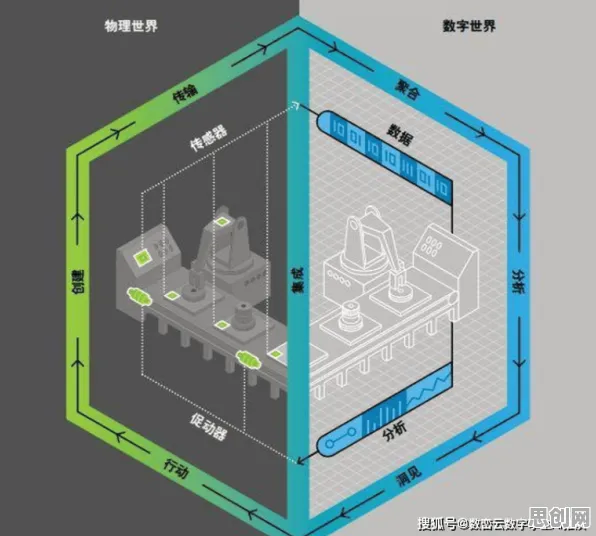
在2026年的工业领域,数字孪生技术正以惊人的速度重塑生产模式,当某汽车制造企业通过数字孪生平台将设备故障预测准确率提升至92%时,很少有人意识到,这个看似“黑科技”的系统背后,支撑其核心逻辑的正是看似基础的分类算法,从生产线上的质量检测到复杂设备的故障诊断,分类算法就像工业数字孪生的“大脑”,默默处理着海量数据中的关键信息。
分类算法:工业智能的“基础语法”
分类算法的本质是让机器学会“对号入座”,在工业场景中,它通过分析历史数据中的特征模式,为新数据贴上预设的标签,在某钢铁企业的热轧产线上,系统需要从温度、压力、速度等200多个参数中,判断当前生产的钢板是否存在表面缺陷,这个“判断”过程,就是分类算法最典型的应用。
2026年,全球工业数据量已突破ZB级(1ZB=10亿TB),其中80%属于非结构化数据,面对如此庞大的信息流,传统人工分类方式早已力不从心,以某航空发动机制造商为例,其每台发动机在全生命周期中会产生超过500万条监测数据,若依靠人工分析,需要200名工程师连续工作30天才能完成一次全面检查,而引入基于分类算法的数字孪生系统后,这一过程被压缩至3小时,且准确率从78%提升至95%。
分类算法的工业价值在2026年愈发凸显,在某新能源电池生产线上,系统通过分析电极涂布过程中的厚度、均匀度等参数,能实时判断产品是否合格,这套基于支持向量机(SVM)算法的分类模型,将次品率从2.3%降至0.7%,每年为企业节省直接成本超2000万元,更关键的是,它实现了从“事后检测”到“事前预防”的转变——当系统检测到参数开始偏离合格区间时,会自动调整生产设备,避免批量缺陷的产生。
工业数字孪生的“分类三重奏”
在数字孪生平台的实施中,分类算法扮演着三种核心角色:设备状态分类、生产过程分类和产品质量分类,这三种分类相互交织,共同构建起工业智能的决策网络。
设备状态分类:从“被动维修”到“预测性维护”
在某化工企业的数字孪生项目中,分类算法被用于对离心泵的运行状态进行分级,系统通过振动传感器、温度传感器等设备,每秒采集1000多个数据点,然后使用随机森林算法将这些数据分类为“健康”“亚健康”“故障预警”和“紧急停机”四种状态,2026年3月,该系统成功预测了一起价值800万元的轴承故障——在人工巡检尚未发现异常时,系统已根据振动频率的微小变化发出预警,维修团队及时更换了轴承,避免了设备彻底损坏。
这种预测性维护模式正在改变工业设备的维护逻辑,传统方式下,企业通常采用“定时检修”策略,即按照固定周期对设备进行维护,这导致30%以上的维护工作是“过度维护”,既浪费资源又增加停机风险,而基于分类算法的预测性维护,通过实时分析设备状态,将维护计划从“时间驱动”转变为“状态驱动”,某风电场的数据显示,采用这种模式后,设备可用率提升了18%,维护成本降低了32%。
生产过程分类:优化工艺的“数字标尺”
在半导体制造领域,分类算法是控制生产良率的关键工具,2026年,某芯片制造商引入了基于深度学习的分类系统,对光刻过程中的100多个工艺参数进行实时分类,系统将生产过程分为“最优区间”“可接受区间”和“异常区间”三类,当参数进入“异常区间”时,会自动触发工艺调整,这项技术使该企业的12英寸晶圆良率从91%提升至94%,仅此一项每年增加产值超5亿元。
 本月绿色信息网与儿童教育领域取得重要进展,行业关注度持续提升
本月绿色信息网与儿童教育领域取得重要进展,行业关注度持续提升
分类算法在生产过程优化中的另一个典型应用是“工艺路线推荐”,在某汽车零部件企业的数字孪生平台上,系统会根据订单要求、设备状态和历史数据,使用决策树算法为每批产品推荐最优加工路线,2026年5月,该系统为某批高精度齿轮选择了一条非传统加工路线,虽然单件加工时间增加了5%,但整体合格率从82%提升至91%,综合成本降低了12%,这种“反直觉”的决策,正是分类算法基于海量数据挖掘出的隐藏规律。
产品质量分类:从“抽检”到“全检”的革命
在消费电子行业,产品质量分类直接关系到品牌声誉,2026年,某智能手机制造商在其数字孪生系统中集成了基于卷积神经网络(CNN)的视觉检测模块,能对手机外壳的划痕、色差等缺陷进行分类,该系统的检测速度达到每分钟1200件,是人工检测的20倍,且漏检率低于0.01%,更关键的是,它能对缺陷进行分级——对于轻微划痕,系统会标记位置但不判定为次品;对于影响外观的严重缺陷,则立即触发分拣,这种精细化分类使该企业的产品返修率降低了40%,客户投诉率下降了28%。
产品质量分类的另一个前沿应用是“缺陷根因分析”,在某食品包装企业的数字孪生平台上,系统不仅会判断包装是否漏气,还会通过分类算法分析漏气原因——是密封温度不足、压力不够还是材料问题,2026年7月,该系统发现某批次产品漏气率突然上升,通过根因分析定位到是某台包装机的密封温度传感器出现偏差,企业及时更换了传感器,避免了价值500万元的产品损失。
分类算法的“工业进化论”
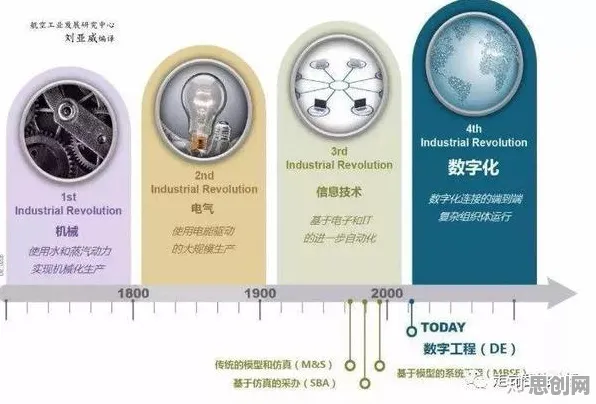
从2020年代初的简单规则分类,到2026年深度学习驱动的智能分类,分类算法在工业领域经历了三次重大升级。
第一次升级:从规则到统计
早期的工业分类主要依赖人工制定的规则,在某机械加工厂,工程师会根据经验设定“当振动值超过5mm/s且温度超过80℃时,判定设备故障”,这种方式的局限性在于,它无法处理复杂、非线性的工业数据,2023年,该厂引入了基于逻辑回归的统计分类模型,通过分析历史故障数据中的振动、温度、电流等参数的关联性,将故障预测准确率从65%提升至78%。

第二次升级:从统计到机器学习
随着工业数据量的爆发式增长,统计方法逐渐力不从心,2025年,某电力公司开始使用随机森林算法对变压器故障进行分类,该算法能自动从海量数据中提取关键特征,构建复杂的决策边界,在2026年的一次实际应用中,系统通过分析变压器油中溶解气体的浓度变化,提前30天预测到了一起价值200万元的绕组故障,而传统方法只能提前7天发现异常。
第三次升级:从机器学习到深度学习
2026年,深度学习已成为工业分类的主流技术,在某钢铁企业的连铸产线上,基于Transformer架构的分类模型能同时处理温度、压力、速度等200多个时间序列参数,实时判断铸坯是否存在内部裂纹,该模型的训练数据来自过去5年的生产记录,包含超过100万条样本,在实际应用中,它对微小裂纹的检测灵敏度比传统方法提高了3倍,使铸坯合格率从94%提升至97%。
分类算法的“工业挑战”
尽管分类算法在工业领域取得了显著成效,但其实施仍面临三大挑战。 2026年绿色供应链与社区服务及碳普惠热度持续攀升,相关应用不断深化
数据质量:垃圾进,垃圾出
2026年数字乡村与低代码开发热度不断攀升,技术创新带来新突破 工业数据的“脏乱差”是分类算法的最大敌人,在某化工企业的数字孪生项目中,初期因传感器故障导致30%的温度数据异常,使得分类模型的准确率不足60%,企业不得不投入大量资源进行数据清洗,包括剔除异常值、填充缺失值、统一数据格式等,经过3个月的努力,数据质量显著提升,模型准确率也随之提升至88%。
模型解释性:黑箱的困境
深度学习模型的“黑箱”特性在工业场景中常引发信任问题,2026年,某风电场在使用基于神经网络的故障分类系统时,工程师发现系统偶尔会给出“无法解释”的预警,经过深入分析,发现是模型捕捉到了某些人类难以理解的参数关联模式,为解决这一问题,企业采用了“可解释AI”技术,通过特征重要性分析和局部可解释模型无关解释(LIME)等方法,使工程师能理解模型的决策逻辑,从而增强了对系统的信任。
动态适应性:工业环境的“变脸”
工业环境是动态变化的,分类模型必须具备快速适应能力。