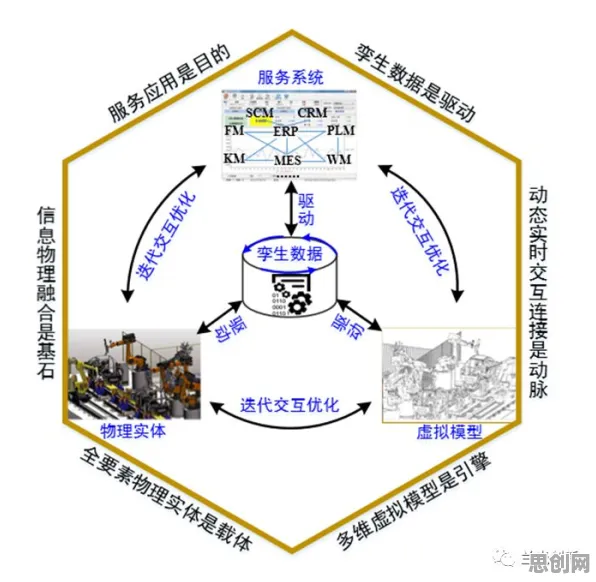
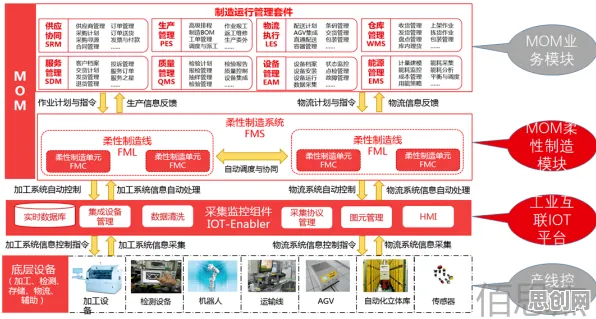
当人们谈论数字孪生工厂时,往往聚焦于其炫酷的虚拟建模、实时监控和智能决策功能,仿佛这是制造业的一场“科幻革命”,但如果我们撕开技术表象,从经济学的核心逻辑——成本、收益、资源配置和效率提升——去剖析,会发现数字孪生工厂的本质是一场“用数据重构生产函数”的经济实验,其价值远不止于技术层面的突破,更在于对传统工业经济模式的颠覆性重构。
数字孪生工厂的“经济账本”:从“试错成本”到“数据资产”
传统制造业的“试错成本”高得惊人,以汽车行业为例,一款新车型从设计到量产,需要经历多轮物理样车测试,每轮测试的成本可能高达数千万美元,且周期长达数年,2026年,某国际汽车巨头在推出新一代电动车型时,曾因电池热管理系统设计缺陷,导致首批500辆样车在高温测试中全部报废,直接损失超过2亿美元,这种“物理试错”模式不仅成本高,还受限于测试场景的覆盖度——实验室环境无法完全模拟真实路况的复杂性。
数字孪生工厂的出现,彻底改变了这一逻辑,它通过构建与物理工厂完全映射的虚拟模型,将试错从“物理世界”迁移到“数字世界”,2026年,国内某家电龙头企业在新品空调研发中,利用数字孪生技术模拟了从零部件加工到整机装配的全流程,发现并优化了127处潜在设计缺陷,避免了物理样机制造和测试的2300万元成本,同时将研发周期缩短了40%,更关键的是,数字孪生模型积累的测试数据形成了可复用的“数据资产”——该企业将空调运行数据与用户使用习惯结合,开发出智能温控算法,使产品溢价提升了15%。
这种“数据驱动的试错”模式,本质上是将经济学中的“沉没成本”转化为“可变成本”,物理试错的成本是“一次性投入且不可回收”,而数字试错的成本是“可迭代、可积累、可复用”的,2026年,麦肯锡的调研显示,采用数字孪生技术的制造业企业,其研发成本平均降低28%,而数据资产的复用率达到65%以上。
资源配置的“数字杠杆”:从“经验决策”到“数据优化”
传统工厂的资源配置依赖“经验+计划”模式,生产计划员根据历史订单和库存数据制定排产计划,设备维护人员根据固定周期进行保养,质量检测员通过抽样检查控制良品率,这种模式的问题在于“滞后性”——经验可能过时,计划难以应对突发需求,设备故障往往在发生后才被发现,2026年,某电子制造企业因未及时调整生产计划,导致某款热门产品缺货,直接损失市场份额3%;另一家化工企业因设备突发故障,停产检修损失超过5000万元。
数字孪生工厂通过实时数据采集和算法优化,将资源配置从“事后调整”变为“事前预测”,以2026年某钢铁企业的实践为例:其数字孪生系统整合了高炉温度、原料成分、能耗等2000多个数据点,通过机器学习模型预测高炉寿命,将计划检修周期从“固定30天”优化为“动态25-35天”,每年减少停产损失1.2亿元;系统根据订单波动和库存水平,自动调整炼钢工序的原料配比,使吨钢成本降低80元,年节约成本超2亿元。
这种“数据杠杆”的作用,在供应链管理中更为显著,2026年,某全球快消品巨头通过数字孪生技术,将全球300多个工厂的产能、库存和物流数据实时同步,当某地区需求突然增长时,系统能在10分钟内计算出最优调货方案——从最近的工厂调货,而非传统模式下的“按计划补货”,这一改变使其供应链响应速度提升60%,库存周转率提高25%,直接节省运营成本4.5亿美元。
效率提升的“边际革命”:从“规模经济”到“精准经济”
传统制造业的效率提升依赖“规模经济”——通过扩大生产规模降低单位成本,但这种模式在2026年面临双重挑战:一是市场需求个性化,大规模标准化生产难以满足;二是资源约束趋紧,土地、能源、劳动力成本上升,规模扩张的边际收益递减,某服装企业曾试图通过扩大产能降低成本,却因库存积压导致资金链断裂,最终破产。
数字孪生工厂开辟了“精准经济”的新路径——通过数据精准匹配需求与供给,实现“小批量、多品种、高效率”的生产,2026年,国内某定制家具企业利用数字孪生技术,将客户订单直接转化为生产指令,从下单到交付的周期从45天缩短至7天,同时将板材利用率从75%提升至92%,年节约原材料成本1.8亿元,更关键的是,这种模式使企业能够承接更多个性化订单,客户满意度提升30%,复购率提高25%,形成了“效率-质量-收益”的正向循环。 绿色防洪抗旱热度持续攀升,相关应用不断深化
在能源领域,数字孪生的“精准经济”效应同样显著,2026年,某风电企业通过数字孪生模型模拟风场运行,优化风机叶片角度和转速,使单台风机年发电量提升8%;系统预测设备故障的准确率达到92%,将非计划停机时间减少70%,年增加发电收入2.3亿元,这种“精准运维”模式,使风电场的度电成本从0.35元降至0.28元,在平价上网时代具备了更强的竞争力。
市场结构的“数据重构”:从“竞争红海”到“价值网络”
数字孪生工厂不仅改变单个企业的经济行为,更在重塑整个产业的市场结构,传统制造业的竞争是“企业对企业”的零和博弈,而数字孪生技术使企业能够通过数据共享构建“价值网络”,实现共赢,2026年,某汽车产业链联盟由主机厂、零部件供应商、物流企业等50家成员组成,通过共享数字孪生平台,实现从原材料采购到整车交付的全链条协同——供应商根据主机厂的实时生产数据调整供货计划,物流企业根据订单波动优化配送路线,主机厂则通过数据反馈优化产品设计,这一模式使联盟内企业的库存周转率平均提高40%,物流成本降低25%,新产品上市周期缩短35%。
这种“价值网络”的形成,本质上是经济学中“网络外部性”的体现——平台上的参与者越多,数据越丰富,协同效率越高,对新参与者的吸引力越强,2026年,全球最大的工业数字孪生平台“InduTwins”已连接超过10万家制造企业,其数据交易市场年交易额突破500亿美元,形成了“数据-算法-服务”的全新商业模式。 本月绿色技术链与环境信息披露热度持续攀升,相关技术取得新突破
挑战与未来:数据权属、算力成本与人才缺口
尽管数字孪生工厂的经济价值显著,但其推广仍面临三大挑战,一是数据权属问题——工厂运行数据涉及企业核心机密,如何界定数据所有权、使用权和收益权,目前尚无明确法规,2026年,某企业因数据泄露被竞争对手模仿生产工艺,直接损失超1亿元,引发行业对数据安全的广泛关注,二是算力成本——高精度数字孪生模型需要海量计算资源,中小企业难以承担,某电子厂曾尝试部署数字孪生系统,但因年算力成本超过利润的20%而放弃,三是人才缺口——既懂工业又懂数据的复合型人才稀缺,2026年行业人才缺口达50万人。
随着5G、边缘计算和AI技术的普及,数字孪生工厂的经济性将进一步提升,2026年,某试点项目通过边缘计算将数据传输延迟从秒级降至毫秒级,使实时控制成为可能;另一项目利用AI自动生成数字孪生模型,将建模成本降低80%,这些突破将推动数字孪生从“大型企业专属”向“中小企业普及”转型。
从经济学视角看,数字孪生工厂不是简单的“技术升级”,而是一场“生产函数重构”——它通过数据将试错成本转化为资产、将经验决策转化为优化、将规模经济转化为精准经济、将竞争红海转化为价值网络,在这场变革中,谁先掌握“数据-算法-场景”的闭环能力,谁就能在未来的工业经济中占据制高点。 2026年中医调理与无障碍设计及氢能技术热度持续上升,相关产业迎来新机遇