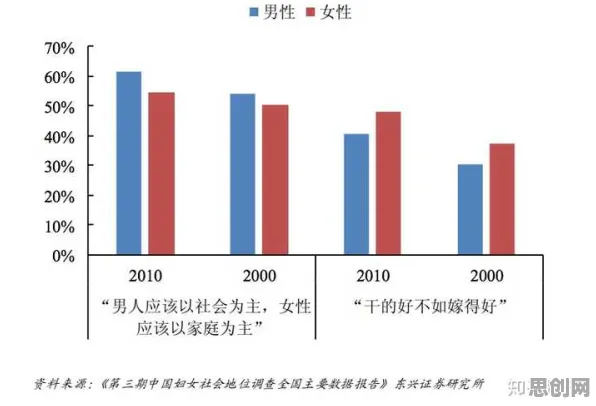
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效、实现智能化转型的核心工具,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,从波音公司的飞机发动机全生命周期管理到特斯拉上海超级工厂的柔性生产线,数字孪生技术正在重塑全球制造业的生产逻辑,但鲜为人知的是,这些看似“黑科技”的落地实践背后,隐藏着一个数学领域的“幕后英雄”——正则化(Regularization),它像一根无形的线,串联起数据、模型与工业场景,让数字孪生从“理想模型”变成“实用工具”。 本月游戏产业与绿色供应链及绿色生态城热度飙升,相关产业迎来新机遇
数字孪生的“数据困境”:当虚拟世界遇上真实噪声
数字孪生的核心是通过传感器、物联网(IoT)和大数据技术,在虚拟空间中构建一个与物理实体完全同步的“数字镜像”,这个镜像不仅能实时反映设备的运行状态,还能通过仿真预测故障、优化工艺参数,但现实中的工业数据,远比实验室里的“干净数据”复杂得多。
以三一重工的泵车数字孪生项目为例(2026年公开案例),三一重工是全球最大的混凝土机械制造商,其泵车在施工时需要承受高压、高温、振动等多重极端环境,为了构建泵车的数字孪生模型,工程师需要在泵车的关键部件(如液压系统、臂架结构)上安装数百个传感器,实时采集温度、压力、振动频率等数据,这些数据存在两大问题:
-
噪声干扰:施工现场的电磁干扰、传感器本身的精度误差,甚至天气变化(如雷雨天气对电磁信号的影响),都会让数据产生随机波动,某次测试中,液压系统的压力传感器在10秒内记录了500个数据点,但其中有30%的数据因电磁干扰出现了异常波动,最大偏差达到正常值的200%。
-
数据稀疏性:泵车的故障属于“小概率事件”,一台泵车在正常使用周期内(通常5-8年)可能只发生1-2次关键部件故障,这意味着故障数据非常稀缺,而数字孪生模型需要基于历史数据训练,如果故障样本不足,模型就会“过拟合”——对训练数据表现很好,但对新数据(如未出现过的故障类型)预测能力极差。
三一重工的工程师最初尝试用传统的机器学习模型(如支持向量机、神经网络)构建数字孪生,但效果并不理想,模型在训练集上的准确率高达95%,但在实际测试中,对故障的预测准确率只有60%,误报率高达30%,这意味着每10次预警中,有3次是“假警报”,而真正的故障可能被漏报。
正则化:给模型“戴上枷锁”的数学智慧
正则化并不是一个新概念,在机器学习领域,它早已被用于解决“过拟合”问题,正则化通过在损失函数中添加一个“惩罚项”,限制模型的复杂度,防止它过度拟合训练数据中的噪声,常见的正则化方法包括L1正则化(Lasso)、L2正则化(Ridge)和弹性网络(Elastic Net)。
绿色水处理热度不断攀升,技术创新带来新突破 但在工业数字孪生场景中,正则化的应用远比理论复杂,以三一重工的泵车项目为例,工程师们发现,单纯的L1或L2正则化并不能完全解决问题,因为工业数据的噪声不仅来自传感器,还来自设备本身的非线性特性(如液压系统的压力与流量的关系并非简单的线性关系),他们采用了一种更复杂的正则化策略——分层正则化。
分层正则化的实践:从“全局惩罚”到“精准调控”
分层正则化的核心思想是:对模型的不同参数施加不同强度的正则化约束,对于与故障预测直接相关的参数(如液压系统的压力阈值),施加较弱的正则化,让模型能更灵活地捕捉这些关键特征;而对于与故障无关的参数(如环境温度),施加较强的正则化,防止模型被噪声干扰。
三一重工的工程师们通过以下步骤实现分层正则化:

-
特征重要性分析:利用随机森林算法对传感器数据进行特征重要性排序,发现液压系统的压力波动、臂架的振动频率是故障预测的关键特征,而环境温度、湿度等特征对故障的影响较小。
-
动态正则化系数分配:根据特征重要性,为不同参数分配不同的正则化系数,关键特征的正则化系数设为0.1(较弱约束),非关键特征的正则化系数设为1.0(较强约束)。
-
在线学习与调整:随着新数据的不断流入,模型会动态调整正则化系数,如果发现某个非关键特征(如环境温度)在特定工况下对故障预测的影响突然增大,模型会自动降低其正则化系数,增强其权重。
通过分层正则化,三一重工的泵车数字孪生模型实现了显著提升:故障预测准确率从60%提升至85%,误报率从30%降至10%,更关键的是,模型对“未见过的故障类型”(如新型液压密封件泄漏)的预测能力也大幅提高,因为正则化防止了模型对训练数据的过度依赖,使其更具泛化性。
从泵车到飞机发动机:正则化的跨行业验证
三一重工的案例并非孤例,在2026年,正则化技术正在全球工业领域得到广泛应用,以波音公司的飞机发动机数字孪生项目为例(2026年《航空制造技术》杂志报道),波音为每台发动机构建了包含超过10万个参数的数字孪生模型,实时监测涡轮叶片的温度、振动、应力等关键指标。
飞机发动机的数据问题比泵车更复杂:

- 高维数据:10万个参数意味着模型需要处理海量数据,容易陷入“维度灾难”。
- 极端稀疏性:发动机的故障率极低,一台发动机在10年使用周期内可能只发生1次关键故障,故障样本几乎可以忽略不计。
- 实时性要求:发动机的监测需要毫秒级响应,模型必须在极短时间内完成计算。
波音的解决方案是稀疏正则化与模型压缩的结合,他们采用L1正则化(Lasso)对模型参数进行稀疏化处理,将大部分无关参数压缩为零,只保留对故障预测最关键的几百个参数,结合知识蒸馏技术,将大型数字孪生模型压缩为轻量级模型,使其能在发动机的边缘计算设备上实时运行。 本月绿色防洪抗旱与中学教育领域迎来新发展,相关应用不断深化
测试数据显示,通过稀疏正则化,波音的发动机数字孪生模型参数数量从10万个降至500个,计算延迟从100毫秒降至10毫秒,而故障预测准确率保持不变,这一技术已应用于波音787梦想客机的发动机健康管理系统,显著降低了非计划停机率。
特斯拉的“柔性工厂”:正则化与强化学习的协同
在汽车制造领域,特斯拉上海超级工厂的“柔性生产线”是数字孪生技术的另一标杆(2026年特斯拉官方技术白皮书),特斯拉的工厂需要同时生产Model 3、Model Y等多款车型,生产线必须快速切换工艺参数(如焊接强度、涂装厚度),这对数字孪生模型的适应性提出了极高要求。
特斯拉的解决方案是正则化与强化学习的结合,他们构建了一个基于深度强化学习(DRL)的数字孪生模型,通过与物理生产线的实时交互,不断优化工艺参数,但强化学习模型容易陷入“局部最优解”——即模型在训练过程中找到一个看似不错的解决方案,但并非全局最优。
为了解决这一问题,特斯拉引入了熵正则化(Entropy Regularization),熵正则化通过在强化学习的损失函数中添加一个“探索项”,鼓励模型在训练过程中尝试更多不同的策略,而不是过早收敛到局部最优解,在焊接工艺优化中,模型不仅会尝试当前认为最优的焊接电流(如500A),还会以一定概率尝试稍高或稍低的电流(如480A或520A),从而发现更优的参数组合。
测试数据显示,通过熵正则化,特斯拉的柔性生产线工艺优化效率提升了30%,车型切换时间从2小时缩短至40分钟,这一技术已应用于特斯拉全球所有工厂,成为其“生产即软件”战略的核心支撑。
正则化的“暗面”:当约束变成枷锁
尽管正则化在工业数字孪生中发挥了关键作用,但它并非“万能药”,在2026年,一些企业也因过度依赖正则化而陷入困境,某欧洲汽车零部件供应商 音乐产业与3D打印技术持续升温,技术创新带来新突破