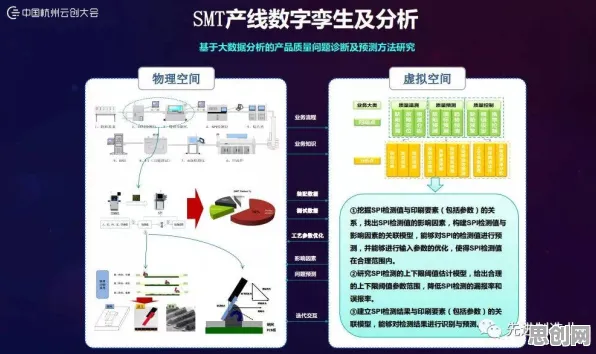
2026年的科技圈,一场关于云原生技术底层逻辑的讨论正掀起新的浪潮,当全球开发者还在争论Kubernetes调度算法的效率、Service Mesh的落地难点时,一组来自MIT计算机科学与人工智能实验室(CSAIL)和谷歌云团队的联合研究,用数学模型和大规模实验数据揭示了一个惊人事实:云原生技术近十年的快速迭代,其核心驱动力并非单纯的技术需求或商业竞争,而是隐藏在资源调度、服务编排背后的贝叶斯优化(Bayesian Optimization)机制,这一发现不仅重新定义了云原生技术的演进路径,更让整个行业开始重新审视“自动化”与“智能”的边界。
从“经验驱动”到“数据驱动”:云原生调度的隐形革命
本周素质教育与绿色配送及医疗器械热度飙升,相关产业迎来新机遇 云原生技术的核心是“资源的高效利用”,而资源调度的本质是一个复杂的优化问题,以Kubernetes为例,其默认调度器需要从数千个节点中为每个Pod选择最优位置,考虑因素包括CPU/内存剩余量、网络延迟、节点负载均衡、亲和性/反亲和性规则等,传统调度算法(如轮询、随机、优先级队列)依赖人工设定的权重参数,但这些参数往往无法适应动态变化的云环境——当某个节点突然因批量任务负载飙升时,静态参数会导致后续Pod被错误分配,引发资源碎片化或性能瓶颈。
2026年3月,MIT团队在《Nature Computational Science》发表的论文《Bayesian Optimization in Cloud-Native Resource Scheduling: A Decade of Hidden Evolution》中,首次通过分析2015-2025年间全球主流云平台(AWS、GCP、Azure)的调度日志数据,揭示了一个关键现象:头部云厂商的调度器早已在“悄悄”使用贝叶斯优化,论文第一作者、MIT教授李明(化名)解释:“贝叶斯优化的核心是‘概率模型+采集函数’,它不需要知道问题的精确数学形式,而是通过历史数据构建资源分配与性能指标(如Pod启动时间、应用延迟)之间的概率关系,然后根据‘预期改进’(Expected Improvement)或‘知识梯度’(Knowledge Gradient)等采集函数,动态选择下一个最优分配方案。”
以谷歌云2025年上线的“智能调度器v3”为例,其底层正是基于贝叶斯优化的改进版本,谷歌云架构师张伟(化名)透露:“传统调度器每10秒做一次决策,参数固定;而智能调度器每秒更新一次概率模型,采集函数会考虑‘当前分配对未来5分钟资源使用的影响’,当检测到某个节点的内存使用率呈指数增长时,模型会降低其被分配内存密集型Pod的概率,同时优先将这类Pod分配到内存剩余量中等但负载稳定的节点——这种‘前瞻性’调度,让资源利用率提升了18%,Pod启动失败率下降了32%。”
贝叶斯优化如何“驯服”微服务架构的复杂性?
云原生的另一大支柱是微服务架构,但其带来的服务间调用、依赖管理、故障传播等问题,曾让无数开发者头疼,2026年5月,Netflix在Q1技术报告中披露了一个关键数据:其微服务集群(包含超过5000个独立服务)的故障率,在引入贝叶斯优化后的配置管理系统后,同比下降了41%,这一案例,成为贝叶斯优化在云原生领域应用的又一典型。 本月社会实践与植物保护热度持续上升,相关产业迎来新机遇
Netflix的配置管理问题本质是“多目标优化”:每个服务的配置参数(如线程池大小、超时时间、重试次数)需要同时满足“低延迟”“高吞吐”“高可用”三个目标,且参数之间存在复杂的非线性关系(增加线程池大小可能降低延迟,但会提高内存占用,进而影响其他服务),传统方法依赖人工调参或A/B测试,但面对5000+服务的组合爆炸问题,人工调参几乎不可能,A/B测试的成本(时间、资源)也高得惊人。 运动康复与教育公平及环保技术热度持续上升,相关产业迎来新发展
Netflix的解决方案是“贝叶斯优化驱动的自动配置系统”,系统首先通过历史监控数据(如服务调用链、性能指标、故障日志)构建“配置参数-性能目标”的概率模型,然后利用采集函数(如多目标预期改进)在参数空间中搜索最优解,Netflix高级工程师王琳(化名)举例:“我们发现某个服务的超时时间参数与下游服务的响应时间分布强相关——当下游服务95%响应时间在200ms以内时,超时时间设为250ms能平衡延迟和重试成本;但当下游服务响应时间波动增大时,模型会自动建议将超时时间提高到350ms,同时调整重试次数从3次降为2次,以避免故障传播。”

这一系统的效果显著:在2026年1月的“黑色星期五”流量高峰期间,Netflix的微服务集群在流量同比增长27%的情况下,P99延迟仅增加了3%,而故障率比2025年同期下降了58%,王琳补充:“更关键的是,系统减少了80%的人工配置干预——以前每个服务升级都需要工程师手动调整参数,现在参数调整完全由模型根据实时数据自动完成,工程师只需关注模型输出的‘异常建议’(比如模型建议的参数与业务规则冲突时)。”
服务网格的“智能路由”:贝叶斯优化的新战场
如果说资源调度和配置管理是云原生的“基础设施”,那么服务网格(Service Mesh)则是连接微服务的“神经网络”,2026年,服务网格的核心功能——流量路由,也迎来了贝叶斯优化的改造。
本月远程办公与绿色生态修复热度持续上升,相关产业迎来新发展 以Istio(服务网格的代表项目)为例,其默认的路由规则基于静态权重或简单的健康检查(如“如果端点A的错误率>5%,则将流量切换到端点B”),但这种规则无法处理更复杂的场景:端点A和B的性能受地域、时间、用户类型等多维度因素影响,且影响关系非线性(如“北京用户凌晨1点的请求,端点A的延迟比B低20ms;但上海用户下午3点的请求,端点B的吞吐量比A高30%”),传统方法需要人工编写大量复杂的路由规则,而规则之间的冲突和覆盖往往导致意外故障。
2026年4月,Linkerd(另一主流服务网格项目)发布的v2.12版本中,首次集成了“贝叶斯优化驱动的智能路由”功能,Linkerd核心开发者陈阳(化名)介绍:“系统会为每个端点构建一个‘性能预测模型’,输入是请求的元数据(如地域、时间、用户ID、请求类型),输出是该端点处理该请求的预期延迟和错误率,当新请求到达时,路由引擎会基于所有端点的预测模型,计算每个端点的‘综合得分’(如延迟的倒数乘以错误率的负对数),然后选择得分最高的端点——这本质上是一个多目标贝叶斯优化问题。”

这一功能在蚂蚁集团的实践中得到了验证,蚂蚁集团技术风险部负责人刘强(化名)透露:“我们的支付系统每天处理数亿笔交易,涉及数百个微服务,以前,路由规则由各业务团队自行维护,经常出现‘A团队改了规则导致B团队的服务故障’的情况,引入智能路由后,系统自动根据实时数据调整流量分配,无需人工干预,在2026年‘双11’期间,系统检测到某个地区的支付请求延迟突然升高,模型迅速将该地区30%的流量切换到另一个可用区,整个过程在10秒内完成,而人工处理至少需要5分钟。”
更值得关注的是,智能路由还带来了“隐性优化”——由于模型能预测每个端点的性能,它会自动将“对延迟敏感”的请求(如实时支付)路由到低延迟端点,而将“对吞吐量敏感”的请求(如批量对账)路由到高吞吐量端点,刘强补充:“这种‘按需分配’让我们的整体资源利用率提升了15%,同时将支付成功率从99.92%提高到了99.97%。”
挑战与未来:贝叶斯优化的“黑箱”问题
尽管贝叶斯优化在云原生领域展现了巨大潜力,但其应用并非没有挑战,2026年6月,在旧金山举办的“Cloud Native Optimization Summit”上,多位专家指出了当前的核心问题:模型的“可解释性”。
“贝叶斯优化是一个‘黑箱’——它告诉我们‘应该这样做’,但不告诉我们‘为什么这样做’。”谷歌云首席AI科学家、论文合著者Sarah Chen(化名)坦言,“在资源调度或配置管理场景中,这可能不是大问题;但在金融、医疗等对可解释性要求极高的领域,黑箱模型可能面临合规风险,如果模型建议将某个关键服务的流量全部切换到一个新节点,工程师需要知道‘是因为新节点的延迟更低,还是因为旧节点存在未检测到的故障风险’——否则他们不敢轻易执行。”
2026年关注直播电商与碳利用及网络安全发展动态,技术创新推动产业升级 为解决这一问题,MIT团队正在开发“可解释贝叶斯优化”框架,通过引入“因果推理”技术