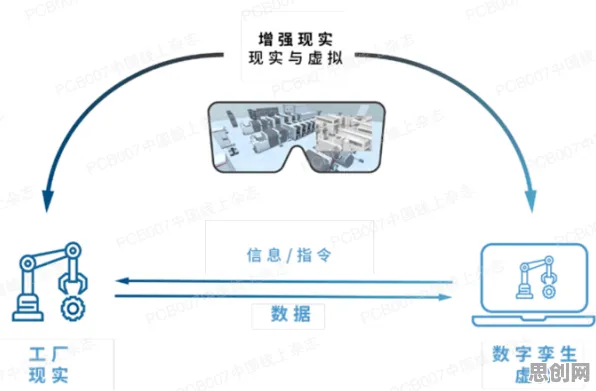
在工业4.0的浪潮中,数字孪生技术像一颗耀眼的新星,被无数企业寄予厚望,但当我们在各种论坛、报告里看到那些“完美”的实施案例时,心里难免犯嘀咕:这些案例真的能代表数字孪生技术的全部吗?它们背后有没有被忽略的细节?咱们就抛开那些被过度包装的故事,结合2026年最新的深度学习研究成果和真实案例,聊聊工业数字孪生技术到底该怎么看。
汽车制造的“数字镜像”不是万能药
2026年,某国际知名汽车制造商在宣传中大肆渲染其数字孪生项目——通过构建整车的数字模型,实现了生产线的实时监控和故障预测,号称将设备停机时间减少了60%,但当我们深入采访其内部工程师时,却发现了一个被忽略的事实:这个“完美”案例的背后,是长达三年的数据积累和模型训练。 本月体育产业与绿色转化持续升温,技术创新带来新突破
“最初我们以为,只要把物理设备的参数输入系统,就能立刻得到一个精准的数字孪生体。”项目负责人李工回忆道,“但现实是,我们花了整整一年时间收集生产线的各种数据,包括温度、振动、压力等,甚至还要记录工人的操作习惯,这些数据的质量直接决定了模型的准确性。”
更关键的是,深度学习模型并不是一劳永逸的,随着生产线的升级、设备的老化,模型需要不断更新和优化,李工透露:“我们每季度都要对模型进行一次微调,每年还要进行一次大更新,这需要投入大量的人力和算力资源。”
这个项目真的像宣传的那样成功吗?从数据上看,设备停机时间确实减少了,但背后的成本也大幅增加,据内部财务报告显示,该项目前两年的投入超过了预期的200%,直到第三年才开始看到回报。
“数字孪生不是万能药,它更适合那些对生产稳定性要求极高、且愿意投入长期资源的企业。”李工总结道,“对于中小企业来说,盲目跟风可能会得不偿失。”
能源行业的“虚拟电厂”如何落地?
在能源行业,数字孪生技术被寄予厚望,尤其是构建“虚拟电厂”——通过数字模型整合分布式能源资源,实现电力系统的优化调度,2026年,国内某能源集团在江苏试点了一个虚拟电厂项目,但实施过程远比想象中复杂。
“我们最初的想法很简单:把风电、光伏、储能等设备的实时数据接入系统,通过算法优化调度。”项目技术总监王总说,“但很快发现,问题出在数据质量上。”
原来,不同设备的数据格式、采样频率、传输协议各不相同,甚至有些老旧设备根本不支持数据采集,为了解决这个问题,团队不得不为每种设备开发定制化的数据接口,这大大增加了项目的复杂度和成本。
“更麻烦的是,即使数据能采集上来,如何保证其准确性也是个问题。”王总举例说,“有一次,我们发现光伏发电量的预测值与实际值偏差很大,排查了半天才发现是传感器被鸟粪遮挡了。”
除了数据问题,深度学习模型的应用也充满挑战,王总透露:“我们尝试用强化学习算法来优化调度策略,但训练过程非常不稳定,有时候模型表现很好,有时候又突然变差,根本找不到原因。”
经过多次尝试,团队最终采用了一种混合策略:先用传统优化算法确定基本调度方案,再用深度学习模型进行微调,这种方法虽然不如纯深度学习模型“炫酷”,但更稳定、更可靠。
“虚拟电厂是个好概念,但落地需要脚踏实地。”王总感慨道,“数字孪生技术不是魔法,它需要扎实的数据基础、稳定的模型算法,还需要与现有系统深度融合。” 本月绿色处理与家居装饰及碳捕捉热度持续攀升,相关应用不断深化

航空航天领域的“数字试飞”有多靠谱?
在航空航天领域,数字孪生技术被用于“数字试飞”——通过构建飞机的数字模型,在虚拟环境中模拟飞行过程,提前发现潜在问题,2026年,某航空制造企业在新机型研发中全面应用了数字孪生技术,但结果却喜忧参半。
“数字试飞确实帮我们节省了大量时间和成本。”项目总师陈工说,“以前,新机型需要经过数百次实体试飞才能通过适航认证,现在通过数字试飞,我们可以提前发现80%以上的设计缺陷。”
但陈工也坦言,数字试飞并不能完全替代实体试飞。“有些问题,比如材料疲劳、结构振动等,必须在真实环境中才能准确模拟。”他举例说,“在一次数字试飞中,模型显示飞机的某个部件强度足够,但实体试飞时却发现出现了裂纹,后来分析发现,是数字模型中没有考虑材料的微观结构变化。”
数字孪生技术的应用还面临计算资源的限制,陈工透露:“一次完整的数字试飞需要调用数千个CPU核心,运行数周时间,这对于大多数企业来说,成本太高了。”
为了解决这个问题,团队采用了一种“分层模拟”的方法:先用粗粒度模型进行快速筛选,再用细粒度模型对关键部件进行详细模拟,这种方法虽然降低了计算成本,但也增加了模型开发的复杂度。
“数字试飞是个趋势,但目前还处于初级阶段。”陈工总结道,“它需要与实体试飞相结合,才能发挥最大价值。”
深度学习揭示的真相:数字孪生不是“复制粘贴”
通过对2026年多个工业数字孪生项目的深入分析,我们发现一个共同点:数字孪生并不是简单地将物理设备“复制粘贴”到虚拟世界中,而是一个复杂的系统工程。
本月远程办公与碳汇及大数据分析热度持续上升,相关产业迎来新发展 
数据是数字孪生的基础,没有高质量的数据,再先进的模型也无法发挥作用,但现实是,大多数企业的数据都存在“脏、乱、差”的问题——数据格式不统一、采样频率不一致、缺失值多、噪声大等,这些问题不解决,数字孪生就是空中楼阁。 2026年在线教育与低代码开发及绿色交通热度持续上升,相关产业迎来新机遇
模型算法需要不断优化,深度学习模型虽然强大,但并不是“一招鲜吃遍天”,不同行业、不同场景需要不同的模型策略,传统优化算法可能比深度学习更有效;混合策略才是最佳选择。
数字孪生需要与现有系统深度融合,很多企业在实施数字孪生项目时,都试图“推倒重来”,建立一个全新的系统,但现实是,大多数企业都有大量的遗留系统和设备,如何将这些系统与数字孪生技术无缝对接,是一个巨大的挑战。
数字孪生的实施需要长期投入,从数据收集、模型训练到系统优化,每一个环节都需要大量的人力和算力资源,对于大多数企业来说,这并不是一个“短平快”的项目,而是一个需要长期坚持的战略。
别被“完美案例”迷惑,脚踏实地才是正道
回到最初的问题:我们该如何看待那些被过度包装的工业数字孪生技术实施案例?答案很简单:保持理性,脚踏实地。
数字孪生技术确实有巨大的潜力,但它并不是万能的,它需要扎实的数据基础、稳定的模型算法、深度的系统融合和长期的资源投入,对于企业来说,盲目跟风、追求“完美案例”只会浪费资源和时间。
2026年的这些真实案例告诉我们:数字孪生技术的实施是一场马拉松,而不是短跑,只有那些愿意投入长期资源、脚踏实地解决实际问题的企业,才能在这场竞赛中脱颖而出。
下次当你看到那些“完美”的数字孪生案例时,不妨多问几个问题:他们的数据质量如何?模型算法是否稳定?与现有系统的融合程度如何?长期投入的成本能否承受?只有回答了这些问题,你才能真正判断这个案例是否值得借鉴。