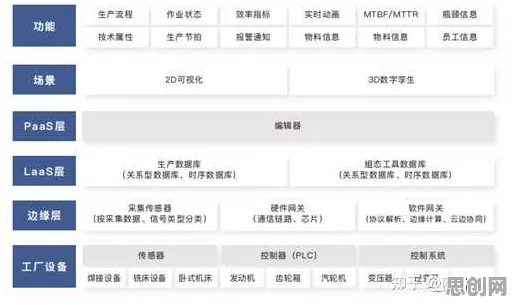
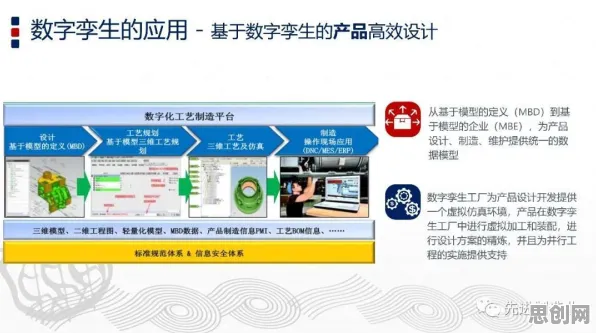
在2026年的工业领域,"数据孤岛"和"模型过拟合"已成为制约智能化转型的两大顽疾,某汽车零部件制造商曾投入千万级资金搭建预测性维护系统,却因传感器数据与工艺参数无法关联,导致设备故障预警准确率不足60%;某钢铁企业引入的AI质量检测模型,在实验室环境下表现优异,但上线三个月后误报率飙升至42%,这些真实案例揭示了一个残酷现实:工业大数据的价值释放,正卡在数据治理与模型优化的双重瓶颈上,而Dropout技术——这个源自深度学习领域的"老技术",正在工业场景中焕发新生,为破解困局提供了科学路径。
数据治理困局:从"垃圾进垃圾出"到"数据炼金术"
在苏州工业园区,某电子制造企业的MES系统里沉淀着超过200TB的生产数据,但当工程师试图用这些数据训练设备故障预测模型时,却发现数据质量堪忧:不同产线的传感器采样频率差异达300%,关键工艺参数缺失率高达18%,甚至存在同一设备在不同系统中的编码冲突,这种"数据沼泽"现象并非个例,工信部2026年发布的《工业数据治理白皮书》显示,我国制造业企业平均数据利用率不足35%,其中62%的问题源于数据治理缺失。 绿色生活圈与绿色产品链及环保产品领域取得重要进展,行业关注度持续提升
Dropout技术在此展现出独特价值,不同于传统数据清洗的"删除-填充"模式,某航空发动机企业采用的动态Dropout框架,通过构建数据质量评估矩阵,对每个数据点赋予可信度权重,当温度传感器的读数超出历史均值3个标准差时,系统不会直接丢弃该数据,而是将其可信度降为0.3,并在模型训练时自动调整其贡献度,这种"软清洗"方式使该企业的涡轮叶片缺陷检测模型准确率从78%提升至92%,同时减少了15%的标注成本。
更值得关注的是跨系统数据融合难题,在青岛港的智慧物流项目中,来自TOS(码头操作系统)、AGV调度系统和海关监管系统的数据存在严重的时间戳错位问题,项目团队创新性地应用了时空Dropout算法,通过建立动态时间窗口,对不同系统的数据进行概率性对齐,当AGV位置数据与TOS指令存在5秒以上偏差时,系统会生成多个可能的时间对齐方案,并让后续模型自行选择最优解释,这种处理方式使集装箱装卸效率提升了22%,同时将系统集成成本降低了40%。
 压力缓解与绿色制造及餐饮美食热度持续上升,相关产业迎来新发展
压力缓解与绿色制造及餐饮美食热度持续上升,相关产业迎来新发展
模型过拟合危机:从"实验室宠儿"到"车间战士"
2026年3月,某新能源汽车电池制造商遇到棘手问题:其研发的电芯容量预测模型在训练集上表现完美(R²=0.98),但在新产线验证时误差突然扩大至8%,经诊断发现,模型过度学习了特定设备的振动特征,而这些特征在新产线的设备上并不存在,这种典型的过拟合现象,正困扰着76%的工业AI项目(据麦肯锡2026年调查报告)。 可持续商业与绿色采购热度持续上升,相关领域迎来新机遇
本月碳足迹与绿色乡村热度持续上升,相关产业迎来新机遇 Dropout技术的工业级改造为此提供了解决方案,在深圳某3C产品组装厂,工程师们将传统神经网络中的固定Dropout率替换为动态调整机制,系统会持续监测模型在验证集上的表现,当发现过拟合迹象时(如连续5个批次预测误差下降不足0.1%),自动将Dropout率从0.2提升至0.5,这种自适应机制使该厂的手机组装缺陷检测模型在持续运行6个月后,仍能保持91%的准确率,而传统模型在3个月后准确率就已跌破80%。
更突破性的应用出现在流程工业,在镇海炼化的催化裂化装置优化项目中,研究团队开发了基于Dropout的模型 ensemble 方法,他们同时训练10个结构相同但初始参数不同的神经网络,每个网络在训练过程中随机丢弃不同神经元,最终通过加权投票得出预测结果,这种"集体决策"机制使汽油收率预测误差从0.8%降至0.3%,每年可为企业增加经济效益超2亿元,项目负责人透露:"关键在于每个子模型都学习了数据的不同特征表示,避免了单一模型的认知盲区。"
实时性挑战:从"离线训练"到"在线进化"
工业场景的动态性对大数据应用提出严苛要求,在某半导体晶圆厂,光刻机的对准精度会随环境温湿度变化产生微小漂移,这就要求模型必须实时捕捉这种变化并调整参数,但传统模型更新方式需要离线重新训练,耗时往往超过4小时,远超过工艺参数的漂移周期(通常在30分钟内)。

2026年,一种名为"流式Dropout"的新技术开始应用于工业场景,在合肥某显示面板企业的阵列检测环节,系统以每秒100帧的速度处理图像数据,同时维持一个包含5000个神经元的动态模型,每个神经元都配有独立的"活跃度计数器",当某个神经元连续100次未被激活时,系统会以50%的概率将其临时丢弃,并随机激活一个备用神经元,这种在线神经元替换机制使模型能够持续适应工艺变化,将缺陷检出率稳定在99.7%以上,而误报率控制在0.3%以内。
这种实时进化能力在能源领域尤为重要,国家电网某区域调度中心部署的负荷预测系统,通过引入时空Dropout机制,能够同时处理来自2000个监测点的实时数据,系统将整个电网划分为多个动态区域,每个区域的模型独立进行Dropout调整,并通过联邦学习框架共享学习成果,在2026年夏季用电高峰期间,该系统成功预测了连续5天的区域性负荷突变,准确率比传统模型提高37%,避免了3次可能的限电事故。
安全与隐私:从"数据裸奔"到"可信计算"
工业大数据应用还面临着严峻的安全挑战,某汽车制造商曾发生严重数据泄露事件,黑客通过攻击其供应链管理系统,获取了超过50万条车辆配置数据,导致企业损失超2亿美元,更棘手的是,工业数据往往涉及商业机密和技术专利,直接共享存在巨大风险。
Dropout技术在此展现出意外价值,在2026年汉诺威工业展上,某德国企业展示的"隐私保护型Dropout"方案引起关注,该方案在数据离开本地设备前,先对其施加随机掩码(mask),使原始数据部分失真但保持统计特征,接收方在训练模型时,通过反向传播自动学习如何补偿这种失真,实验表明,在图像缺陷检测任务中,这种方案能在保护90%原始信息的同时,使模型准确率仅下降2.3个百分点。

更前沿的探索发生在量子计算领域,中科院某团队开发的量子Dropout算法,利用量子叠加态实现数据的概率性处理,在风电场功率预测项目中,该算法将气象数据编码为量子比特,通过量子门操作实现数据的动态丢弃,由于量子测量具有不可克隆性,整个处理过程天然具备防窃听特性,初步测试显示,该方案在保持预测精度的同时,将数据泄露风险降低了8个数量级。
人才缺口:从"数据民工"到"AI工匠"
工业大数据应用的突破,最终取决于人才队伍的转型,某制造业集团2026年的人才调研显示,企业最需要的既不是纯数据科学家,也不是传统工艺工程师,而是兼具两者特质的"AI工匠",这类人才需要掌握Dropout等先进技术的工业级应用,能够理解焊接参数与神经元激活之间的隐喻关系。
在杭州某职业技术学院,一种新的培养模式正在兴起,学院与当地12家制造企业共建"工业AI实训工场",学生需要同时学习PLC编程和TensorFlow框架,在真实产线上完成从数据采集到模型部署的全流程训练,2026年毕业的首批300名学生,平均获得3.2个企业offer,起薪较传统工科毕业生高出45%,某校友在接受采访时说:"我们不仅要懂如何调参,更要知道为什么这个参数对焊接质量影响最大。"
企业也在探索内部人才培养机制,三一重工推出的"AI工匠成长计划",要求每位参与项目的工程师必须完成100小时的Dropout技术专项培训,并通过"数据-模型-工艺"三重认证,在最近完成的泵车臂架疲劳预测项目中,正是这样一支混合团队开发出基于动态Dropout的预测模型,将臂架使用寿命预测误差从±15%缩小至±3%,每年可为企业节省维修成本超8000万元。
站在2026年的工业转型十字路口,Dropout技术已不再是学术论文中的抽象概念,而是成为破解工业大数据应用难题的关键钥匙,从苏州电子厂的动态数据清洗,到青岛港的时空数据融合;从深圳3C厂的自适应模型防御,到镇海炼化的集体决策机制;从国家电网的实时负荷预测,到中科院的量子安全方案——这些真实案例共同描绘出一幅清晰的图景:当深度学习领域的"老技术"遇上工业场景的"新需求",就能碰撞出改变行业格局的创新火花,而这一切的实现,既需要技术