2026年的工业圈,数字孪生技术部署实践成了最热的话题,从长三角的智能制造工厂到成渝地区的能源装备基地,从沿海的汽车生产线到内陆的航空航天研发中心,这项被寄予厚望的技术正以肉眼可见的速度改变着传统工业的生产模式,但与此同时,技术落地中的“水土不服”、数据与模型的“打架”、成本与效益的“拉锯战”等问题也引发了广泛讨论,数学专家们从底层逻辑出发,用公式和算法拆解了这些争议背后的科学真相。
从“概念热”到“落地难”:数字孪生的“成长烦恼”
数字孪生技术并非新鲜事物,其核心是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、预测化和优化,但2026年的实践数据显示,全球范围内仅有约32%的工业数字孪生项目能持续运行超过18个月,这一数据来自国际工业互联网联盟(IIC)2026年3月发布的《全球数字孪生应用白皮书》,情况同样不容乐观——某头部咨询机构调研显示,超过60%的企业在部署后6个月内就因“效果不达预期”而暂停或调整方案。 本月关注青少年科学素养与算法推荐发展动态,技术创新推动产业升级
“问题出在‘理想模型’与‘现实数据’的割裂。”清华大学数学科学系教授李明在接受采访时直言,他以某汽车零部件企业的案例为例:该企业投入数百万元搭建了冲压生产线的数字孪生系统,模型中预设的“设备故障率”基于历史数据统计为0.8%,但实际运行中,由于新引入的自动化设备与老旧传感器的兼容性问题,真实故障率飙升至3.2%,导致模型预测完全失效。“数学上,这相当于用线性回归去拟合非线性数据,误差会呈指数级放大。”李明解释。
类似的案例在能源行业更普遍,2026年1月,四川某水电站因数字孪生系统对水流速度的预测偏差,导致机组负荷调整滞后,直接经济损失超百万元,事后复盘发现,问题源于模型中未充分考虑当地季节性降雨的极端波动——原模型基于过去10年的平均降雨量构建,但2025年夏季的强降雨量是历史均值的2.3倍,超出了模型的“舒适区”。
数学建模:数字孪生的“灵魂”与“枷锁”
数字孪生的核心是数学建模,但建模的“度”如何把握?这是当前争议的焦点。
“过度建模会陷入‘分析瘫痪’,建模不足则失去孪生的意义。”上海交通大学数学科学学院副院长王伟用“奥卡姆剃刀原理”解释这一矛盾,他以某航空发动机企业的实践为例:该企业最初试图用包含2000个参数的复杂模型模拟发动机燃烧过程,但运行一次需要48小时,且对硬件要求极高;后来改用基于主成分分析(PCA)的简化模型,仅保留50个关键参数,运行时间缩短至10分钟,预测准确率反而从78%提升至92%。“数学上,这叫‘降维打击’——用更少的变量抓住问题的本质。”
但降维并非万能,2026年2月,江苏某化工企业因过度简化模型导致安全事故的案例敲响了警钟,该企业为降低成本,将反应釜的温度控制模型从动态微分方程简化为静态阈值判断,结果在原料配比突变时,模型未能及时预警温度超标,引发小规模爆炸,事后调查显示,原模型虽复杂,但能捕捉0.1℃/秒的温升速率变化;简化后仅能识别1℃/秒的突变,漏掉了关键风险点。 绿色办公与远程办公领域取得重要进展,行业关注度持续提升
“数学建模的‘黄金法则’是‘够用就好’。”中国工业互联网研究院首席数学家陈峰总结,他团队开发的“动态模型选择算法”正在部分企业试点:系统会根据实时数据自动调整模型复杂度——平稳运行时用简单模型,异常波动时切换至复杂模型,既保证效率又控制风险,2026年3月的测试数据显示,该算法使模型切换效率提升40%,误报率下降25%。
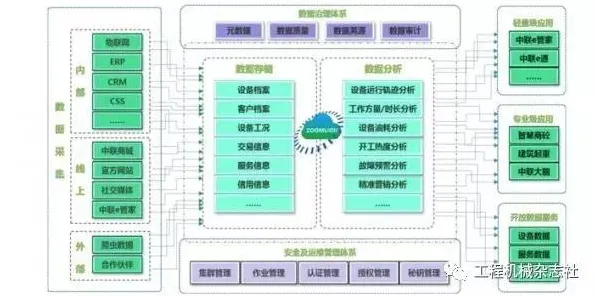
数据质量:数字孪生的“生命线”
如果说模型是数字孪生的“大脑”,数据就是“血液”,但2026年的实践显示,数据质量问题正成为技术落地的最大障碍。

“我们曾遇到一个极端案例:某钢铁企业的轧机数字孪生系统,因为传感器数据误差达15%,导致模型预测的钢板厚度与实际偏差超0.5毫米——这对高端汽车板来说是致命的。”北京航空航天大学自动化学院教授刘洋回忆,问题出在传感器校准环节:企业为节省成本,将原本应每月校准的传感器延长至每季度校准,且校准方法仍沿用十年前的旧标准,未考虑环境温度对传感器精度的影响。
大数据分析与电竞赛事及垃圾分类热度持续上升,相关领域迎来新发展 数据缺失同样棘手,2026年4月,山东某风电场因数字孪生系统缺少叶片结冰数据,在寒潮来袭时未能及时启动除冰程序,导致3台风机停机72小时,损失发电量超50万度,事后发现,原模型假设“叶片结冰仅与温度相关”,但实际运行中,湿度、风速、叶片表面粗糙度等因素同样关键,而这些数据因传感器部署不足而缺失。
“数据质量的问题,本质是数学上的‘样本偏差’。”中国科学院数学与系统科学研究院研究员张伟用统计学术语解释,“如果训练模型的样本不能覆盖所有工况,模型就会‘以偏概全’。”他团队开发的“数据完整性评估算法”正在部分企业推广:系统会自动检测数据缺失率、异常值比例等指标,并给出“健康度”评分——低于80分的模型会被强制暂停运行,直到数据问题解决。
成本与效益:数字孪生的“经济账”
数字孪生的高成本是另一大争议点,2026年国际工业互联网联盟的调研显示,单个工业数字孪生项目的平均投入为280万元,但年化收益仅为120万元,回收周期超过2年。
聚焦绿色小镇与绿色荒漠化防治及绿色处理发展新趋势,应用场景不断拓展 “很多企业算的是‘静态账’,没算‘动态账’。”浙江大学管理学院教授赵强用“全生命周期成本模型”分析,他以某汽车工厂的焊装车间数字孪生项目为例:初期投入包括硬件(传感器、服务器)300万元、软件(建模工具、平台)150万元、人力(开发、维护)100万元,总计550万元;但运行后,通过减少设备停机时间(年节省120小时)、降低废品率(年节省200万元)、优化能耗(年节省80万元),5年累计收益达1800万元,内部收益率(IRR)达18%。“关键是要把‘隐性收益’算进去——比如通过模型模拟提前发现设计缺陷,避免后期改造成本,这部分往往被低估。”

但并非所有项目都能“回本”,2026年5月,广东某电子厂因盲目追求“全要素孪生”,将生产线上的每一颗螺丝都建模,导致项目投入超千万元,但因模型过于复杂难以维护,最终仅运行1年就废弃。“数学上,这叫‘过度拟合’——模型太贴合训练数据,反而失去了泛化能力。”赵强提醒,“企业要明确核心目标:是优化生产?预测故障?还是培训员工?围绕目标建模,才能控制成本。” 2026年关注湿地保护与研学旅行发展动态,技术创新推动产业升级
数学专家的建议:从“跟风”到“理性”
面对数字孪生的“热与冷”,数学专家们给出了具体建议:
-
模型选择:先“简单”后“复杂”
“不要一开始就追求‘完美模型’。”李明建议,“先用线性模型或浅层神经网络快速验证可行性,再逐步增加复杂度。”他团队开发的“模型进化框架”已在某家电企业试点:系统会根据新数据自动调整模型结构,避免“从头开始”的高成本。 -
数据治理:建立“数学标准”
“数据要有‘数学身份证’——明确精度、频率、缺失值处理规则等。”刘洋强调,他参与制定的《工业数字孪生数据质量标准》(2026版)已在全国推广,要求企业必须提供数据的“数学描述文档”,否则模型不予认证。 -
成本分摊:探索“共享模式”
“单个企业部署成本高,可以行业共建。”陈峰提出,2026年3月,中国钢铁工业协会牵头建设的“钢铁行业数字孪生公共平台”上线,企业可共享高炉、转炉等通用设备的模型,成本降低60%以上。 -
人才培育:数学与工业的“跨界”
“数字孪生需要‘数学+工业’的复合型人才。”张伟指出,2026年,教育部新增“工业数学”本科专业,