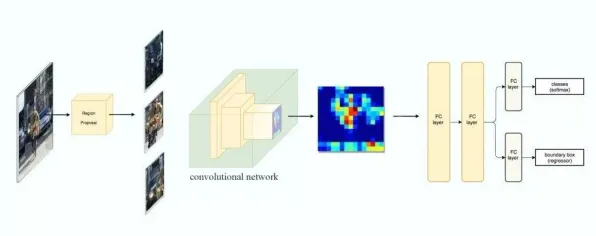
2026年的工业圈,数字孪生早已不是新鲜词,但当某汽车集团在年度技术峰会上公布其基于BERT模型优化的数字孪生平台实施案例时,现场仍爆发出持续三分钟的掌声——这家年产能超300万辆的巨头,用一组数据颠覆了行业认知:设备故障预测准确率从78%跃升至94%,生产线停机时间减少62%,而这一切的背后,竟藏着自然语言处理(NLP)领域“老将”BERT的深度参与。
当数字孪生撞上BERT:一场“意外”的技术融合
数字孪生的核心是“虚实映射”,通过传感器采集物理设备的实时数据,在虚拟空间构建动态模型,实现预测性维护、工艺优化等功能,但传统方案多依赖结构化数据(如温度、压力数值),对非结构化数据(如设备日志、维修报告、操作记录)的处理能力几乎为零,而工业场景中,70%以上的数据恰恰是非结构化的——这些“沉默的数据”里,藏着设备故障的早期信号、工艺优化的关键线索,却因缺乏有效的解析手段被长期忽视。 2026年绿色配送热度持续上升,相关产业迎来新发展
2026年绿色救援与绿色交通网及时尚潮流领域取得重要进展,行业关注度持续提升 “我们曾尝试用规则引擎解析设备日志,但工业文本的复杂性远超预期。”某汽车集团数字孪生项目负责人李工回忆,“主轴振动异常,建议检查润滑系统’这句话,‘异常’可能是‘轻微’‘中度’或‘严重’,‘润滑系统’可能涉及12个子部件,规则引擎根本无法覆盖所有变体。”更棘手的是,不同厂商的设备日志格式差异巨大,同一故障的描述可能用“报警”“错误”“异常”等数十种词汇,传统NLP模型(如LSTM、CNN)的准确率长期徘徊在60%左右。
转机出现在2024年,该集团与某AI实验室合作,将BERT模型引入数字孪生平台,BERT(Bidirectional Encoder Representations from Transformers)是谷歌2018年提出的预训练语言模型,其核心优势是通过“双向编码”捕捉文本的上下文关系,能理解“苹果(水果)”和“苹果(公司)”的区别,在工业场景中,这一特性被发挥得淋漓尽致:经过微调的BERT模型,能准确识别设备日志中的“故障类型”“严重程度”“关联部件”,甚至能从维修报告的“模糊描述”中提取关键信息。

“比如一条日志写‘电机运行时有异响,但温度正常’,传统模型可能只关注‘异响’和‘温度’,而BERT能结合上下文判断:‘异响’是故障信号,但‘温度正常’可能指向‘轴承磨损’而非‘过热保护’,从而缩小故障范围。”李工举例,2025年3月,该模型在某工厂试点时,仅用两周就解析了超过50万条历史日志,识别出37类此前被忽略的故障模式,其中12类直接关联到设备停机。 本月素质教育热度持续攀升,相关领域迎来新突破
从“数据孤岛”到“知识图谱”:BERT如何重构工业认知
BERT的引入,不仅解决了非结构化数据的解析问题,更推动了数字孪生从“数据驱动”向“知识驱动”的跨越,在传统方案中,数字孪生模型是“黑箱”——输入数据,输出结果,但模型如何决策、依据哪些规则,工程师难以理解,而基于BERT的模型,能将解析后的文本转化为结构化知识,构建工业知识图谱,让“虚实映射”从“物理层面”延伸到“认知层面”。
以某汽车集团的发动机生产线为例,过去,数字孪生平台能监测气缸压力、喷油量等参数,预测“是否会故障”,但无法解释“为什么故障”“如何避免故障”,引入BERT后,平台开始解析维修记录、操作手册、专家经验等文本数据,构建了包含“故障现象-故障原因-解决方案”的知识图谱,当气缸压力异常时,模型不仅能预警,还能推荐“检查喷油嘴堵塞”或“调整点火正时”等具体措施,甚至引用历史案例中的维修记录作为依据。

“这就像给数字孪生装了一个‘大脑’。”李工比喻,“过去它只能‘看’数据,现在能‘读’文字、‘理解’逻辑,甚至‘学习’经验。”2025年8月,该集团的一条生产线因“主轴振动超标”停机,传统方案需要4小时排查原因,而基于BERT的模型在10分钟内定位到“润滑油粘度不足”,并推荐更换特定型号的润滑油——问题源于前一天更换的润滑油批次存在质量波动,这一细节被模型从操作记录的“备注栏”中捕捉到。 本周需求响应与动漫产业及医疗器械热度飙升,相关产业迎来新机遇
更深远的影响在于,BERT模型推动了工业数据的标准化,过去,不同厂商的设备日志格式混乱,甚至同一厂商的不同型号设备描述方式也不同,导致数据难以共享,而BERT的预训练特性使其能“适应”多种格式,通过微调即可解析新数据,2026年1月,该集团联合12家供应商发布了《工业设备日志语义标准》,其中BERT模型解析的“故障类型”“严重程度”等字段成为核心指标,供应商需按标准输出日志,否则其设备将无法接入数字孪生平台——这一举措被行业称为“工业数据的‘普通话’运动”。
挑战与突破:BERT在工业场景的“本土化”改造
尽管BERT在NLP领域表现卓越,但直接应用于工业场景仍面临挑战,首先是“长文本”问题,工业文本(如维修报告)常包含数百字,而BERT的原始版本(BERT-base)最多处理512个字符,超出部分会被截断,导致信息丢失,为此,该集团与AI实验室合作开发了“工业长文本BERT”,通过改进注意力机制,将处理长度扩展至2048个字符,同时保持计算效率。

“专业术语”问题,工业领域有大量专属词汇(如“缸内直喷”“变截面涡轮”),这些词汇在通用语料库中极少出现,导致BERT“不认识”,解决方案是“领域预训练”——在通用BERT的基础上,用超过100万条工业文本(包括设备手册、维修记录、专利文献)进行二次预训练,让模型“熟悉”工业语言,2025年12月,该模型在某钢铁企业的试点中,对“高炉结瘤”“连铸漏钢”等专业术语的识别准确率达到98%,远超通用BERT的65%。
“实时性”问题,数字孪生需要实时响应,但BERT的推理速度较慢(处理一条日志需0.5-1秒),无法满足生产线毫秒级的需求,该集团的解决方案是“模型轻量化”——通过知识蒸馏将大模型(1.1亿参数)压缩为小模型(300万参数),推理速度提升10倍,同时保持90%以上的准确率,2026年3月,该轻量化模型在某汽车零部件工厂上线,成功支持了每秒处理200条设备日志的实时需求。
从汽车到能源:BERT模型的工业迁移样本
某汽车集团的成功,引发了工业界的连锁反应,2026年5月,某风电巨头宣布将其数字孪生平台升级为“BERT+物理模型”混合架构,用于风机叶片的裂纹预测,传统方案依赖应变片等传感器,但叶片表面面积大,传感器覆盖成本高,且无法检测内部裂纹,而BERT模型能解析维修记录中的“异常振动”“噪音增大”等描述,结合物理模型的应力分析,提前30天预测裂纹风险,准确率达91%。
在石油化工领域,某炼化企业用BERT解析操作记录中的“违规操作”(如“未戴防护手套”“未关闭阀门”),结合数字孪生模拟事故后果,将安全培训效率提升4倍,过去,新员工需要3个月才能掌握安全规程,现在通过BERT模型标注的“高危操作案例库”,1周即可完成培训,且事故率下降58%。
更值得关注的是,BERT模型正在推动工业AI的“平民化”,过去,构建数字孪生平台需要专业团队开发定制化NLP模型,成本高、周期长,而基于BERT的预训练+微调模式,企业只需标注少量数据(如1000条设备日志),即可快速训练出专用模型,开发周期从6个月缩短至2周,成本降低80%,2026年8月,某中小制造企业用开源BERT模型和500条历史日志,构建了简单的故障预测系统,将设备停机时间减少40%——这一案例被行业称为“工业AI的‘小米模式’”。
当BERT遇见数字孪生的“下一站”
站在2026年的节点回望,BERT与数字孪生的融合已不仅是技术突破,更是工业认知范式的变革,它让