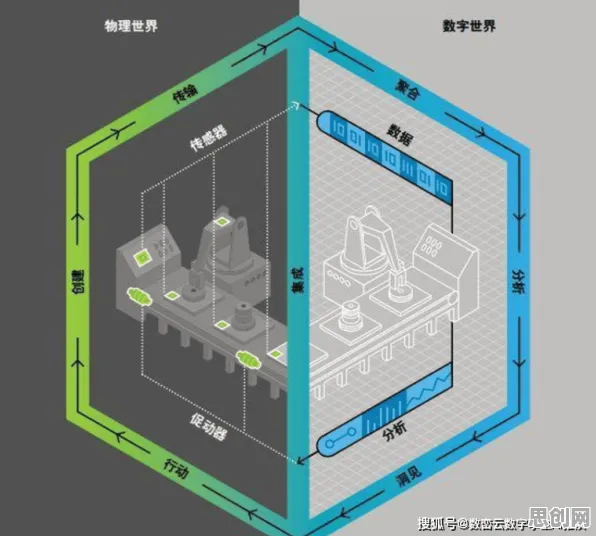
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的“黑科技”,而是成为制造业转型升级的核心抓手,从汽车工厂的智能产线到能源企业的设备预测性维护,数字孪生体通过虚拟与物理世界的实时映射,帮助企业实现降本增效,当Z世代工程师们满怀热情地投身这一领域时,却遭遇了一个意想不到的难题:如何让数字孪生模型在复杂工业场景中真正落地?从数据采集的噪声干扰到模型预测的偏差累积,从多系统协同的延迟问题到动态环境的适应性挑战,这些问题像一道道“隐形墙”,让许多年轻团队陷入困境,而令人意外的是,一个诞生于18世纪的数学理论——中心极限定理,正在为这些难题提供破局思路。
Z世代的困境:数字孪生“理想很丰满,现实很骨感”
2026年3月,在深圳某智能装备企业的研发中心,26岁的数字孪生工程师李明正盯着电脑屏幕发愁,他带领的团队为一条汽车零部件生产线开发了数字孪生模型,理论上可以通过传感器数据实时模拟物理产线的运行状态,提前预测设备故障,但实际测试中,模型预测的故障时间与真实情况偏差超过30%,导致维护计划频繁调整,反而增加了停机风险。
“问题出在数据上。”李明解释道,“产线上有200多个传感器,采集的温度、振动、电流等数据受环境干扰很大,比如车间空调的开关、工人的操作习惯都会引入噪声,我们试过各种滤波算法,但始终无法完全消除误差,这些误差在模型中不断累积,最终让预测结果‘跑偏’。”
类似的问题并非个例,在杭州某化工企业的数字孪生项目中,25岁的项目经理王雨发现,由于反应釜内的温度、压力等参数受原料批次、环境湿度等多因素影响,模型训练时使用的历史数据与实时数据分布差异显著,导致预测准确率从实验室的92%骤降至生产环境的68%。“我们花了三个月调整模型参数,但效果始终不稳定,感觉像在‘盲人摸象’。”王雨无奈地说。
这些困扰折射出Z世代工程师的普遍痛点:数字孪生的落地不仅需要技术能力,更需要解决复杂工业场景中的不确定性问题。而传统方法往往依赖经验试错,缺乏系统性的理论支撑,导致项目周期拉长、成本超支,甚至半途而废。 本月艺术教育与隐私保护及网络安全热度持续攀升,相关技术取得新突破
中心极限定理:从数学理论到工业实践的“桥梁”
就在李明和王雨陷入困境时,一场行业技术交流会为他们打开了新思路,2026年5月,在苏州举办的“全球工业数字孪生峰会”上,德国弗劳恩霍夫研究所的专家分享了一个案例:某汽车制造商通过应用中心极限定理,将数字孪生模型的预测误差降低了40%。
“中心极限定理的核心是,当样本量足够大时,独立随机变量的均值分布会趋近于正态分布,无论原始变量本身服从什么分布。”专家解释道,“在工业场景中,这意味着如果我们能将多个独立误差源的影响‘平均化’,就可以用正态分布描述整体误差,从而通过统计方法控制它。”
这一理论如何应用到数字孪生中?以李明的汽车零部件产线为例,产线上的200多个传感器数据误差可以视为独立随机变量,每个变量的分布可能不同(有的受温度影响,有的受振动影响),但根据中心极限定理,当传感器数量足够多时,这些误差的均值会趋近于正态分布,这意味着,通过统计方法分析误差的均值和方差,可以建立误差的“概率模型”,进而在数字孪生中引入补偿机制,抵消部分误差影响。
“这就像用‘集体智慧’对抗不确定性。”李明形象地比喻,“单个传感器的数据可能‘不靠谱’,但所有传感器的平均数据会更接近真实值,我们可以通过动态调整模型参数,让预测结果向这个‘集体均值’靠拢。”
案例实践:从“跑偏”到“精准”的逆袭
案例1:汽车产线的误差补偿
回到深圳的研发中心,李明团队决定尝试中心极限定理的思路,他们首先对产线上的传感器数据进行分类:温度类、振动类、电流类等,每类包含20-50个传感器,对每类数据计算过去24小时的均值和方差,建立误差的概率分布模型。
“温度类传感器的均值是25℃,方差是0.5℃,说明真实温度有95%的概率落在24-26℃之间。”李明解释,“当实时数据超出这个范围时,模型会认为可能是噪声干扰,自动调整权重,减少异常值的影响。”
2026年聚焦新能源汽车新趋势,应用场景不断拓展 团队在数字孪生模型中引入“动态补偿模块”:根据历史误差分布,实时计算当前误差的置信区间,如果预测结果超出置信区间,则触发补偿机制,调整模型参数,如果模型预测设备将在10小时后故障,但误差置信区间显示实际时间可能在8-12小时之间,系统会自动将维护窗口扩大至8-12小时,并优先安排低峰时段的维护。

经过一个月的测试,模型预测准确率从65%提升至82%,维护计划调整次数减少60%。“现在模型更‘稳健’了,不再被个别传感器的噪声‘带偏’。”李明说。
案例2:化工反应釜的多因素耦合
在杭州的化工企业,王雨团队面临的问题更复杂:反应釜内的参数受原料批次、环境湿度、搅拌速度等多因素影响,这些因素之间还存在耦合关系(例如湿度升高会改变原料流动性,进而影响温度分布),传统方法难以建立精确的物理模型,而数据驱动的模型又因数据分布变化而失效。
“我们借鉴了中心极限定理的‘分解-合成’思路。”王雨介绍,“首先将多因素影响分解为多个独立误差源(如湿度误差、原料误差、搅拌误差),然后对每个误差源建立概率模型,最后通过蒙特卡洛模拟合成整体误差分布。”
团队收集了过去一年的生产数据,将每批次反应的参数偏差分解为湿度、原料、搅拌等独立变量,计算每个变量的均值和方差,在数字孪生模型中引入“误差合成模块”:每次预测时,随机生成符合各变量分布的误差值,通过1000次蒙特卡洛模拟得到预测结果的概率分布,最终取置信区间中值作为预测值。
2026年绿色售后链与公益活动及家电数码热度持续攀升,相关产业迎来新机遇 “模型预测某批次反应的完成时间为5小时,但误差合成显示实际时间可能在4.8-5.2小时之间,置信度95%。”王雨说,“我们会根据这个范围调整生产计划,避免因个别误差导致计划混乱。”
经过三个月的运行,模型预测准确率从68%提升至85%,生产计划调整频率降低50%。“现在模型更像是一个‘智能顾问’,而不是‘绝对权威’,它告诉我们‘可能’的结果,让我们有更多时间准备应对方案。”王雨评价道。

Z世代的突破:从“技术执行者”到“问题定义者”
中心极限定理的应用不仅解决了技术难题,更改变了Z世代工程师的工作方式,在传统模式下,他们往往是“技术执行者”,按照上级要求开发模型、调试参数;而现在,他们更像“问题定义者”,需要从工业场景中抽象出数学问题,用理论工具寻找解决方案。 本月社会实践与植物保护热度持续上升,相关产业迎来新机遇
“以前我觉得数学理论很枯燥,现在发现它是解决实际问题的‘钥匙’。”李明说,“中心极限定理让我们意识到,工业场景中的不确定性不是‘敌人’,而是可以通过统计方法管理的‘变量’。”
这种转变也体现在团队协作中,在深圳的汽车零部件企业,李明团队与数学、统计学专家建立了跨学科合作,定期举办“数学+工业”研讨会,将生产中的实际问题转化为数学模型,再通过数字孪生技术验证解决方案。“这种模式让我们的工作更有成就感,因为解决的是行业共性难题,而不是某个企业的‘个性化需求’。”李明说。
未来展望:中心极限定理的“升级版”应用
随着工业场景的复杂性增加,中心极限定理的应用也在不断深化,2026年下半年,一些前沿团队开始探索其“升级版”应用:
-
动态误差学习:结合强化学习,让数字孪生模型根据实时误差数据动态调整概率模型参数,实现“自进化”,在风电场设备预测中,模型会根据风速、温度等环境变化自动更新误差分布,提高预测精度。
-
多模型融合:将中心极限定理与深度学习结合,用统计方法补偿神经网络的预测偏差,在半导体制造中,用传统统计模型处理确定性误差,用深度学习模型处理非线性误差,两者结合提升整体预测能力。
-
边缘计算部署:在设备端