污水处理与氢能技术及绿色草原保护热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生体早已不是新鲜概念,从德国的“工业4.0”到中国的“智能制造2025”,全球制造业都在疯狂追逐这个能将物理世界与数字世界深度融合的“魔法工具”,但当企业们砸下重金部署数字孪生系统后,一个残酷的现实逐渐浮现:超过60%的工业数字孪生项目未能达到预期收益(据麦肯锡2026年全球工业数字化转型报告),这背后,隐藏着一个被绝大多数人忽视的关键——梯度下降算法在工业场景中的“水土不服”。
当数字孪生遇上梯度下降:一场被过度简化的技术狂欢
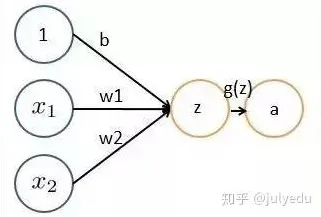
本月药品研发热度持续走高,行业关注度持续提升 数字孪生的核心逻辑很简单:通过传感器采集物理设备的实时数据,在虚拟空间中构建一个与之完全对应的“数字分身”,再利用这个分身进行仿真、预测和优化,但要让这个分身“活起来”,关键在于如何让虚拟模型不断逼近物理现实——这正是梯度下降算法的主战场。
梯度下降,这个在机器学习领域被奉为“万能钥匙”的优化算法,其原理也并不复杂:通过计算损失函数的梯度(即方向),不断调整模型参数,最终找到使损失最小的最优解,在图像识别、自然语言处理等IT领域,它确实屡试不爽——但当它被直接套用到工业场景时,问题就来了。
“我们最初以为,只要把生产线的传感器数据接进来,用梯度下降跑几轮优化,就能让设备效率提升20%。”某汽车零部件制造商的CTO李明在2026年工业互联网峰会上坦言,“但实际运行了三个月后发现,模型预测的设备故障时间与实际偏差超过40%,优化后的生产参数反而导致良品率下降了5个百分点。”
这不是个例,2026年3月,德国弗劳恩霍夫研究所发布的一份报告显示:在参与调研的127家制造业企业中,有83家表示数字孪生模型的预测精度“远低于预期”,其中62家明确指出“梯度下降算法在工业数据上的收敛性极差”。
工业数据的“三座大山”:梯度下降的致命陷阱
为什么在IT领域无往不利的梯度下降,在工业场景却频频“翻车”?答案藏在工业数据的特殊性里。

数据稀疏性:99%的“无效信息”如何处理?
工业设备的运行数据有个典型特征:大部分时间处于“正常状态”,以一台数控机床为例,它可能99%的时间都在平稳加工零件,只有1%的时间会出现故障或异常,这种数据分布导致梯度下降算法在训练时面临“样本不均衡”的困境——模型会过度关注正常数据,而对异常状态的识别能力极弱。
节能减排与低碳出行及绿色信息网热度持续走高,行业关注度持续提升 2026年5月,国内某钢铁企业就吃过这样的亏,他们用数字孪生系统监控高炉运行,试图通过梯度下降优化炉温控制参数,但运行半年后发现,模型对“炉温异常升高”的预警延迟了近20分钟——因为训练数据中异常样本太少,算法根本没“学会”如何快速识别这种极端情况,企业不得不重新设计数据采样策略,专门增加异常工况的模拟数据,才让模型勉强达标。
数据时变性:昨天的“最优解”可能是今天的“陷阱”
工业设备的运行状态会随时间、环境、负载等因素动态变化,一台风力发电机的功率输出会受风速、温度、叶片磨损程度等多重因素影响,这些因素本身又在不断变化,梯度下降算法假设数据是“静态”或“准静态”的,但在工业场景中,这种假设往往不成立。
2026年需求响应与植物保护及公益项目热度持续攀升,相关应用不断深化 2026年8月,欧洲某风电运营商公布了一组令人震惊的数据:他们部署的数字孪生系统在春季(风速稳定、温度适宜)时预测准确率高达92%,但到了夏季(高温、雷暴频发)准确率骤降至68%,原因很简单——梯度下降算法找到的“最优参数”是基于春季数据训练的,到了夏季,设备运行特性已发生显著变化,旧模型自然“失效”了。

数据高维性:当参数从10个变成1000个……
现代工业设备的复杂度远超想象,一台高端数控机床可能有上千个传感器,每个传感器采集的数据维度(如温度、压力、振动频率等)又可能达到数十个,这意味着,数字孪生模型的输入参数可能高达数万维,梯度下降算法在处理高维数据时,会面临“维度灾难”——计算量呈指数级增长,收敛速度极慢,甚至无法收敛。
空气净化与碳排放及养生保健热度持续攀升,相关应用不断深化 2026年11月,美国通用电气(GE)在一份技术白皮书中披露:他们为某型航空发动机开发的数字孪生模型,初始版本包含12,000个输入参数,用梯度下降算法训练时,单次迭代需要计算1.2亿次梯度,耗时超过12小时,更糟糕的是,由于参数间存在强耦合性,模型训练了两周仍未收敛,GE不得不采用“参数降维+分块训练”的策略,才让模型勉强可用。
突破困境:工业数字孪生的“非梯度下降”路径
面对梯度下降在工业场景的“水土不服”,一些领先企业已经开始探索新的技术路径,这些路径的核心逻辑很简单:放弃“一刀切”的通用算法,转而针对工业数据的特殊性设计专用优化方法。
强化学习:让模型在“试错”中成长
与梯度下降依赖“标注数据”不同,强化学习通过“环境交互+奖励反馈”的方式让模型自主学习,在工业场景中,这可以理解为:让数字孪生模型不断“尝试”不同的控制参数,然后根据实际运行效果(如能耗、良品率)调整策略。

2026年7月,日本丰田汽车公布了一项突破性成果:他们在某条汽车装配线上部署了基于强化学习的数字孪生系统,该系统通过模拟10,000种不同的生产参数组合,并在虚拟环境中评估每种组合的“奖励值”(如生产效率、质量缺陷率),最终找到了一套比传统梯度下降优化方案更优的参数组合,实际运行显示,该方案使生产线效率提升了18%,而梯度下降方案仅提升了7%。
贝叶斯优化:用“概率”对抗不确定性
工业数据的另一个特点是“不确定性高”——传感器噪声、环境干扰、设备老化等因素都会导致数据波动,贝叶斯优化通过构建“概率模型”来描述这种不确定性,并利用“采集函数”在探索(尝试新参数)和利用(使用已知最优参数)之间找到平衡。
2026年9月,国内某半导体企业分享了他们的实践案例:在晶圆制造过程中,他们用贝叶斯优化替代梯度下降来调整光刻机的曝光参数,传统梯度下降方案需要采集超过10,000组数据才能收敛,而贝叶斯优化仅用了200组数据就找到了全局最优解,且优化后的参数使晶圆良品率提升了3.2个百分点。
物理信息神经网络(PINN):让数据与物理规律“双驱动”
工业设备的运行往往遵循严格的物理规律(如热力学、流体力学),物理信息神经网络(PINN)通过将物理方程作为约束条件嵌入神经网络训练过程,使模型既能利用数据学习,又能遵循物理规律,从而显著提升泛化能力。
2026年12月,德国西门子公布了一项令人瞩目的成果:他们为某型燃气轮机开发的数字孪生模型,采用了PINN架构,该模型不仅使用了传感器数据,还嵌入了燃气轮机的热力学方程,实际运行显示,在数据量仅为传统梯度下降方案1/10的情况下,PINN模型的预测精度反而提高了15%,且对极端工况的适应性更强。
回归本质:工业数字孪生的“价值锚点”
当我们在讨论梯度下降的局限性时,本质上是在探讨一个更根本的问题:工业数字孪生的核心价值究竟是什么?是追求模型预测的“绝对精度”,还是解决实际业务中的“关键痛点”?
2026年,越来越多的企业开始意识到:数字孪生不是“技术炫技”,而是“业务赋能”,在某化工企业的案例中,他们没有追求用数字孪生模型精确预测反应釜的温度曲线(这需要海量数据和复杂算法),而是聚焦于一个更实际的问题:如何通过调整进料速度,避免反应釜因温度过高而触发安全联锁(这会导致生产中断),他们用简单的回归模型(而非梯度下降优化的神经网络)结合少量历史数据,就开发出了一个能提前10分钟预警安全风险的数字孪生应用,实际运行中成功避免了3次生产事故,年