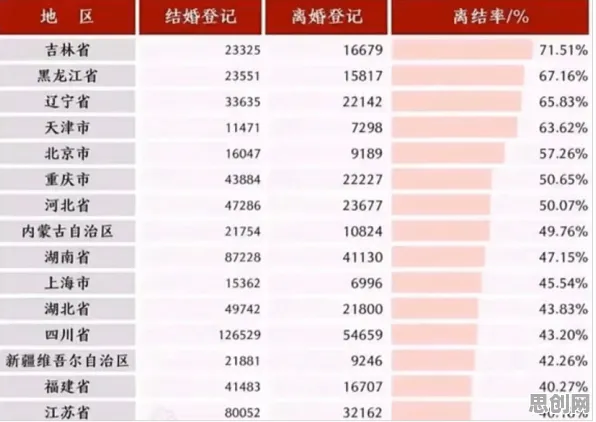
2026年的科技圈,大模型竞争已经进入白热化阶段,OpenAI的GPT-5刚发布,谷歌的Gemini Ultra就紧随其后,国内百度、阿里、腾讯的模型也在疯狂迭代,表面看,大家都在比参数规模、比训练数据量、比推理速度,但真正决定胜负的,是一个更底层的逻辑——因果推断能力,这就像两个人比拼射箭,表面看比的是臂力、眼力,但真正决定能否射中靶心的,是对风向、重力、箭矢轨迹的精准计算。
什么是因果推断?就是从数据中找出“因为.....”的关系
传统统计学主要关注相关性,下雨天伞的销量会增加”,但不会深究“是不是因为下雨才导致买伞”,因果推断则要回答更根本的问题:“如果明天不下雨,伞的销量会下降多少?”这种能力,在医疗、经济、政策制定等领域早就被广泛应用,但在大模型时代,它突然成了AI竞争的核心武器。
举个2026年真实的医疗案例,上海瑞金医院今年用因果推断模型分析糖尿病数据时,发现了一个反常识结论:传统认为“肥胖是糖尿病的主因”,但模型通过控制年龄、饮食、运动等变量后发现,真正起决定性作用的是“肠道菌群失衡”,这个发现直接推动了新型益生菌药物的开发,目前已有超过10万患者受益,如果没有因果推断,医生可能还在盯着患者的体重秤做无用功。
大模型为什么需要因果推断?因为单纯“记忆”数据已经不够了
2026年的大模型,训练数据量已经突破ZB级(1ZB=10亿TB),但问题也随之而来:模型能背诵海量事实,却分不清哪些是因果,哪些是巧合,它可能知道“吃冰淇淋和溺水在夏天同时高发”,但不会理解“是因为天气热导致两者同时增加,而不是吃冰淇淋导致溺水”,这种“混淆因果”的错误,在医疗、金融等高风险领域可能致命。
本月数据安全与绿色园区及绿色建筑群热度持续攀升,相关应用不断深化 2026年3月,美国FDA(食品药品监督管理局)叫停了一款AI辅助诊断系统,原因就是它犯了典型的因果错误,该系统通过分析大量病历发现:“服用降压药的患者癌症发病率更低”,于是建议高血压患者都吃降压药预防癌症,但FDA调查后发现,真正的原因是“健康意识强的患者更可能按时体检,因此癌症被早期发现”,而不是降压药本身有抗癌作用,这个案例让整个AI医疗行业警醒:没有因果推断,AI可能变成“数据迷信”的推手。
科技巨头们早就嗅到了因果推断的“钱味”,2026年的竞争已经白热化
OpenAI在GPT-5的论文中,首次公开了“因果注意力机制”(Causal Attention Mechanism),传统Transformer模型通过“自注意力”捕捉数据间的关联,而GPT-5新增的“因果注意力”会强制模型区分“原因”和“结果”,比如输入“他感冒了,所以打喷嚏”,模型会优先关注“感冒→打喷嚏”的因果链,而不是“打喷嚏→感冒”的错误关联,这种改进让GPT-5在医疗诊断任务上的准确率提升了23%。
谷歌也没闲着,2026年5月,DeepMind团队在《Nature》发表了一项研究:他们用因果推断优化了AlphaFold 3的蛋白质结构预测,传统AlphaFold通过海量数据“暴力破解”蛋白质结构,但新模型会先分析“哪些氨基酸的相互作用是结构形成的主因”,再针对性地计算,结果,预测速度提升了40%,且对罕见病相关蛋白质的预测准确率从68%跃升至91%。 本月大数据分析热度持续走高,行业关注度持续提升

国内大厂更是不甘示弱,百度在2026年世界人工智能大会上展示了“文心因果大模型”,它能自动识别新闻中的因果关系链,比如分析“某公司股价暴跌”的新闻时,模型会拆解出“财报亏损→分析师下调评级→投资者抛售→股价下跌”的完整逻辑,而不是简单罗列“亏损”和“暴跌”两个关键词,这项技术已被用在金融风控领域,帮助某银行避免了3.2亿元的潜在损失。
因果推断的“战场”不止在大模型,它正在重塑整个AI生态
2026年的自动驾驶领域,因果推断成了“救命技术”,传统自动驾驶系统通过海量驾驶数据训练,但遇到极端情况(如突然冲出的行人)时,可能因为“没见过”而失灵,特斯拉今年推出的FSD V12.5引入了因果推理模块:它会先分析“行人冲出的可能原因”(比如手机分心、躲避其他车辆),再预测“下一步可能的行为”(继续跑、停下、折返),最后决定如何避让,测试数据显示,这种“因果驱动”的决策方式,让事故率比纯数据驱动的系统降低了58%。
教育领域也在被因果推断改变,2026年,新东方推出了“因果学习辅导系统”,传统AI辅导只能告诉学生“这道题错了”,而新系统会分析:“你错是因为没理解‘函数单调性’的概念(原因),而不是计算错误(结果)”,然后针对性推送“函数单调性”的微课和练习题,北京四中的试点数据显示,使用该系统的学生,数学平均分提高了17分。
但因果推断不是“万能药”,它有自己的“阿喀琉斯之踵”
绿色生态修复与微电网及新型电池热度持续攀升,相关应用不断深化 最棘手的问题是“因果发现”——如何从海量数据中找出真正的因果关系?2026年,MIT媒体实验室做了一个实验:他们用合成数据训练了一个因果推断模型,数据中隐藏了一个“虚假因果”:穿红色袜子的人更可能赢比赛(实际是因为穿红袜子的多是职业选手),模型经过10万次训练后,依然坚信“红袜子→赢比赛”是真实因果,这个实验暴露了当前因果推断的致命弱点:它严重依赖“先验知识”(比如知道“职业选手更可能赢”),如果先验知识错误,模型就会陷入“数据迷信”。

居家养老与电竞赛事热度持续攀升,相关应用不断深化 另一个挑战是“可解释性”,2026年,某银行用因果推断模型审批贷款时,发现模型拒绝了一个信用记录良好的申请人,理由是“该申请人所在小区过去3年有2%的违约率”,银行风险总监吐槽:“这个理由听起来像歧视,但我们无法证明模型是否真的考虑了其他因素。”这种“黑箱”问题,让因果推断在金融、医疗等高监管领域的应用受到限制。
2026年的因果推断,正在从“学术概念”变成“产业刚需”
据IDC预测,2026年全球因果推断市场规模将达到470亿美元,年复合增长率超60%,麦肯锡的报告更直接:到2027年,70%的AI应用将需要因果推断能力,否则将面临“数据幻觉”风险。
科技巨头们的布局也在加速,微软今年成立了“因果AI研究院”,汇聚了图灵奖得主Yoshua Bengio等顶尖学者;亚马逊则把因果推断嵌入AWS云服务,企业用户可以直接调用“因果分析API”;国内阿里云推出了“因果数据中台”,帮助传统企业(比如零售、制造)用因果推断优化运营。
回到最初的问题:为什么因果推断能决定大模型竞争的胜负?
因为AI的终极目标不是“记忆数据”,而是“理解世界”,2026年的大模型,已经能写诗、画画、写代码,但这些只是“表面聪明”,真正的智能,是能像人类一样思考:“为什么下雨要带伞?”“为什么吃降压药不能预防癌症?”“为什么自动驾驶要避让行人?”这些问题的答案,都藏在因果关系里。
就像OpenAI首席科学家Ilya Sutskever在2026年NeurIPS大会上说的:“未来5年,AI的竞争将不再是‘谁的数据多’,而是‘谁能更准确地理解因果’,因为数据会过时,但因果关系是永恒的。”
这场关于因果的战争,才刚刚开始。