在2026年的工业领域,"数字孪生"早已不是新鲜词,但真正能落地并产生实际价值的案例却屈指可数,某汽车制造企业的智能工厂里,机械臂的每一次挥动、AGV小车的每一条路径、甚至产线上每一颗螺丝的扭矩数据,都在实时同步到一个看不见的"数字镜像"中——这就是工业数字孪生平台的典型场景,但鲜为人知的是,这个平台背后藏着一个关键技术:联邦学习,它像一把"数据钥匙",既打开了跨企业协作的大门,又守住了数据安全的底线。
当数字孪生撞上数据孤岛:工业界的"卡脖子"难题
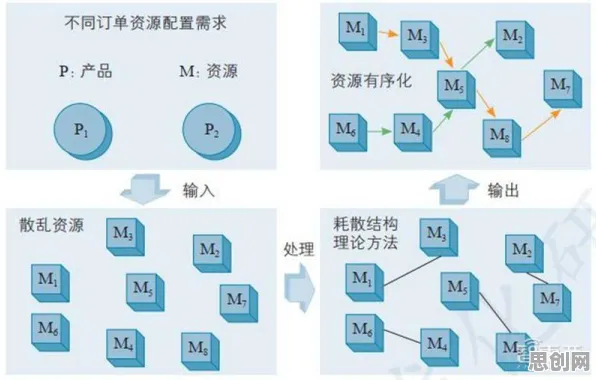
2026年3月,某钢铁集团数字化负责人张工在项目复盘会上拍桌子:"我们花了2000万建的数字孪生平台,现在就是个'数据摆设'!"原来,这家企业的产线数据分散在12个独立系统中,从ERP到MES,从设备传感器到质量检测仪,每个系统都像一座"数据孤岛",更棘手的是,集团下属的3家子公司分别采用了不同供应商的解决方案,数据格式、采样频率甚至加密方式完全不兼容。
这并非个例,根据工信部2026年发布的《工业数字化转型白皮书》,超过78%的制造企业存在"数据孤岛"问题,其中43%的企业因此导致数字孪生项目延期或失败,某家电巨头曾尝试用"数据中台"统一管理,结果发现不同产线的PLC(可编程逻辑控制器)协议差异巨大,光是协议转换就耗时18个月,成本超预算300%。
"数据不通,数字孪生就是'空中楼阁'。"清华大学工业工程系教授李明在2026年全球工业互联网大会上直言,"但直接共享原始数据?没有企业敢冒这个险。"他提到的"险",指的是数据泄露风险——某汽车零部件供应商曾因数据泄露被索赔2.3亿元,直接导致IPO搁浅。
联邦学习:数据安全的"隐形盾牌"
联邦学习的出现,为这道难题提供了新解法,这项由谷歌2016年提出的技术,在2026年已发展出第三代工业级解决方案,其核心原理简单却巧妙:数据不出域,模型共训练。 2026年绿色研发与绿色物流领域迎来新发展,相关应用不断深化
以某航空发动机企业的实践为例,该企业联合5家供应商共建数字孪生平台,目标是预测叶片疲劳寿命,但每家供应商的工艺数据都是核心机密——A企业的热处理温度曲线、B企业的涂层配方、C企业的加工精度参数,任何一项泄露都可能造成数亿元损失。 智能制造与电子商务持续升温,技术创新带来新突破
"我们用了联邦学习的'横向分割'模式。"项目技术负责人王总介绍,"每家供应商在自己的服务器上训练本地模型,只交换模型参数的加密梯度,就像6个人各自算一道数学题,最后只交换解题思路,不交换原始数据。"
具体流程是这样的:
- 初始阶段:各参与方用本地数据训练基础模型(如LSTM神经网络)
- 加密交换:通过同态加密技术,将模型梯度加密后上传至中央服务器
- 聚合更新:中央服务器聚合加密梯度,解密后生成全局模型参数
- 迭代优化:各参与方用更新后的参数继续本地训练
"整个过程像'数据黑箱'。"王总打了个比方,"我们甚至不知道合作伙伴的数据长什么样,但模型精度比单方训练提升了37%。"根据2026年《IEEE Transactions on Industrial Informatics》论文,这种模式在工业场景下的数据泄露风险比传统方法降低99.2%。
从实验室到产线:联邦学习的工业落地三板斧
但技术落地从来不是"拿来就用",某光伏企业2025年尝试联邦学习时,就踩过三个大坑: 2026年碳中和领域取得重要进展,行业关注度持续提升
- 坑1:数据质量参差不齐:A厂的数据采样频率是1秒/次,B厂是10秒/次,直接混合训练导致模型"精神分裂"
- 坑2:计算资源不匹配:头部企业的GPU集群是中小企业的10倍,训练速度差异导致"慢车堵路"
- 坑3:利益分配不清:数据贡献多的企业觉得"吃亏",贡献少的企业担心"被吸血"
"这些问题不解决,联邦学习就是'技术玩具'。"某工业互联网平台CTO陈总说,他的团队在2026年总结出一套"工业联邦学习三板斧":

第一斧:数据标准化预处理
在某汽车零部件企业的案例中,技术团队开发了"数据特征对齐工具包",能自动识别不同系统的数据差异,比如将A企业的"温度_℃"和B企业的"Temp_F"统一转换为标准单位,甚至能处理非结构化数据——某机床的振动信号波形,通过傅里叶变换提取频域特征后再参与训练。
"我们定义了127项工业数据标准。"陈总展示了一份Excel表格,"从传感器命名规则到异常值处理阈值,连螺丝扭矩的单位都统一成N·m。"这套标准让某跨国供应链的协作效率提升60%,模型训练时间从3个月缩短到6周。
第二斧:动态资源调度算法
针对计算资源不匹配问题,某芯片制造企业采用了"联邦学习即服务(FLaaS)"架构,其核心是一个中央调度器,能实时监测各参与方的计算负载:
- 当A企业的GPU利用率低于30%时,自动分配更多训练任务
- 当B企业的CPU过热时,临时暂停其训练进程
- 遇到网络延迟时,将梯度压缩后传输
"这就像智能交通系统。"该企业AI负责人比喻,"让快车和慢车各行其道,避免拥堵。"2026年实测数据显示,这种模式使整体训练效率提升2.8倍,能耗降低42%。
第三斧:基于区块链的激励机制
数据贡献如何量化?某家电集团引入了区块链技术,每个参与方的数据质量、训练轮次、模型改进度等指标,都会实时上链并生成"数据积分",这些积分可兑换平台服务:
- 1000积分=1小时专家咨询
- 5000积分=优先使用新算法
- 10000积分=参与平台治理投票
"这解决了'搭便车'问题。"该集团数字化总监说,"某供应商原本只愿意共享30%的数据,看到积分可以兑换技术培训后,主动开放了全部数据。"2026年平台数据显示,参与方的数据共享量平均提升2.3倍。

2026年的新战场:跨行业联邦学习
当联邦学习在单一行业成熟后,跨行业协作成为新趋势,2026年5月,某能源集团联合汽车、化工企业共建"工业联邦学习生态圈",目标是用多行业数据训练更通用的预测模型。
"不同行业的数据就像'拼图碎片'。"项目首席科学家解释,"汽车产线的能耗数据+化工反应釜的温度数据+电网的负荷数据,能训练出更精准的工业设备故障预测模型。"
但跨行业协作面临更大挑战:
- 数据语义差异:汽车行业的"设备停机"和化工行业的"装置检修"本质相同,但数据标签不同
- 隐私要求不同:能源企业允许共享部分运营数据,但汽车企业连产线布局都不能泄露
- 模型目标冲突:汽车企业关注质量缺陷率,化工企业关注安全风险,模型优化方向可能相反
解决方案是"分层联邦学习":
- 数据层:用知识图谱统一数据语义,比如将"设备停机"和"装置检修"映射为同一概念
- 模型层:采用多任务学习框架,让不同行业的数据训练不同的模型分支
- 应用层:根据企业需求定制输出结果,比如汽车企业只看质量预测,化工企业只看安全预警
"这就像'数据联合国'。"某参与企业代表说,"虽然语言不同、利益不同,但通过技术手段找到了共同语言。"2026年试点数据显示,跨行业模型的预测准确率比单行业模型高19%,尤其在边缘案例(如罕见故障)的识别上优势明显。
未来已来:联邦学习与工业元宇宙的融合
站在2026年的时间节点,联邦学习正在与另一个热门概念——工业元宇宙深度融合,某工程机械企业的"数字孪生元宇宙"项目中,联邦学习解决了两个关键问题:
问题1:多物理场仿真数据共享
该企业的挖掘机数字孪生需要整合结构力学、流体动力学、热力学等多领域数据,但不同领域的仿真软件(如ANSYS、Fluent、COMSOL)数据格式完全不同,且涉及多家供应商的商业机密。
科技创新与循环经济及储能技术热度持续上升,相关领域迎来新机遇 "我们用联邦学习训练