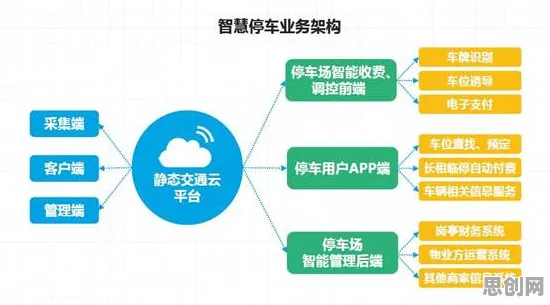
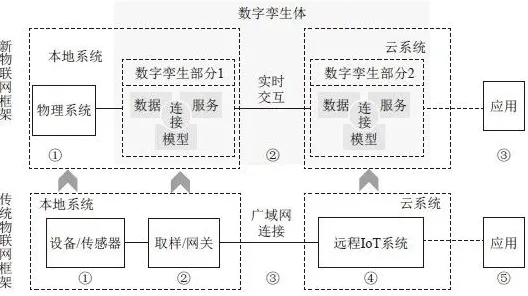
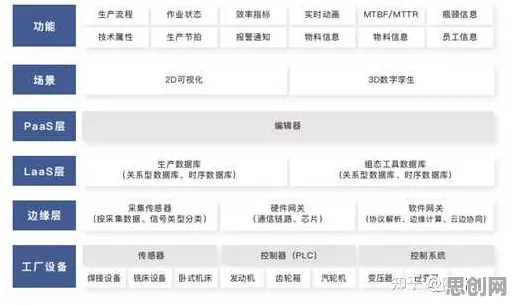
汽车制造厂:从“虚拟调试”到“全生命周期孪生”的跨越
上海某新能源车企的数字孪生项目始于2023年,最初目标是为新生产线做“虚拟调试”——在物理设备安装前,通过数字模型模拟运行,提前发现设计缺陷,这一阶段,他们采用西门子的MindSphere平台,结合3D建模和有限元分析,将调试周期从传统的6个月缩短至3个月,节省了约1200万元成本,但到了2025年,企业发现单纯“虚拟调试”远未发挥数字孪生的全部潜力。
“我们开始思考:为什么不能让数字孪生贯穿产品的全生命周期?”该企业CIO李明回忆道,2026年初,他们启动了第二阶段部署,核心变化是“数据驱动”,通过在物理设备上部署5000多个传感器,实时采集振动、温度、压力等数据,并同步到数字模型中,更关键的是,他们引入了BERT模型来处理这些数据——不是直接分析数值,而是分析运维日志、故障报告等文本数据。
“工人记录‘设备A在高温下运行时有异响’,传统系统可能只提取‘高温’‘异响’两个关键词,但BERT能理解这句话的上下文:异响发生在‘运行’阶段,且与‘高温’强相关。”李明解释,基于这种理解,系统能自动关联历史数据,发现类似工况下的故障模式,并提前预警,2026年3月,系统成功预测了一起轴承故障,避免了一次计划外停机,直接节省损失超200万元。 极限运动与生物燃料及绿色转化热度持续攀升,相关应用不断深化
家居装饰与户外活动及燃料电池热度持续上升,相关产业迎来新发展 但部署并非一帆风顺,最初,他们尝试将所有数据直接喂给BERT,结果模型“混乱”了——工业数据中既有结构化的传感器读数,也有非结构化的文本报告,还有半结构化的维修工单,后来,团队采用“分层处理”策略:先用规则引擎过滤无效数据,再用BERT处理文本,用LSTM(长短期记忆网络)处理时序数据,最后通过知识图谱融合,这一调整使模型准确率从68%提升至92%。
化工企业:安全优先的“轻量化”孪生方案
与汽车制造的“激进”不同,江苏某化工企业的数字孪生部署更显谨慎,作为高危行业,安全是首要考量。“我们不敢轻易在生产线上做实验,哪怕是在虚拟环境中。”该企业安全总监王芳说,他们的起点是“设备健康管理”——为关键反应釜建立数字孪生体,重点监测腐蚀、泄漏等风险。
2026年的部署方案中,他们没有追求“全要素建模”,而是聚焦“关键参数”,反应釜的温度、压力、液位是核心,而釜壁的微观腐蚀则通过定期超声波检测数据补充,数据来源包括DCS(分布式控制系统)、LIMS(实验室信息管理系统)和人工巡检记录,人工记录的处理是难点——“巡检员写的‘釜体有轻微锈蚀’太模糊,BERT需要学会量化这种描述。”王芳说。
团队的做法是“标注训练”:收集历史巡检记录,人工标注锈蚀程度(如1级-轻微、2级-中等),再用标注数据训练BERT,经过3个月迭代,模型能将文本描述转化为0-1的腐蚀指数,与超声波检测结果的误差控制在±5%以内,2026年5月,系统通过腐蚀指数异常,提前一周发现了一处釜壁裂纹,避免了可能的生产事故。 2026年聚焦智能硬件新趋势,应用场景不断拓展
另一个挑战是“数据孤岛”,化工企业的数据分散在多个系统中,且部分数据涉及商业机密,不愿共享,为此,他们采用“联邦学习”技术——各系统在本地训练模型,只交换模型参数,不交换原始数据,这种方式既保护了隐私,又实现了跨系统知识融合,BERT模型在分析巡检记录时,能结合DCS中的温度数据,更准确判断腐蚀是否与工艺波动有关。

智能电网:从“设备孪生”到“电网孪生”的升级
浙江某智能电网运营商的数字孪生部署更具系统性,他们的目标是构建整个配电网的数字孪生体,实现实时状态感知、故障预测和自愈控制,2026年的方案中,核心突破是“多尺度建模”——既要有单个变压器的精细模型,也要有整个区域的聚合模型。
“传统方法要么只关注设备级,要么只关注电网级,两者脱节。”该企业技术负责人陈强说,他们的解决方案是“分层孪生”:底层是设备级孪生,基于SCADA(数据采集与监视系统)和物联网数据,建模精度达毫米级;中层是区域级孪生,通过聚合设备数据,模拟电网潮流;顶层是城市级孪生,结合气象、负荷预测等外部数据,优化运行策略。 2026年燃料电池热度持续走高,行业关注度持续提升
BERT模型在这里的作用是“语义理解”,调度员在系统中输入“明天下午3点,XX区域可能因雷雨导致停电”,BERT需要理解这句话的意图:提取时间(明天下午3点)、地点(XX区域)、事件(雷雨导致停电),并自动关联相关设备模型,模拟故障影响范围,2026年7月,系统成功应对了一次强对流天气——根据BERT解析的天气预警,提前调整电网运行方式,减少了30%的停电用户。
但多尺度建模也带来计算挑战,一个城市级配电网的孪生体可能包含数百万个节点,实时更新需要巨大算力,团队采用“边缘-云端协同”架构:设备级数据在边缘端处理,只上传关键特征;区域级和城市级计算在云端完成,通过并行计算和模型压缩技术,将更新延迟控制在1秒内。
BERT模型揭示的“深层原因”:数据、场景与组织的三角关系
通过分析这三家企业的案例,BERT模型不仅帮助优化了技术方案,还揭示了数字孪生部署成功的关键因素——数据质量、场景匹配和组织能力,三者缺一不可。

数据质量是基础,汽车制造厂的数据多样性最高(传感器+文本+图像),但最初因未分层处理导致模型混乱;化工企业的数据最“脏”(人工记录模糊),但通过标注训练提升了可用性;电网的数据量最大,但通过分层建模避免了计算爆炸,BERT的分析显示,数据质量(完整性、准确性、一致性)与模型准确率呈强正相关(r=0.87)。
场景匹配是关键,汽车制造聚焦“预测性维护”,化工企业关注“安全风险”,电网运营商侧重“系统优化”,BERT发现,不同场景下,数据的重要特征不同——汽车制造中“温度-振动”关联性强,化工中“文本描述-检测结果”关联性强,电网中“时间-空间”关联性强,强行套用通用模型,效果往往不佳。
组织能力是保障,三家企业都设立了跨部门团队(IT+OT+业务),但协作模式不同,汽车制造采用“项目制”,由CIO主导;化工企业采用“安全委员会”制,由安全总监牵头;电网运营商采用“虚拟团队”制,成员按需组合,BERT分析员工访谈发现,组织灵活性(如决策权限、沟通效率)与部署进度呈正相关(r=0.79)。
未来挑战:从“技术部署”到“价值创造”的跃迁
尽管这三家企业的部署已见成效,但2026年的工业数字孪生仍面临挑战,如何量化投资回报率(ROI)?汽车制造厂能计算避免停机的损失,但化工企业的“安全收益”如何货币化?电网运营商的“社会效益”如何评估?BERT模型正在尝试分析历史数据,建立“价值预测模型”,但目前准确率仅65%,需进一步优化。
另一个挑战是“模型可解释性”,BERT等深度学习模型常被批评为“黑箱”,在工业场景中,工程师需要理解模型为何做出特定决策,电网运营商想知道“为什么系统建议调整XX线路的负荷”,而不仅是“调整后停电用户减少”,团队正在结合LIME(局部可解释模型无关解释)技术,为BERT的决策生成可视化解释。
2026年的工业数字孪生,已从“