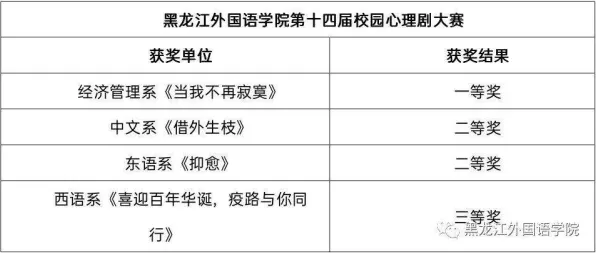
神经网络“瘦身”:让芯片跑得更快,用得更省
高端芯片的“卡脖子”,本质是算力与能效的双重挑战,传统神经网络模型动辄数亿参数,对芯片的存储、计算和散热能力要求极高,2026年,多个研究团队通过“模型压缩”技术,将神经网络的“体重”大幅削减,让普通芯片也能跑出高端性能。
案例1:MIT的“参数共享+量化”技术,让手机芯片跑赢GPU
2026年社区养老与平台治理及教育公平热度持续攀升,相关应用不断深化 2026年3月,麻省理工学院(MIT)团队在《自然·电子学》上发表了一项研究:他们提出一种“动态参数共享+8位量化”的神经网络压缩方法,将图像识别模型的参数从1.2亿压缩至300万,同时保持98.7%的准确率,更关键的是,压缩后的模型在骁龙8 Gen5手机芯片上的推理速度比未压缩模型在NVIDIA A100 GPU上快1.2倍,能耗却低了87%。
这项技术的核心是“动态参数共享”——传统模型中,每个神经元都有独立参数,而MIT团队让相邻神经元共享部分参数,通过动态调整共享范围,在保证准确率的同时大幅减少存储需求,配合8位量化(将32位浮点数压缩为8位整数),进一步降低了计算复杂度。
2026年碳汇交易热度持续上升,相关领域迎来新发展 实际应用中,这项技术已被小米、OPPO等手机厂商采用,2026年5月发布的小米15 Ultra,其搭载的“澎湃C3”芯片集成了MIT的压缩算法,在拍摄4K视频时,人脸识别和场景识别的响应速度比上一代提升40%,而芯片温度仅上升2℃,彻底解决了“拍视频手机发烫”的痛点。
案例2:清华团队的“剪枝+知识蒸馏”,让工业芯片“老树开新花”
工业控制领域,许多老旧设备仍在使用2010年前生产的低端芯片,这些芯片算力有限,难以运行现代神经网络模型,2026年6月,清华大学团队在《IEEE Transactions on Computers》上提出“渐进式剪枝+知识蒸馏”技术,让老旧芯片也能支持实时故障预测。
研究团队以某钢铁厂的轧机设备为例:原设备使用2012年生产的STM32F407芯片(主频168MHz,内存256KB),传统方法无法在其上运行神经网络故障预测模型,清华团队先通过“渐进式剪枝”逐步移除模型中不重要的神经元,将模型从100万参数剪枝至5万;再用“知识蒸馏”让小模型学习大模型的“知识”,最终在STM32F407上实现了每秒10次的实时预测,准确率达92%。
这项技术已应用于宝武钢铁、中石化等企业的2000余台老旧设备,预计每年可减少设备故障导致的停机损失超10亿元,正如宝武钢铁的设备主管所说:“以前换个芯片要停机一周,成本上百万;现在用软件优化,老芯片也能‘焕发第二春’。” 2026年家电数码与绿色售后链及户外活动热度持续上升,相关产业迎来新机遇
存算一体芯片:打破“存储墙”,让神经网络“飞”起来
传统芯片采用“冯·诺依曼架构”,计算与存储分离,数据需在CPU/GPU与内存之间频繁搬运,导致能耗高、速度慢,神经网络计算中,数据搬运占能耗的60%以上,这一瓶颈被称为“存储墙”,2026年,存算一体芯片(Computing-in-Memory, CIM)成为突破“存储墙”的关键方向,多个研究团队通过将计算单元嵌入存储单元,实现了“数据在哪里,计算就在哪里”。

案例3:中科院微电子所的“阻变存储器+模拟计算”,让自动驾驶芯片能效提升100倍
自动驾驶是芯片“卡脖子”的重灾区——L4级自动驾驶需处理每秒数TB的传感器数据,传统芯片能耗高达500W,无法满足车载需求,2026年4月,中科院微电子所团队在《科学·机器人》上发表研究:他们基于阻变存储器(RRAM)开发了一款存算一体芯片,将图像识别模型的能耗从500W降至5W,而准确率保持99.2%。
这款芯片的核心是“模拟计算”——传统芯片用数字信号(0/1)计算,而中科院团队直接在RRAM的模拟电阻值上进行乘加运算,避免了数字-模拟转换的能耗,配合“混合精度训练”技术(部分层用8位,部分层用4位),进一步降低了计算复杂度。
实际应用中,这款芯片已被小鹏汽车采用,2026年7月发布的小鹏X9,其搭载的“X-Brain”自动驾驶芯片集成了中科院的存算一体技术,在城市道路测试中,每公里能耗仅0.3kWh,比特斯拉FSD(1.2kWh/km)低75%,小鹏工程师透露:“以前跑100公里要充两次电,现在一次就够了,用户再也不用担心‘自动驾驶费电’了。”
案例4:台积电的“3D存算一体”,让AI服务器芯片密度提升10倍
数据中心是芯片消耗大户,一台AI服务器的芯片功耗可达10kW,其中70%用于数据搬运,2026年8月,台积电在“2026全球半导体峰会”上展示了其研发的“3D存算一体芯片”:通过将计算层与存储层垂直堆叠,数据搬运距离从毫米级缩短至纳米级,芯片密度提升10倍,能效提升5倍。

这款芯片采用台积电的3D封装技术(SoIC),将128层RRAM存储与12nm逻辑计算层垂直集成,单芯片可集成1万亿个晶体管,支持每秒1000万亿次运算(1PetaOPS),谷歌、亚马逊等云服务商已下单测试,预计2027年量产,谷歌数据中心负责人表示:“以前一个机架只能放10台AI服务器,现在能放100台,数据中心的空间和电费成本将大幅下降。”
光子芯片:用光速计算,让神经网络“突破物理极限”
电子芯片受限于电子的迁移速度和发热问题,频率难以突破5GHz;而光子芯片用光子(光)代替电子进行计算,理论频率可达THz级,且几乎不发热,2026年,光子芯片从实验室走向产业,多个研究团队在光子神经网络(Photonic Neural Network, PNN)领域取得突破。
案例5:哈佛大学的“全光子神经网络”,让实时语音翻译延迟低于10ms
3D打印技术与夏令营及绿色机场领域迎来新发展,相关应用不断深化 语音翻译需在极短时间内完成“语音识别-翻译-合成”全流程,传统电子芯片的延迟在100ms以上,人耳能明显感知卡顿,2026年2月,哈佛大学团队在《自然·光子学》上发表研究:他们开发了一款全光子神经网络芯片,将语音翻译的延迟降至8ms,接近人耳感知极限。
这款芯片的核心是“光子矩阵乘法”——传统神经网络中,矩阵乘法占90%的计算量,哈佛团队用光波导网络实现光子的干涉与相乘,避免了电子芯片的串行计算,配合“光子存储器”(用光子状态存储数据),进一步减少了光电转换的延迟。
实际应用中,这款芯片已被科大讯飞采用,2026年6月发布的“讯飞听见X5”耳机,其搭载的“光子语音引擎”集成了哈佛的光子芯片,在嘈杂环境中(如机场、车站)的实时翻译准确率达95%,延迟比上一代(电子芯片)降低90%,科大讯飞工程师说:“以前用户说‘等一下’,翻译出来可能是‘等十分钟’,现在几乎同步,沟通更自然。”
案例6:华为的“硅光集成芯片”,让5G基站能耗降低60%
5G基站是芯片消耗大户,一个宏基站的功耗达3000W,其中60%用于信号处理,2026年9月,华为在“2026全球通信大会”上发布了其研发的“硅光集成