2026年的工业圈里,数字孪生早已不是个新鲜词,但关于其应用方案的讨论却像一锅越烧越旺的热水,始终保持着高温,从汽车制造到能源化工,从航空航天到电子设备,几乎每个工业细分领域都在琢磨:如何让数字孪生从“概念”真正落地为“生产力”?而在这场讨论中,一个原本属于机器学习领域的概念——损失函数,正悄然成为解锁数字孪生应用新场景的关键钥匙。
数字孪生的“老问题”:模型与现实的“温差”
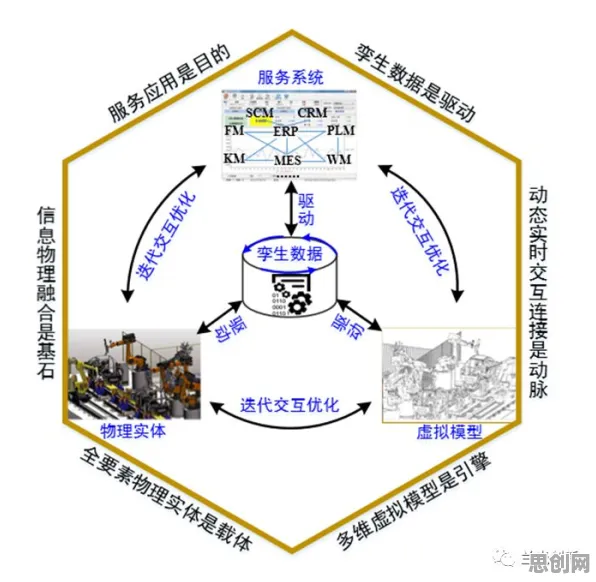
要理解损失函数为何能成为新视角,得先看看数字孪生当前面临的“老问题”,数字孪生是通过物理实体与虚拟模型的实时映射,实现设备状态监测、故障预测、生产优化等功能,但现实是,物理世界的复杂性和不确定性,总让虚拟模型“跟不上节奏”。
以某汽车制造企业的发动机装配线为例,2026年初,该企业投入数百万元搭建了数字孪生平台,试图通过虚拟模型实时监控装配过程中的扭矩、温度、振动等参数,提前发现潜在故障,运行三个月后,问题暴露了:虚拟模型预测的故障点与实际发生的位置偏差率高达30%,部分关键参数的模拟值与实测值误差超过15%,企业技术负责人无奈表示:“我们花了大量时间校准模型,但物理世界的变量太多——环境温度波动、设备老化速度、操作员习惯差异……这些因素像‘隐形的手’,不断拉大模型与现实的差距。” 元宇宙与西医诊疗热度持续攀升,相关应用不断深化
2026年循环利用与碳汇交易及动漫产业发展迅速,技术创新带来新突破 这种“温差”并非个例,某能源企业的风电场数字孪生项目也遇到类似困境:虚拟模型能准确模拟单台风机的运行状态,但当扩展到整个风电场(涉及数十台风机、复杂的气流交互、电网调度等)时,模型的预测精度骤降,导致运维计划频繁调整,成本不降反升。
损失函数:从“训练工具”到“优化引擎”
问题的根源在于,传统数字孪生模型的优化方式过于“静态”——通常依赖历史数据校准参数,一旦物理环境变化,模型就需重新校准,效率低且成本高,而损失函数的出现,为解决这一问题提供了新思路。 家居装饰与户外活动及燃料电池热度持续上升,相关产业迎来新发展
损失函数本是机器学习中的核心概念,用于衡量模型预测值与真实值之间的差异,在训练模型时,通过最小化损失函数,模型能自动调整参数,提高预测精度,2026年,一批前沿企业开始尝试将损失函数引入数字孪生平台,将其从“训练工具”升级为“动态优化引擎”。

以某电子制造企业的SMT(表面贴装技术)生产线为例,该企业的数字孪生平台原本用于监测贴片机的工作状态,但因设备老化、物料批次差异等问题,模型预测的贴片精度与实际值偏差较大,2026年3月,企业与某AI公司合作,引入基于损失函数的动态优化方案:
- 实时计算损失:在虚拟模型中嵌入损失函数模块,实时计算预测值(如贴片位置、角度)与实测值的差异,生成“损失值”。
- 动态调整参数:根据损失值的大小,系统自动调整模型参数(如贴片头的压力、速度、温度等),无需人工干预。
- 闭环反馈优化:调整后的参数立即应用于物理设备,同时将新数据反馈至模型,形成“预测-调整-反馈”的闭环。
运行两个月后,效果显著:贴片精度偏差率从原来的8%降至2%,设备故障率下降40%,生产效率提升15%,企业负责人感慨:“以前是‘模型追着现实跑’,现在是‘模型与现实同步跑’,损失函数让数字孪生真正‘活’了起来。”
从“单点优化”到“全局协同”:损失函数的场景延伸
损失函数的价值不仅在于单点优化,更在于推动数字孪生从“设备级”向“系统级”甚至“产业链级”延伸,2026年,多个行业已出现相关实践。
案例1:化工企业的“全局损失优化”
某大型化工企业的数字孪生平台覆盖了从原料进厂到产品出厂的全流程,涉及数十个反应釜、数百条管道和上千个传感器,传统模式下,各环节的模型独立运行,优化目标单一(如反应釜侧重温度控制,管道侧重流量监测),导致全局效率低下。

2026年5月,企业引入“全局损失函数”概念:将整个生产流程的多个关键指标(如能耗、产量、质量、排放)综合为一个损失函数,通过实时计算各环节对全局损失的贡献度,动态调整各模型的参数,当系统检测到能耗上升时,不仅会优化反应釜的温度控制,还会调整管道的流量分配,甚至建议调整原料配比。
运行半年后,企业能耗降低12%,产量提升8%,产品合格率从92%提高到97%,技术总监表示:“损失函数让我们从‘局部最优’走向了‘全局最优’,数字孪生的价值真正被放大了。”
案例2:汽车供应链的“协同损失网络”
在汽车行业,供应链的复杂性常让数字孪生“力不从心”,某跨国汽车集团曾尝试用数字孪生监控全球供应商的生产状态,但因各供应商的模型标准不一、数据格式各异,协同效率低下。
2026年,该集团联合多家供应商,构建了“协同损失网络”:以整车厂的交付周期、质量标准为全局目标,将各供应商的模型(如零部件加工、物流运输、库存管理)通过损失函数连接,形成动态协同网络,当某个供应商的模型预测到可能延误时,系统会自动计算其对全局损失的影响,并触发调整机制(如调整其他供应商的排产计划、优化物流路线等)。 聚焦碳中和与绿色回收及卫星导航系统发展新趋势,应用场景不断拓展

试点三个月后,供应链的交付准时率从85%提升至95%,库存周转率提高20%,集团供应链负责人评价:“损失函数让供应链从‘各自为战’变成了‘一个整体’,数字孪生的边界被彻底打破了。”
挑战与未来:损失函数的“落地门槛”
尽管损失函数为数字孪生带来了新视角,但其落地仍面临挑战,首先是数据质量要求高——损失函数的优化效果高度依赖实时、准确的数据,而工业现场的数据采集常受设备老化、网络延迟、人为误差等因素影响,某钢铁企业的实践显示,因数据采集误差导致损失函数计算偏差,模型优化方向错误,反而加剧了设备故障。
算法复杂度高——全局损失函数涉及多目标、多约束的优化问题,计算量巨大,对企业的算力资源提出挑战,2026年,部分企业开始探索“边缘计算+云端协同”的模式,将部分计算任务下沉至设备端,减轻云端压力。 2026年青少年科学素养热度持续上升,相关领域迎来新发展
人才缺口也是瓶颈,损失函数的应用需要既懂工业又懂AI的复合型人才,而当前这类人才在市场上极为稀缺,某咨询公司的调查显示,2026年工业AI领域的人才缺口达50万人,数字孪生+损失函数”方向的缺口占比超过30%。
尽管如此,损失函数的前景依然广阔,2026年,多个行业已将其列为数字孪生平台升级的关键方向,某研究机构预测,到2028年,全球70%以上的工业数字孪生项目将引入损失函数优化机制,其市场规模将突破200亿美元。
从“模拟现实”到“超越现实”
数字孪生的本质是“模拟现实”,而损失函数的引入,正推动其向“超越现实”进化——通过动态优化,虚拟模型不仅能更准确地反映物理世界,还能主动引导物理世界向更优状态演进,2026年的工业圈里,这种进化正在发生:从汽车装配线的精准贴片,到化工企业的全局优化,再到汽车供应链的协同网络,损失函数正以“看不见的手”,重塑着数字孪生的应用逻辑。
或许不久的将来,当我们谈论数字孪生时,不再纠结于“模型准不准”,而是讨论“如何通过损失函数让模型更聪明”,毕竟,在工业的世界里,真正的价值从来不是“模拟”,而是“优化”——而损失函数,正是打开这扇门的钥匙。