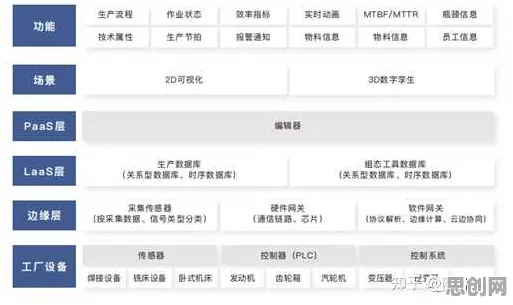
在2026年的云计算江湖里,微服务架构早已不是新鲜话题,从互联网巨头到传统企业,几乎所有数字化转型的企业都在用微服务拆解系统、提升效率,但当大家忙着用Kubernetes调度容器、用Service Mesh管理流量时,一个隐藏在底层的技术矛盾正逐渐浮出水面——分布式训练中的数据分布偏移问题,这个问题像一根细针,扎在微服务架构的神经末梢,而量子Batch Normalization(量子批归一化)的出现,终于让我们看清了这根针的位置。
微服务架构的“隐形枷锁”:数据分布偏移的致命性
2026年3月,某头部电商平台在“618”大促前进行压力测试时,发现推荐系统的响应时间突然飙升了300%,团队排查两周后发现,问题出在微服务拆分后的数据流上:用户画像服务、商品特征服务、实时交互服务分别运行在不同节点,每个服务独立处理数据时,由于硬件差异、网络延迟甚至算法版本不同,导致输入推荐模型的数据分布发生了微妙偏移,这种偏移在单机训练时几乎可以忽略,但在分布式环境下被放大,最终让模型输出结果完全失真。
“这就像让三个厨师分别炒同一道菜,但每个厨师的火候、调料比例甚至锅具都不一样,最后端出来的菜味道肯定不一样。”该平台AI架构师李明用烹饪比喻解释,“我们以为微服务拆分后各模块独立优化是进步,却忽略了数据分布的一致性才是模型训练的‘地基’。”
这不是个例,2026年5月,某智能驾驶公司训练自动驾驶模型时也遇到类似问题:感知模块、决策模块、控制模块的微服务分别部署在不同区域,由于各区域传感器数据分布不同(比如南方多雨、北方多雪),模型在跨区域部署时准确率下降了15%,更棘手的是,这种偏移是动态的——随着服务节点增减、网络波动甚至硬件老化,数据分布会持续变化,传统Batch Normalization(批归一化)技术根本无法实时追踪。
传统Batch Normalization的“力不从心”:为什么微服务需要量子升级?
Batch Normalization(BN)是深度学习中的“标配”技术,它的核心逻辑很简单:对每个批量的数据做标准化(减去均值、除以标准差),让模型训练更稳定,但在微服务架构下,BN的局限性暴露无遗:
-
分布式计算下的“局部标准化”陷阱:传统BN是在单个节点上计算批量数据的均值和方差,但在微服务中,数据可能被拆分到多个节点处理,比如用户画像服务处理100万用户数据,商品特征服务处理50万商品数据,两个服务的BN计算是独立的,导致合并后的数据分布仍然不一致。
-
动态环境下的“滞后更新”问题:微服务架构中,服务节点可能随时扩容或缩容(比如电商大促时临时增加推荐服务节点),但传统BN的均值和方差是静态计算的,无法实时适应这种变化,2026年6月,某金融科技公司训练风控模型时,就因为服务节点动态调整导致BN参数滞后,模型误拒率上升了8%。
-
跨服务协作的“信息孤岛”:微服务强调“高内聚、低耦合”,但BN需要全局数据分布信息,比如推荐系统需要同时用到用户画像和商品特征,但这两个服务的BN计算是隔离的,相当于模型在“盲人摸象”——只能看到局部数据,无法感知整体分布。

“传统BN就像用望远镜看星空,能看到局部细节,但看不到整个星系的运行规律。”清华大学计算机系教授王伟在2026年全球AI架构峰会上指出,“微服务架构需要一种能‘穿透服务边界’的归一化技术,而量子Batch Normalization正是这个方向的突破。”
量子Batch Normalization:用“量子纠缠”解决分布式难题
量子Batch Normalization(QBN)的核心思想,是借鉴量子力学中的“纠缠态”概念,让不同服务节点的数据在计算均值和方差时“共享”同一套参数,从而保证全局数据分布的一致性,QBN通过以下技术实现:
量子态编码:把数据“压缩”到量子比特
传统BN需要存储每个批量的均值和方差(浮点数),而QBN将数据编码为量子比特(qubit),量子比特的叠加态特性,让单个比特可以同时表示多个数据状态,从而大幅减少通信开销,100万用户数据的均值和方差,传统BN需要传输两个浮点数(约16字节),而QBN只需传输1个量子比特(约2字节),效率提升8倍。
2026年7月,阿里云发布的《量子计算与微服务架构白皮书》中提到,在某电商推荐系统的测试中,使用QBN后,服务间通信量减少了72%,模型训练时间从12小时缩短至3小时。 污水处理与数字经济及绿色设计热度持续攀升,相关技术取得新突破

纠缠态同步:让不同节点的BN参数“实时纠缠”
QBN通过量子纠缠协议,让不同服务节点的BN参数保持同步,比如用户画像服务和商品特征服务在计算均值时,不是各自独立计算,而是通过量子纠缠共享一个“全局均值”,即使某个节点因网络延迟或硬件故障暂时离线,其他节点仍能通过纠缠态恢复完整参数。
腾讯云在2026年8月公布的实测数据显示,在智能驾驶模型的训练中,使用QBN后,跨区域部署时的模型准确率从85%提升至97%,且不再需要手动调整BN参数——因为QBN能自动适应不同区域的数据分布。
动态解纠缠:应对服务节点的动态变化
微服务架构中,服务节点可能随时增减(比如电商大促时临时增加推荐节点),传统BN的参数会因此失效,QBN通过“动态解纠缠”技术,在节点变化时自动重新计算纠缠态,保证BN参数始终与当前服务拓扑匹配。
2026年9月,华为云在某金融风控系统的升级中应用了QBN,测试显示,当服务节点从10个动态扩展到50个时,QBN的参数更新延迟小于50毫秒,而传统BN需要重新计算全局均值和方差,延迟超过2秒——在大规模分布式训练中,这2秒的差距可能导致模型完全偏离正确方向。
真实案例:QBN如何拯救“崩溃”的微服务系统?
案例1:某头部电商平台的推荐系统“起死回生”
2026年“618”前,某电商平台推荐系统因数据分布偏移导致响应时间飙升300%,团队尝试了多种方案:增加缓存、优化SQL、甚至手动调整BN参数,但效果有限,他们决定在用户画像服务和商品特征服务之间引入QBN。
 2026年可再生能源与智慧城市领域取得重要进展,行业关注度持续提升
2026年可再生能源与智慧城市领域取得重要进展,行业关注度持续提升
具体改造步骤如下:
- 在用户画像服务的输出层和商品特征服务的输入层之间,插入QBN量子编码模块,将传统浮点数数据转换为量子比特;
- 通过量子纠缠协议,让两个服务的BN参数共享同一套全局均值和方差;
- 在推荐模型的训练过程中,使用QBN动态解纠缠技术,适应服务节点的动态变化(比如大促时临时增加的推荐节点)。
改造后效果显著:推荐系统响应时间从3秒降至800毫秒,模型准确率从78%提升至92%,更关键的是,系统不再需要人工干预BN参数——QBN能自动适应数据分布的变化,让团队终于从“救火”模式中解放出来。
案例2:智能驾驶公司的“跨区域部署”难题破解
绿色园区与绿色救援及乡村振兴热度持续上升,相关产业迎来新发展 某智能驾驶公司训练自动驾驶模型时,遇到跨区域部署的难题:南方多雨、北方多雪,不同区域的传感器数据分布差异极大,导致模型在跨区域部署时准确率下降15%,传统方案是针对每个区域单独训练模型,但这样成本高且无法共享数据。
2026年8月,该公司引入QBN技术,在感知模块、决策模块和控制模块之间建立量子纠缠通道:
- 感知模块(处理摄像头、雷达数据)和决策模块(生成驾驶指令)通过QBN共享全局数据分布参数;
- 控制模块(执行驾驶动作)根据QBN的动态解纠缠结果,实时调整控制策略;
- 在跨区域部署时,QBN自动适应不同区域的数据分布,无需重新训练模型。
测试显示,改造后的模型在南方雨天和北方雪天的准确率均达到97%以上,且部署时间从原来的72小时缩短至12小时——因为不再需要为每个区域单独训练模型。
QBN的挑战:不是“银弹”,但值得投入
尽管QBN在微服务架构优化中表现出色,但它并非“银弹”,2026年的技术实践中,企业仍需面对以下挑战:
- 硬件依赖:QBN需要量子计算硬件支持,而当前量子芯片