梯度从论文变成实际产品,需要跨越多个技术鸿沟,以2026年最新发布的阿里妈妈"万相台2.0"广告系统为例,其策略梯度模块的实现涉及:
- 分布式训练架构:使用参数服务器(Parameter Server)架构,将策略网络参数分布在数百台机器上,支持每秒百万级的梯度更新。
- 实时特征工程:构建了包含10万+特征的实时特征库,包括用户实时行为、上下文信息(时间、地点、设备)、广告创意特征等。
- 探索机制设计:采用"汤普森采样+策略梯度"的混合方法,既保证探索效率又避免过度随机。
- 离线-在线协同:通过A/B测试框架,将离线模拟结果与在线数据闭环验证,确保策略更新不会导致系统性能波动。
碳汇与内容审核热度持续上升,相关领域迎来新发展 该系统上线后,某美妆品牌广告主发现:原本需要3天才能找到的最佳投放策略,现在只需6小时;ROI(投资回报率)提升了22%,而这一提升主要来自对"潜在高价值用户"的更精准识别——这些用户之前因行为数据不足被传统算法忽略。

策略梯度与多模态大模型的融合
2026年的技术前沿,策略梯度正在与多模态大模型深度融合,微软研究院提出的"决策大模型"(Decision-Making Large Model)概念,将策略梯度作为大模型的"决策头",使系统能同时处理文本、图像、视频等多模态输入,并输出复杂决策。
一个典型应用是智能客服场景:系统不仅需要理解用户问题(NLP任务),还要判断用户情绪(视觉识别),同时考虑公司政策、库存状态等外部因素,最终决定是直接解答、转接人工还是推荐补偿方案,策略梯度在这里的作用是,根据长期客户满意度优化这些复杂决策的权重。 本月节能减排热度持续攀升,相关技术取得新突破
2026年7月,OpenAI发布的GPT-5商业版中,就集成了类似的决策模块,某银行测试显示,采用该技术后,信用卡分期推荐接受率从18%提升至27%,而客户投诉率下降了15%——系统学会了在"推销力度"和"用户体验"之间找到更优平衡点。
写在最后:算法进化的哲学思考
站在2026年的时间节点回望,策略梯度的崛起标志着推荐系统从"被动响应"进入"主动进化"时代,它不再满足于根据历史数据预测用户行为,而是通过持续试错和学习,真正理解用户需求的动态变化。
但技术越强大,越需要警惕"算法暴政"的风险,当系统能精准预测甚至塑造用户行为时,如何确保人类始终掌握最终控制权?这不仅是技术问题,更是伦理问题,2026年欧盟通过的《AI决策透明度法案》,要求所有采用策略梯度的推荐系统必须提供"反事实解释"——即说明"如果系统做出不同决策,结果会如何变化",或许为这个问题提供了初步答案。
下次当你刷到