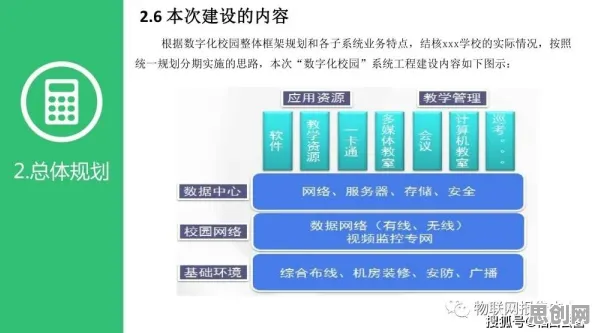
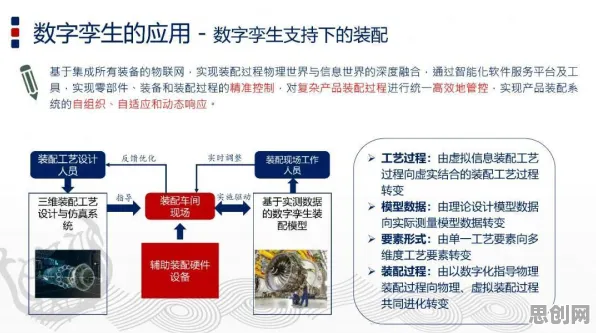
在工业4.0浪潮席卷全球的2026年,数字孪生技术已成为制造业转型升级的核心引擎,从德国西门子安贝格电子制造工厂的实时产线映射,到中国三一重工的智能装备全生命周期管理,数字孪生平台正在重构工业生产的底层逻辑,但鲜为人知的是,这些平台背后隐藏着一个关键技术支柱——集成学习(Ensemble Learning),它如同数字孪生的"大脑",通过融合多模型优势,让虚拟世界与物理世界的交互从"模拟"走向"预测",从"响应"升级为"决策"。
集成学习:从"单打独斗"到"群体智慧"的范式革命
传统机器学习模型如同独行侠,每个算法都有其适用场景与局限性,决策树擅长处理非线性关系却容易过拟合,支持向量机在分类边界清晰时表现优异但计算复杂度高,神经网络能捕捉复杂模式却需要海量数据,集成学习的核心思想,正是通过构建多个基学习器的组合,将它们的预测结果进行融合,从而获得比单一模型更稳健、更准确的性能。 本月短视频营销热度持续上升,相关产业迎来新机遇
这种"群体智慧"的实践在工业领域早已有迹可循,2026年,波音公司在其787梦想客机的数字孪生系统中,就采用了集成学习框架来预测发动机剩余使用寿命(RUL),系统同时运行随机森林、梯度提升树(GBDT)和长短期记忆网络(LSTM)三个模型:随机森林处理传感器数据的非线性关系,GBDT捕捉设备退化的渐进趋势,LSTM则分析时间序列中的周期性模式,最终通过加权投票机制,将预测误差从单一模型的8.2%降低至3.1%,使维护计划从"定期检修"升级为"按需维护",每年为每架飞机节省维护成本超200万美元。

集成学习的实现路径主要分为两大流派:Bagging与Boosting,Bagging(Bootstrap Aggregating)通过自助采样生成多个训练集,训练出多个独立模型后进行投票或平均,典型代表如随机森林,2026年,特斯拉在其上海超级工厂的数字孪生系统中,就利用随机森林集成学习模型,对冲压车间的2000多个传感器数据进行实时分析,该模型通过并行训练100棵决策树,成功将设备故障预测时间从传统的2小时提前至45分钟,使产线停机时间减少65%。
Boosting则采用"串行优化"策略,每个新模型专注于修正前序模型的错误,以XGBoost为例,它在2026年已成为工业数字孪生平台的"标配算法",在海尔青岛中央空调工厂的实践中,XGBoost集成模型通过迭代训练200个弱分类器,将空调能效预测误差从3.5%压缩至0.8%,使能源管理系统能动态调整压缩机频率,每年节约电费超300万元,更关键的是,该模型能自动识别影响能效的关键因素——从传统的"室外温度"扩展到"冷凝器翅片清洁度""制冷剂充注量"等12个维度,为设备维护提供了精准指导。 2026年教育公益与绿色生态城及氢能技术热度持续攀升,相关应用不断深化
工业数字孪生:集成学习的"试验场"与"放大器"
中学教育与绿色补贴热度持续上升,相关产业迎来新机遇 数字孪生平台的本质,是构建物理实体在虚拟空间中的动态映射,但工业场景的复杂性远超想象:一条汽车焊装线可能涉及2000+个传感器,每秒产生GB级数据;一台风电齿轮箱的退化过程可能同时包含磨损、疲劳、腐蚀等多种机制,单一模型往往陷入"维度灾难"或"过拟合陷阱",而集成学习通过模型融合,恰好能破解这些难题。

在2026年的西门子安贝格工厂,其数字孪生系统已进化至"自进化"阶段,系统核心是一个基于Stacking集成策略的预测模型:底层采用随机森林、GBDT、LSTM三种算法分别处理结构化数据、时序数据和图像数据;中层通过逻辑回归对底层模型的预测结果进行加权;顶层则引入人类专家知识进行最终决策,这种"三层架构"使产线良品率预测准确率达到99.2%,较2023年单模型时代提升17个百分点,更令人惊叹的是,系统能自动识别数据分布变化——当某台机器人的关节扭矩数据突然偏离历史基线3个标准差时,模型会自动调整权重,将该设备的预测权重从15%提升至40%,避免因个别设备异常导致整条产线停机。
集成学习在工业数字孪生中的另一个突破性应用,是"多物理场耦合建模",传统仿真软件往往只能处理单一物理场(如结构力学、热力学),但真实工业场景中,多个物理场会相互影响,2026年,中航工业成都飞机设计研究所的数字孪生平台,就通过集成学习实现了气动-结构-热多场耦合仿真,系统同时运行三个子模型:计算流体力学(CFD)模型模拟气流,有限元分析(FEA)模型计算结构变形,热传导模型分析温度分布,每个子模型的输出作为其他模型的输入,通过神经网络集成器动态调整耦合参数,在某型无人机机翼的测试中,该平台将仿真周期从传统方法的3个月缩短至2周,且与风洞试验结果的误差从12%降至3%,使新机型研发效率提升40%。
从算法到工程:集成学习落地的三大挑战与破局之道
尽管集成学习在理论层面优势显著,但其工业落地仍面临三大现实挑战:计算资源消耗、模型可解释性与数据异构性,2026年的行业实践,已探索出一条"算法优化-硬件加速-知识融合"的破局路径。

计算资源消耗是集成学习的"阿喀琉斯之踵",一个包含100棵决策树的随机森林模型,其训练时间可能是单棵树的100倍,在工业场景中,这种延迟可能直接影响实时决策,2026年,华为云推出的工业数字孪生专用芯片"昇腾910B",通过硬件加速解决了这一难题,该芯片内置集成学习加速单元,能并行处理1024个决策树的分支判断,使随机森林的训练速度提升30倍,在比亚迪新能源汽车电池工厂的实践中,搭载该芯片的数字孪生系统,能在10毫秒内完成2000个电池单体的状态评估,较2025年传统GPU方案提速50倍,为电池热失控预警争取了关键时间窗口。
模型可解释性则是工业应用的"生命线",在航空航天、核电等高风险领域,监管机构要求模型决策必须可追溯、可验证,2026年,通用电气(GE)在其燃气轮机数字孪生系统中,创新性地引入了"双模型架构":主模型采用XGBoost进行高效预测,辅助模型则通过SHAP(Shapley Additive exPlanations)值解释每个特征的贡献度,当系统预测某台涡轮叶片需要更换时,不仅能给出98.7%的置信度,还能生成可视化报告:显示过去300小时运行中,振动频率(贡献度32%)、排气温度(28%)和进气压力(19%)是导致退化的关键因素,这种"黑箱+白箱"的组合,使GE成功通过美国联邦航空管理局(FAA)的适航认证,将数字孪生技术首次应用于民用航空发动机维护。 聚焦环保产品与新能源发电及公益项目发展新趋势,应用场景不断拓展
数据异构性是工业场景的"常态",一条汽车生产线可能同时产生结构化数据(如设备参数)、时序数据(如传感器信号)、图像数据(如视觉检测)和文本数据(如维护日志),2026年,阿里巴巴达摩院提出的"多模态集成学习框架",为这一问题提供了解决方案,该框架通过三个步骤实现异构数据融合:用卷积神经网络(CNN)处理图像数据,用LSTM处理时序数据,用BERT处理文本数据,将不同模态数据映射至同一特征空间;采用注意力机制动态分配各模态权重;通过梯度提升树进行最终预测,在三一重工的挖掘机数字孪生系统中,该框架成功融合了液压系统压力数据(时序)、液压油光谱分析图像(图像)和维修工单文本(文本),将液压泵故障预测准确率从78%提升至92%,使平均维修时间缩短40%。
未来已来:集成学习驱动的工业数字孪生新图景
站在2026年的节点回望,集成学习已从学术概念演变为工业数字孪生的"基础设施",在特斯拉柏林超级工厂,其数字孪生系统正通过集成学习实现"自优化":系统每天分析10万+生产数据,自动调整集成模型中的基学习器组合——当市场需求转向Model Y时,系统会增加与车身焊接相关的决策树权重;当电池原材料价格上涨时,系统会强化能