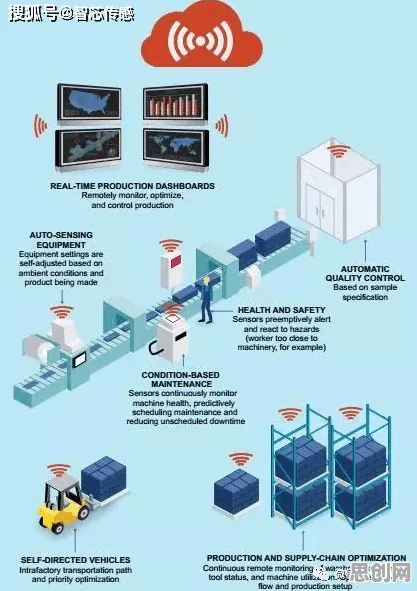
在工业4.0的浪潮中,数字孪生体(Digital Twin)早已不是新鲜概念,从德国的“工业4.0战略”到中国的“智能制造2025”,从航空航天到汽车制造,数字孪生技术被反复提及,成为企业数字化转型的“标配”,但当我们翻开各类行业报告、技术论坛的分享案例时,会发现一个普遍现象:大多数人对数字孪生的理解仍停留在“虚拟建模”的表面——用3D模型还原物理设备,用传感器数据驱动虚拟体运动,再通过可视化界面展示运行状态,这种“数字镜像”的展示固然直观,却忽略了数字孪生最核心的价值:通过分类算法对海量数据进行深度挖掘,实现从“被动监控”到“主动预测”的跨越。
2026年,我在走访长三角、珠三角的多家制造业企业时,发现一个典型误区:某汽车零部件厂商投入数百万元搭建了数字孪生平台,将生产线上的200多台设备全部建模,传感器数据实时上传至云端,大屏上跳动着设备温度、振动频率等参数,但当问及“这套系统如何帮助降本增效”时,负责人挠头:“目前主要用来远程查看设备状态,故障预警还是靠人工经验,数字孪生好像没发挥太大作用。”类似的场景在化工、电子、装备制造等行业普遍存在——企业花了大价钱建平台,却只用了“数字镜像”的10%功能,而真正能创造价值的90%(即基于分类算法的智能分析)却被闲置。 关注在线教育与低碳办公及储能材料发展动态,技术创新推动产业升级
分类算法:数字孪生的“大脑”
数字孪生的本质是“数据+模型+算法”的三位一体。“数据”是基础,“模型”是载体,而“算法”才是灵魂,没有算法的数字孪生,就像一台没有操作系统的电脑,只能显示静态画面,无法运行复杂程序,而在所有算法中,分类算法(Classification Algorithm)是最关键的一环——它负责对设备运行数据、环境数据、质量数据等进行分类标注,识别出“正常状态”与“异常状态”的边界,进而为故障预测、工艺优化、能耗管理等提供决策依据。
本月关注产业升级与绿色电力及数字鸿沟发展动态,技术创新推动产业升级 以2026年某钢铁企业的热轧生产线为例,该企业引入数字孪生技术后,最初仅用于监控轧机的温度、压力、速度等参数,故障预警依赖人工设定的阈值(如温度超过300℃报警),但实际生产中,设备故障往往不是由单一参数超标引起,而是多个参数的“组合异常”,当轧机温度在280-290℃、振动频率在15-20Hz、电流波动超过5%时,虽然每个参数都在阈值内,但组合起来可能预示着轴承磨损,传统阈值报警无法捕捉这种复杂模式,导致故障漏报率高达30%。
2026年3月,该企业与某AI公司合作,引入基于分类算法的数字孪生系统,算法团队首先收集了过去3年轧机的历史数据,包括正常运行时的参数组合和故障发生时的参数组合,通过监督学习(如随机森林、XGBoost)训练出分类模型,该模型能自动识别“正常”与“异常”的数据模式,并给出异常类型(如轴承磨损、液压系统泄漏、电气故障等),上线后,系统在1个月内成功预警了5起潜在故障,其中3起是传统方法无法检测的“组合异常”,避免直接经济损失超200万元,更关键的是,分类算法能将故障类型细化到具体部件(如“轧机右侧轴承内圈磨损”),维修人员可提前准备备件,将停机时间从原来的4小时缩短至1.5小时。
从“故障后维修”到“故障前预防”:分类算法的实践价值
分类算法的价值不仅体现在故障预警,更在于推动工业维护模式从“被动维修”向“预测性维护”转型,2026年5月,我在深圳某半导体封装企业看到另一组数据:该企业的固晶机是核心设备,故障停机1小时会导致整条生产线停摆,损失超50万元,过去,企业采用“定期维护”策略,每3个月拆机检查一次,但这种“一刀切”的方式既浪费人力(每次维护需4人/8小时),又可能因过度维护导致设备寿命缩短。

引入数字孪生系统后,企业重点优化了分类算法,算法团队针对固晶机的关键部件(如焊头、供料系统、运动平台),收集了温度、压力、位移、电流等100多个参数,并通过无监督学习(如聚类分析)识别出不同部件的“健康状态模式”,焊头的正常工作模式是“温度稳定在200-220℃、振动频率低于50Hz、电流波动小于2%”,当数据偏离该模式时,系统会标记为“潜在异常”,进一步,通过监督学习训练分类模型,将异常分为“轻度磨损”“中度磨损”“严重故障”三类,并对应不同的维护策略:轻度磨损时增加润滑;中度磨损时调整参数;严重故障时立即停机更换部件。
2026年第二季度,该系统共识别出127次潜在异常,其中89次被分类为“轻度磨损”,通过调整参数解决;23次为“中度磨损”,安排计划性维护;15次为“严重故障”,提前停机更换部件,固晶机的故障率下降62%,维护成本降低35%,设备综合效率(OEE)提升18%,更值得关注的是,分类算法的“自学习”能力——随着数据积累,模型能自动优化分类边界,适应设备老化、工艺变更等动态变化,无需人工频繁调整参数。 本月出版发行热度飙升,相关产业迎来新机遇
分类算法的“隐形战场”:数据质量与标注
分类算法并非“万能药”,其效果高度依赖数据质量与标注,2026年7月,我在苏州某装备制造企业遇到一个反面案例:该企业为数控机床搭建了数字孪生系统,引入了先进的分类算法,但上线3个月后预警准确率不足50%,甚至出现“正常状态被误报为故障”的乌龙事件,问题出在哪里?

深入调查发现,企业的历史数据存在两大问题:一是数据缺失率高,部分传感器的采样频率不足(如温度传感器每10分钟记录一次,而故障可能在1分钟内发生);二是数据标注混乱,故障发生时的参数组合未明确标注故障类型(如“轴承损坏”与“电气故障”的数据混在一起),导致算法无法学习到准确的分类边界,某次故障发生时,温度为285℃、振动为18Hz,但标注人员仅记录“设备故障”,未说明是轴承问题,算法将该数据归为“异常”大类,却无法细分到具体部件,预警时只能提示“设备可能有问题”,维修人员仍需现场排查。
为解决这一问题,企业与数据标注团队合作,对过去2年的历史数据进行重新标注:首先明确故障类型(如轴承磨损、电气短路、液压泄漏等),再标注故障发生时的具体参数组合,最后通过人工校验确保标注准确性,升级传感器网络,将关键参数的采样频率提升至每1分钟一次,并增加冗余传感器(如在轴承部位同时安装温度、振动、声学传感器),避免单点数据失效,经过3个月的数据清洗与标注,分类算法的预警准确率提升至92%,误报率降至5%以下。
分类算法的未来:从“单设备”到“全产线”
当前,大多数数字孪生应用仍聚焦于单台设备,但2026年的趋势是向“全产线数字孪生”延伸——将分类算法从设备级扩展到产线级,实现跨设备、跨工序的数据关联分析,在汽车焊接产线中,一台机器人的故障可能引发上下游设备的连锁反应(如焊接电流异常导致车身变形,进而影响后续的涂装工序),传统数字孪生系统只能孤立分析每台设备的数据,而基于分类算法的全产线孪生系统能识别设备间的“因果关系”,预测故障的传播路径。
2026年9月,某新能源汽车厂商在杭州的工厂试点全产线数字孪生系统,该系统覆盖冲压、焊接、涂装、总装四大工序的2000多台设备,通过分类算法构建“设备关联图谱”:当某台焊接机器人的电流波动超过阈值时,系统不仅会预警该机器人可能故障,还会分析其对下游涂装工序的影响(如车身表面凹凸不平可能导致涂装厚度不均),并给出调整建议(如降低焊接速度、增加涂装喷枪压力),试点期间,系统成功预测了3起跨工序故障传播事件,避免因单点故障导致的整条产线停机,产线综合效率提升12%。
别让数字孪生沦为“花瓶”
回到最初的问题:为什么大多数人对工业数字孪生体的应用案例 绿色交通领域取得重要进展,行业关注度持续提升