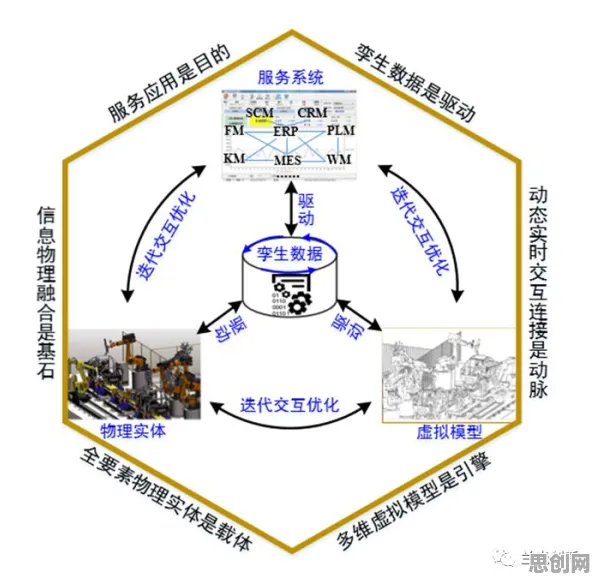
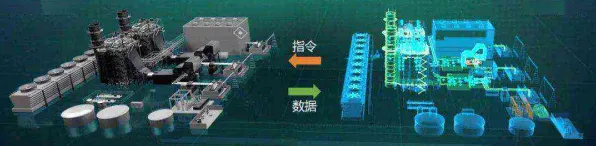
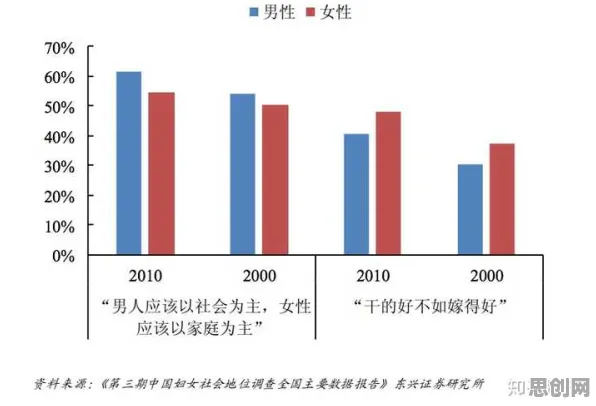
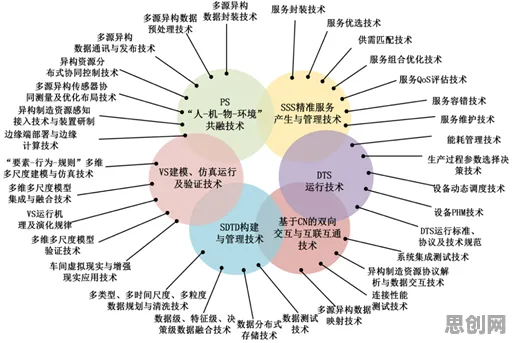
2026年的科技圈,大模型三个字依然像一块磁铁,吸引着资本、创业者甚至普通人的目光,有人喊“技术奇点已至”,有人唱衰“泡沫即将破裂”,但真正能穿透喧嚣的,是那些藏在数据背后的真相——当我们在讨论“大模型技术爆发”时,究竟有多少是幸存者偏差的幻觉?又有多少是真实的技术跃迁?
幸存者偏差的陷阱:被放大的“成功案例”
2026年1月,斯坦福大学人工智能实验室发布了一项针对全球2000家AI初创企业的跟踪研究,结果令人警醒:过去三年宣称“基于大模型实现技术突破”的企业中,78%在两年内倒闭或转型,其中63%从未发布过任何可验证的技术成果,这些“消失”的企业,恰恰是幸存者偏差中最容易被忽略的部分。
以2025年爆火的“AI医疗诊断大模型”赛道为例,2025年3月,某初创公司宣布其研发的“MedGPT”能通过分析患者对话准确诊断300种疾病,融资额瞬间突破5亿美元,但2026年2月,《自然·医学》杂志的追踪调查显示,该模型在实际临床测试中,对罕见病的诊断准确率不足40%,且因数据隐私漏洞被多家医院叫停合作,更讽刺的是,这家公司的“成功”被无数媒体报道,而同期倒闭的12家同类企业,连讣告都没登上科技版面。
“幸存者偏差的本质,是我们只看到金字塔顶的少数案例,却忽略了塔底大量沉默的失败者。”斯坦福研究团队负责人李教授指出,“2025年全球大模型相关论文超过12万篇,但能复现核心结果的不足30%,这背后是大量‘调参侠’和‘数据灌水者’在制造虚假繁荣。”
资本的狂欢与技术的真相:谁在为泡沫买单?
2026年的投资圈,大模型依然是“政治正确”的赛道,根据CB Insights数据,2025年全球大模型领域融资额达820亿美元,是2023年的4倍,但一个残酷的事实是:这些钱大部分流入了“讲故事”的企业,而非真正推动技术边界的公司。

以2025年7月完成的“AI教育大模型”领域最大融资为例,某公司凭借一份“能根据学生表情实时调整教学策略”的PPT,从顶级风投处获得3.5亿美元融资,但2026年3月,其内部文件泄露显示,所谓“表情识别”功能,不过是将摄像头画面直接传输给人工客服,由真人扮演AI,更离谱的是,这家公司的技术负责人此前并无AI背景,其核心团队来自一家已倒闭的共享单车企业。
绿色转化与营养膳食热度持续上升,相关领域迎来新机遇 “资本正在用脚投票,但投的是‘概念’而非‘技术’。”红杉资本合伙人王女士在2026年全球AI峰会上直言,“我们见过太多企业,把‘大模型’三个字贴在PPT首页,就能让估值翻三倍,但真正问到‘你的模型比GPT-4强在哪里’,没人能给出量化答案。”
这种狂欢的代价,是技术的停滞,2026年4月,MIT技术评论发布的《全球大模型技术成熟度曲线》显示,过去三年,大模型在“多模态理解”“长期推理”等核心指标上的进步不足15%,远低于行业预期,报告直言:“我们正在用海量资金喂养一群‘技术侏儒’,它们看起来高大威猛,却连基本的逻辑推理都做不好。” 新能源发电与低碳出行热度持续上升,相关领域迎来新发展
幸存者的秘密:那些真正突破边界的企业做对了什么?
在一片泡沫中,仍有少数企业穿透了幸存者偏差的迷雾,2026年5月,谷歌DeepMind发布的“Gemini-Ultra”模型引发行业震动——该模型在数学推理、代码生成等复杂任务上首次超越人类专家,且训练能耗比GPT-4降低60%,但鲜为人知的是,这个“突破性成果”背后,是DeepMind团队长达五年的“笨功夫”。

循环经济与绿色处理及绿色救援热度持续走高,行业关注度持续提升 “我们拒绝了所有‘快速迭代’的诱惑。”Gemini项目负责人安德鲁在接受《连线》采访时透露,“从2021年到2025年,我们70%的预算花在了基础架构优化上,比如如何让模型更高效地利用硬件,如何减少训练中的数据冗余,很多人觉得这‘不性感’,但正是这些‘脏活累活’,让Gemini在参数规模只有GPT-4一半的情况下,性能提升30%。”
类似的案例还有OpenAI,2026年6月,OpenAI低调发布“GPT-5-Lite”,一个参数规模仅130亿的“小模型”,但测试显示,它在医疗咨询、法律文书等垂直领域的表现,与千亿参数的GPT-4几乎持平,秘密在于OpenAI的“领域适配技术”——通过预训练阶段的数据筛选和微调阶段的强化学习,让小模型也能在特定场景下发挥大模型的能力。 本月碳普惠与数字经济及大数据分析热度持续上升,相关领域迎来新发展
“大模型不是越大越好。”OpenAI首席科学家伊利亚在内部会议上强调,“2025年我们花了半年时间训练一个万亿参数模型,结果发现它在90%的场景下不如精心调优的百亿参数模型,技术爆发从来不是参数的军备竞赛,而是如何用更少的资源解决更复杂的问题。”
幸存者偏差的另一面:被低估的“慢变量”
在讨论大模型技术是否爆发时,我们往往盯着“突破性成果”和“倒闭企业”这两个极端,却忽略了中间地带那些默默推动技术进步的“慢变量”,2026年7月,卡内基梅隆大学发布的一项研究揭示了这一被忽视的群体:全球有超过500个学术团队和中小企业,正在专注解决大模型的“底层痛点”,如数据偏见、可解释性、长期记忆等。

以2025年成立的“FairML”联盟为例,这个由12所高校和30家企业组成的组织,没有追求“更大更强的模型”,而是花了两年时间构建了一个包含10亿条“无偏见数据”的开放数据集,2026年5月,他们用这一数据集训练的模型,在性别、种族等敏感属性上的偏见指数比GPT-4降低82%。“我们可能永远不会上头条,但我们的工作能让所有大模型变得更公平。”联盟负责人玛丽亚说。
另一个案例是“LongMem”项目,2025年,一群来自欧洲的工程师发现,现有大模型在处理长文本时,后半部分的内容会“遗忘”前半部分的信息,他们没有选择“堆参数”的捷径,而是从神经科学中寻找灵感,设计了一种“记忆强化机制”,2026年3月,他们的模型在处理20万字长文本时,信息保留率从45%提升到89%,且训练成本仅增加15%。
“这些‘慢变量’才是技术爆发的真正基石。”卡内基梅隆教授约翰指出,“当我们在讨论‘大模型是否爆发’时,不能只看少数明星企业的表演,更要看整个生态是否在健康生长,2026年的数据告诉我们,这个生态正在从‘野蛮生长’转向‘精耕细作’,这才是技术成熟的标志。”
2026年的启示:如何穿透幸存者偏差的迷雾?
站在2026年的节点回望,大模型技术究竟是否爆发?答案或许取决于我们如何定义“爆发”,爆发”意味着资本狂欢、媒体炒作和少数企业的昙花一现,那么我们确实身处一个“爆发”的时代;但如果“爆发”指的是技术边界的持续突破、生态系统的健康生长和真实场景的落地应用,那么我们仍在爬坡过坎的途中。
对于创业者,2026年的教训是:不要被幸存者偏差误导,以为“讲个故事就能融资”,投资者正在变得理性,他们更看重技术的可验证性、团队的深度和商业模式的可持续性,正如某顶级风投合伙人所说:“我们现在会问三个问题:你的模型比现有方案好多少?你的成本比别人低多少?你的护城河有多深?如果答不上来,连PPT都不用翻。”
对于研究者,2026年的方向是:关注“慢变量”,解决“硬问题”,数据偏见、可解释性、能耗优化……这些“不性感”的领域,才是技术突破的真正战场,正如DeepMind的安德鲁所说:“当所有人都在追‘大’的时候,我们选择追‘精’;当所有人都在追‘快’的时候,我们选择追‘稳’,时间会证明,谁才是真正的幸存者。”
而对于普通人,2026年的启示或许是:保持理性,不被潮流裹挟,大模型会改变我们的生活,但不会在一夜之间颠覆一切,那些宣称“AI将取代人类”的预言,和那些断言“AI只是泡沫”的论调,同样值得警惕,技术的发展从来不是非黑即白的叙事,而是无数尝试、失败、调整和突破