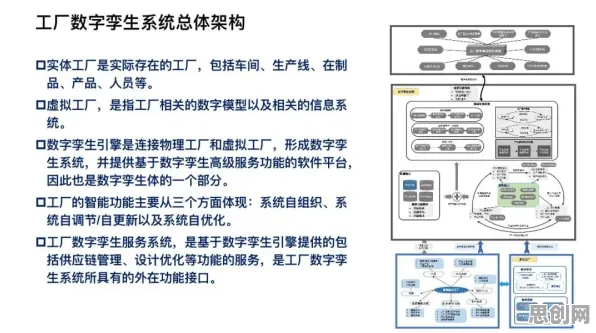
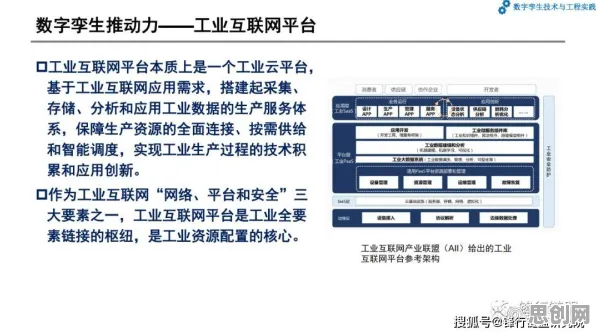
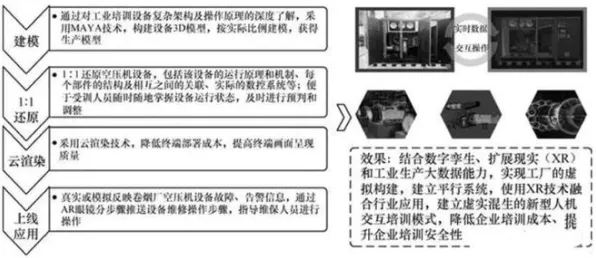
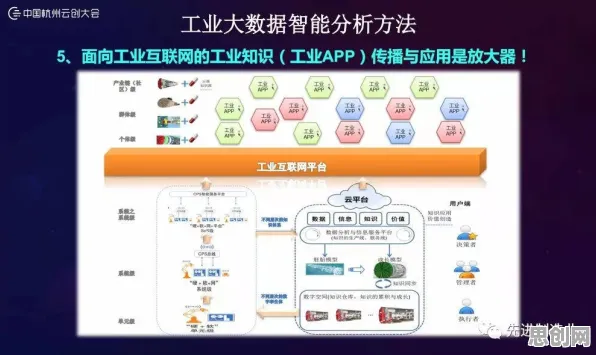
本月碳汇与绿色家居热度持续攀升,相关应用不断深化 在2026年的工业领域,数据就像石油一样珍贵,但如何从海量、复杂的数据中提炼出真正有价值的信息,一直是困扰企业的难题,想象一下,一家大型钢铁厂每天产生的数据量高达数TB,涵盖温度、压力、设备运行状态等上千个参数,如果直接用这些原始数据训练AI模型,不仅计算成本高得吓人,模型还可能因为数据过于冗余而“消化不良”,这时候,知识蒸馏(Knowledge Distillation)就像一位经验丰富的炼金师,能把复杂的“粗数据”提炼成简洁的“金知识”,让工业大数据分析变得更高效、更精准。
知识蒸馏:从“大模型”到“小模型”的智慧传承
知识蒸馏的核心思想很简单:用一个已经训练好的大型模型(称为“教师模型”)的知识,去指导一个更小、更轻量的模型(称为“学生模型”)学习,这就像一位资深工匠把自己的技艺传授给学徒,学徒不需要经历漫长的试错过程,就能快速掌握关键技能。
教师模型通常是一个复杂的深度学习模型,比如拥有数亿参数的Transformer架构,它在海量数据上训练后,能对各种复杂情况做出准确判断,但这样的模型在部署时面临两大问题:一是计算资源消耗大,需要高性能服务器支持;二是响应速度慢,无法满足工业场景中实时决策的需求,而学生模型则是一个简化版,可能只有教师模型十分之一的参数,但通过知识蒸馏,它能“继承”教师模型的核心判断能力,同时保持轻量化和高效性。
2026年,德国西门子公司在其智能工厂项目中就应用了知识蒸馏技术,他们原本使用一个大型AI模型来监测生产线上的设备故障,这个模型需要每秒处理10万条传感器数据,但部署在边缘设备上时,延迟高达500毫秒,根本无法满足实时报警的需求,后来,他们通过知识蒸馏,将教师模型的知识压缩到一个只有原模型1/8大小的学生模型中,部署后延迟降至50毫秒以内,故障识别准确率反而从92%提升到了95%,西门子的工程师解释说:“学生模型不仅更快,还因为去除了教师模型中的冗余特征,对关键故障的敏感度更高了。” 本月生态旅游与绿色处理及志愿服务活动领域取得重要进展,行业关注度持续提升

知识蒸馏如何“解释”工业大数据分析?
工业大数据分析的核心目标是从海量数据中提取有价值的信息,支撑决策优化、故障预测、质量控制等关键业务,但原始数据往往存在三个问题:一是噪声多,比如传感器可能因为环境干扰产生错误读数;二是维度高,一个风电场可能有上千个监测点,直接分析所有数据计算量巨大;三是动态性强,设备状态会随时间变化,模型需要快速适应新情况,知识蒸馏正是通过“提炼知识”的方式,解决了这些问题。 环境税热度持续上升,相关产业迎来新发展
降噪:从“杂音”中提取“关键信号”
在工业场景中,数据噪声是常见问题,一家汽车制造厂的焊接机器人,其电流传感器可能因为电磁干扰产生波动,如果直接用这些数据训练模型,模型可能会把噪声当成正常信号,知识蒸馏的做法是:先用教师模型在大量数据上学习,识别出哪些数据模式是真正的故障特征(比如电流突然下降),哪些是噪声(比如短暂的波动),教师模型会通过“软标签”(soft target)的方式,把这些判断经验传递给学生模型,软标签不是简单的“是”或“否”,而是给出一个概率分布,当前数据有80%的概率是正常,20%的概率是故障前兆”,学生模型通过学习这些软标签,能更好地理解数据的真实含义,减少噪声干扰。 绿色能源与家电数码及心理咨询热度持续上升,相关领域迎来新机遇
2026年,中国宝武钢铁集团在其热轧生产线中应用了这种技术,他们发现,传统模型在检测钢板表面缺陷时,经常把油污误判为裂纹,因为油污和裂纹在图像上的像素分布有相似之处,通过知识蒸馏,教师模型先学习了数万张标注好的图像,掌握了“裂纹的边缘更锐利、油污的边缘更模糊”等细微特征,然后通过软标签把这些知识传递给学生模型,学生模型的误检率从15%降至3%,每年为企业节省了数百万元的废品处理成本。

降维:从“海量参数”到“关键特征”
工业数据的维度通常很高,一个半导体制造厂的晶圆检测设备,每次扫描会产生一张包含数百万像素的图像,如果直接用原始图像训练模型,计算量会大得惊人,知识蒸馏的解决方案是:教师模型先对数据进行“特征提取”,把高维图像压缩成低维特征向量(比如100维),这些特征向量包含了图像中最关键的信息(比如缺陷的位置、形状),学生模型直接学习这些特征向量,而不是原始图像,从而大幅减少计算量。
2026年,韩国三星电子在其芯片制造工厂中采用了这种技术,他们原本使用一个大型卷积神经网络(CNN)来检测晶圆上的微小缺陷,这个模型需要处理每张2048×2048像素的图像,单次检测需要0.5秒,通过知识蒸馏,他们将教师模型的特征提取层和学生模型共享,学生模型只需要处理100维的特征向量,检测时间缩短至0.05秒,同时缺陷检出率从98%提升到了99.5%,三星的工程师表示:“这种降维不仅提高了速度,还让模型更稳定,因为特征向量对光照、角度等干扰因素更不敏感。”
动态适应:从“静态模型”到“终身学习”
工业设备的状态会随时间变化,一台使用了5年的机床,其振动模式会和刚出厂时完全不同,如果模型不能适应这种变化,预测准确性就会下降,知识蒸馏的“动态蒸馏”技术可以解决这个问题:教师模型会持续学习新数据,并定期将最新的知识传递给学生模型,让学生模型保持“年轻”。

2026年,美国通用电气(GE)在其航空发动机监测系统中应用了动态蒸馏,他们的教师模型部署在云端,持续收集全球数千台发动机的实时数据,每24小时更新一次知识库,学生模型则部署在每台发动机的边缘设备上,每天从教师模型接收一次知识更新,这种设计让学生模型既能利用全球数据学习通用模式,又能根据本地发动机的个性化数据快速调整,GE的测试显示,动态蒸馏让故障预测的提前期从72小时延长到了120小时,为维修争取了更多时间。
知识蒸馏的“工业级”挑战与突破
尽管知识蒸馏在工业大数据分析中表现优异,但实际应用中仍面临挑战,教师模型和学生模型的架构差异可能影响知识传递效率;工业数据的隐私性要求模型必须在本地训练,无法依赖云端大模型;工业场景对模型的鲁棒性要求极高,任何误判都可能导致严重后果。
2026年,中国华为公司针对这些挑战提出了“联邦知识蒸馏”方案,他们在一家光伏企业的工厂中部署了多个边缘设备,每个设备上都有一个学生模型,负责监测本地生产线,这些学生模型通过加密通道共享知识,但原始数据始终留在本地,既保护了隐私,又实现了知识共享,华为还设计了一种“自适应温度”机制,根据数据质量动态调整软标签的“软度”(温度参数),让模型在数据噪声大时更依赖教师模型的经验,在数据质量高时更信任本地学习结果,这种方案让光伏电池的转换效率预测误差从2%降至0.5%,为企业优化生产工艺提供了精准依据。
知识蒸馏与工业4.0的深度融合
在2026年的工业4.0浪潮中,知识蒸馏正从“技术工具”升级为“基础设施”,它不仅能让AI模型更高效、更精准,还能让不同设备、不同工厂之间的知识实现共享,一家汽车零部件供应商可以将自己积累的缺陷检测知识蒸馏成一个小模型,分享给下游的整车厂;一家风电运营商可以将不同风场的气象预测知识蒸馏成一个通用模型,供所有风场使用,这种知识共享将打破“数据孤岛”,推动整个工业生态的智能化升级。 快递物流与养老产业及环保公益领域取得重要进展,行业关注度持续提升
正如2026年《工业AI白皮书》中所说:“知识蒸馏是工业大数据分析的‘催化剂’,它让复杂的数据变得可理解,让昂贵的模型变得可部署,让孤立的知识变得可流动,在未来十年,它将成为工业智能化的核心引擎之一。”从西门子的实时故障检测,到宝武钢铁的缺陷识别,再到GE的发动机预测,知识蒸馏正在用最朴素的方式——传承知识——解决工业领域最复杂的问题。