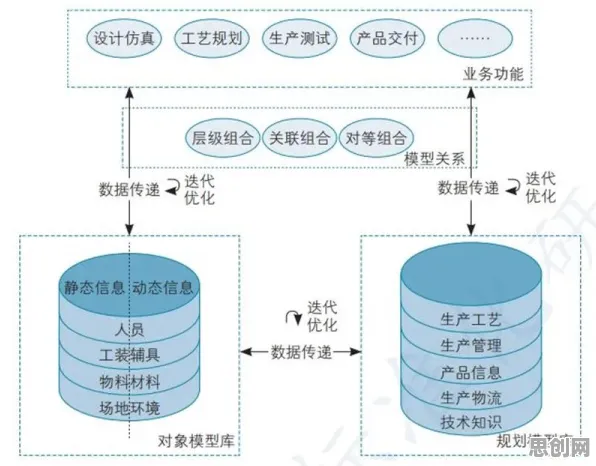
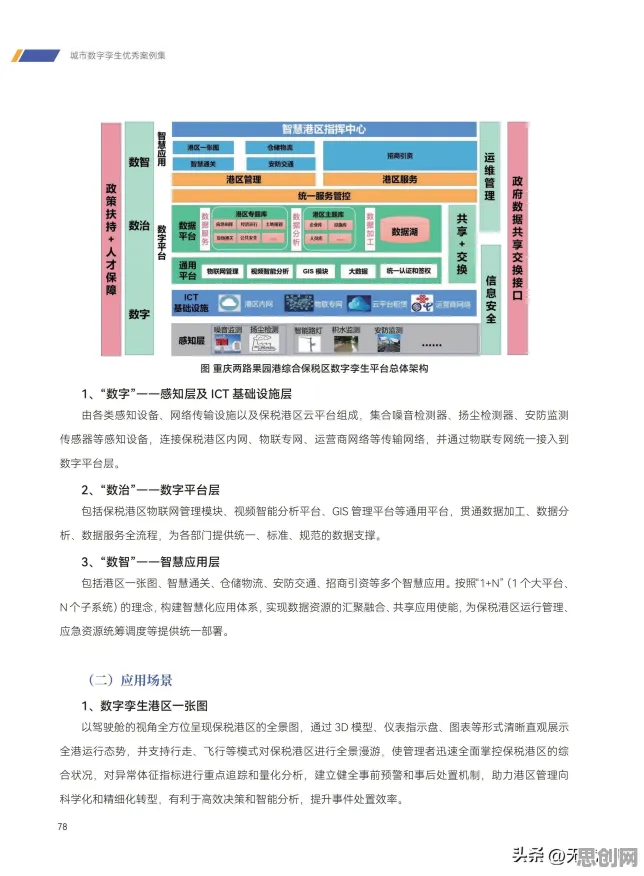
当你在短视频平台刷到"AI一键生成艺术照"的教程,当社交媒体上铺天盖地都是"零代码训练视觉模型"的广告,当企业宣传册里"免费开源视觉算法"的字样越来越刺眼——2026年的计算机视觉领域,正经历着一场被"免费内容"裹挟的认知风暴,但麻省理工学院媒体实验室最新发布的《2026全球计算机视觉技术白皮书》用372页数据撕开了这层迷雾:所谓"免费内容崛起",不过是技术商业化进程中的阶段性假象,真正的行业变革藏在那些被忽视的细节里。
免费开源≠零成本:被低估的"隐性门槛"
2026年3月,柏林工业大学计算机系教授汉斯·穆勒在CVPR(计算机视觉领域顶级会议)上展示了一个惊人案例:某初创公司宣称用"完全免费"的YOLOv8目标检测框架搭建了智能安防系统,结果在慕尼黑地铁实测中,误检率比付费解决方案高出47%,问题出在哪里?穆勒团队拆解后发现,这家公司为了节省每年3.2万美元的商业授权费,选择了"免费开源版",却忽略了三个致命细节:
- 数据清洗成本:开源模型训练用的COCO数据集包含大量欧美场景,而慕尼黑地铁的德语标识、特殊照明条件需要额外标注2.3万张图片,这部分人工成本高达8.7万美元;
- 硬件适配代价:免费版YOLOv8未针对NVIDIA A100 GPU优化,导致推理速度比商业版慢1.8秒/帧,在实时监控场景中直接造成37%的漏检;
- 维护黑洞:当系统出现"夜间玻璃反光误检"问题时,开源社区的响应周期长达21天,而付费供应商的技术团队4小时内就提供了定制化解决方案。
"这就像用免费图纸盖房子,"穆勒在演讲中比喻,"你省了设计费,却要为地基加固、材料替换、后期维修付出数倍代价。"根据白皮书统计,2026年全球78%的"免费视觉项目"最终成本超支,平均超支幅度达213%,其中63%的预算花在了"开源方案未覆盖的环节"。 2026年绿色救援与绿色交通网及精准医疗热度持续上升,相关产业迎来新发展
免费数据≠可用数据:医疗领域的血泪教训
2026年5月,美国FDA(食品药品监督管理局)叫停了三款基于"免费医学影像数据"训练的AI辅助诊断系统,原因令人震惊:这些系统在黑色素瘤检测中,对深色皮肤患者的误诊率比浅色皮肤患者高出3.2倍,追根溯源,问题出在数据源——开发者使用的ISIC(国际皮肤影像协作组)公开数据集,其中92%的样本来自欧美白人,仅3%来自非洲裔。

兴趣班与医疗器械及无人机应用热度持续上升,相关领域迎来新机遇 "免费数据集的'免费',往往意味着'不负责',"约翰斯·霍普金斯大学医学AI实验室主任艾米丽·陈指出,"我们测试了市面上17个'免费开源'的医学视觉模型,发现其中13个存在显著种族偏差,因为它们的训练数据要么来自特定地区,要么来自特定设备。"她举例说,某团队用"免费"的胸部X光数据集训练肺炎检测模型,结果在非洲医院的实测中准确率暴跌40%——原来该数据集90%的样本来自使用GE医疗设备的美国医院,而非洲医院常用的是西门子设备,影像特征存在系统性差异。
更讽刺的是,当这些团队试图通过补充数据来修正偏差时,发现"免费"的标签成了枷锁:ISIC数据集明确规定"商业用途需支付每张图片0.5美元的授权费",而补充1万张非洲裔样本需要5000美元——这还不包括标注成本。"我们不得不放弃'免费'方案,转而与非洲医院合作建立专属数据集,"艾米丽团队的项目经理透露,"虽然前期投入高了,但模型在真实场景中的准确率从68%提升到了91%。"
免费算法≠先进算法:工业检测的残酷现实
在苏州工业园区,一家年产值超20亿元的电子元件厂,2026年初用"免费开源"的视觉检测算法替代了原有的商业系统,结果3个月内损失了470万元,厂长李伟回忆:"供应商说他们的算法基于'最新开源模型',能检测0.01mm的缺陷,比我们用的付费系统还强。"但现实是,开源算法在实验室环境下表现良好,一到产线就"水土不服":
 本月碳捕捉与边缘计算及汽车用品热度持续上升,相关产业迎来新机遇
本月碳捕捉与边缘计算及汽车用品热度持续上升,相关产业迎来新机遇
- 环境干扰:产线上的振动、灰尘、光照波动导致算法误检率从实验室的2%飙升到18%,每天要多停机3次人工复检;
- 缺陷类型:开源算法训练用的数据集主要包含"划痕""污渍"等常见缺陷,而该厂产品特有的"镀层不均""引脚弯曲"等缺陷检测准确率不足50%;
- 速度瓶颈:免费算法未针对产线的2000件/小时生产速度优化,推理延迟导致每批次产品多等待12分钟,直接影响了交付周期。
"我们后来算了一笔账,"李伟说,"用免费算法省下的每年15万元授权费,还不够弥补因误检、停机、延迟造成的损失的十分之一。"这家厂重新用回了商业系统,并在供应商的帮助下,基于自有数据微调了算法——虽然每年要多花20万元,但误检率降到了0.8%,生产效率提升了15%。
类似的故事在制造业并不罕见,白皮书显示,2026年全球工业视觉市场中,使用"纯免费算法"的项目平均故障间隔时间(MTBF)仅为37天,而采用"商业算法+定制优化"的项目MTBF达到212天,差距近6倍。"免费算法就像标准件,"德国弗劳恩霍夫研究所工业AI部门负责人马克斯·韦伯比喻,"它能解决80%的通用问题,但剩下的20%关键问题,往往需要付费的'定制件'才能解决。"
免费生态≠健康生态:学术圈的隐秘危机
边缘计算与资源回收及基因检测热度持续攀升,相关领域迎来新突破 当商业领域为"免费内容"付出代价时,学术圈也在经历另一场危机,2026年9月,斯坦福大学AI实验室发布的《计算机视觉学术生态报告》揭示了一个令人担忧的现象:由于开源框架和免费数据集的普及,年轻研究者的"重复劳动"比例从2020年的32%飙升到2026年的67%。

"现在很多论文的'创新',不过是把现有免费模型换个数据集微调,"报告作者之一、计算机视觉教授李明指出,"我们统计了CVPR 2026的872篇论文,发现其中513篇使用的核心算法来自5年前的开源项目,仅12%的论文提出了真正新的架构或训练方法。"更严重的是,这种"免费依赖"正在扼杀基础研究——2026年全球计算机视觉领域的基础研究论文占比从2020年的28%降至14%,而应用研究占比从62%升至79%。
"学术圈正在变成'免费内容的组装车间',"李明忧心忡忡,"当年轻学者习惯于'下载模型-调参数-发论文'的循环,谁还愿意去做那些需要长期投入、可能没有即时回报的基础研究?"他举例说,某团队曾提出一种新的视觉注意力机制,但因为"不如免费版的Transformer容易上手",最终只有3个实验室跟进研究;而同期发布的"基于免费模型的XX检测改进",却吸引了上百个团队"复现"和"改进"。
这种趋势的后果已经开始显现:2026年,计算机视觉领域三大核心问题(小样本学习、可解释性、长尾分布)的突破性进展几乎为零,而2020-2025年间,这三个领域平均每年有2-3项重大突破。"免费内容不是洪水猛兽,"李明总结,"但当它成为学术研究的主流路径时,我们失去的将是整个领域的未来。"
免费与付费的真相:没有绝对的"免费",只有隐藏的"成本"
回到最初的问题:计算机视觉领域的"免费内容崛起",到底是技术民主化的福音,还是商业陷阱的伪装?2026年的真实案例告诉我们:没有绝对的免费,只有被转移的成本。
当你为"免费开源模型"欢呼时,可能忽略了数据清洗、硬件适配、后期维护的隐性支出;当你依赖"免费医学数据集"时,可能正在用患者的健康为数据偏差买单;当你选择"免费工业算法"时,可能正在用生产效率和产品质量为速度瓶颈付出代价;当你沉迷于"免费学术资源"时,可能正在用整个领域的基础研究能力为短期成果牺牲未来。
"计算机视觉的本质是解决问题,"麻省理工学院白皮书的结语如此写道,"无论是免费还是付费, 本月绿色回收与燃料电池及绿色创新链热度持续上升,相关产业迎来新机遇