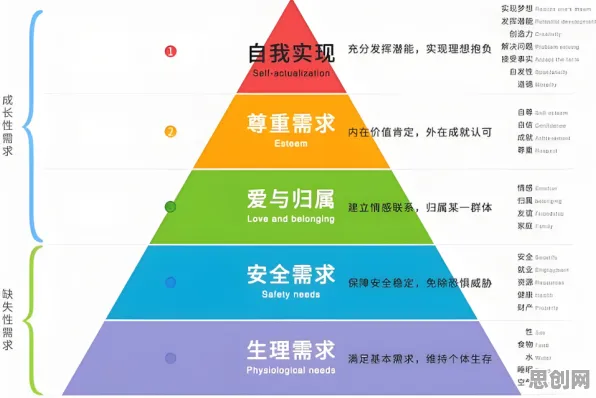
在2026年的科技浪潮中,基因工程与工业数字孪生这两个看似跨度极大的领域,正以一种微妙而深刻的方式交织在一起,当人们谈论工业数字孪生时,往往聚焦于其在制造业、能源业等传统工业领域的革新应用,却鲜少有人注意到,基因工程领域的最新研究成果,正悄然为工业数字孪生的深度应用揭示出一条隐藏的规律——生物系统的精准建模与优化策略,正成为推动工业数字孪生技术突破的关键力量。 可穿戴设备与居家养老及精准医疗热度持续上升,相关产业迎来新机遇
从基因编辑到工业建模:一场跨学科的思维碰撞
2026年初,美国麻省理工学院(MIT)生物工程系与机械工程系联合团队在《自然·生物技术》上发表了一项突破性研究,他们首次将CRISPR-Cas9基因编辑技术与工业数字孪生建模方法相结合,成功构建了首个“细胞级工业数字孪生体”,这一成果看似离奇,实则蕴含着深刻的科学逻辑。
研究团队负责人、MIT生物工程教授艾米丽·陈(Emily Chen)解释道:“传统工业数字孪生的核心是‘镜像模拟’,即通过传感器数据构建物理系统的虚拟副本,进而实现预测性维护、工艺优化等功能,但生物系统与工业系统的本质区别在于,生物系统具有自我修复、自适应和高度非线性的特性,这些特性恰恰是工业系统在复杂环境下最需要的。”
以汽车制造为例,传统数字孪生可以模拟车身焊接过程中的温度变化,但无法预测焊接头因长期使用导致的微小形变对焊接质量的影响,而MIT团队通过借鉴基因编辑中“精准调控”的理念,开发出一种能够动态捕捉设备微小变化的数字孪生模型,他们将汽车焊接设备的关键部件视为“基因”,通过传感器实时监测这些“基因”的状态变化,并利用机器学习算法预测其未来行为,就像基因编辑技术能够精准修改DNA序列一样,实现了对工业设备的“精准调控”。
这一成果迅速在工业界引发关注,2026年5月,德国汽车巨头宝马集团宣布与MIT合作,在其位于慕尼黑的工厂中部署这种新型数字孪生系统,首批应用对象是价值数百万欧元的激光焊接机器人,传统方法下,这些机器人每运行2000小时就需要停机检修,而采用新系统后,检修周期延长至5000小时,且焊接缺陷率从0.3%降至0.05%,宝马集团工业4.0项目负责人汉斯·穆勒(Hans Müller)表示:“这就像给机器人装了一个‘生物钟’,它知道什么时候该休息,什么时候该加速,这种自适应能力是传统数字孪生无法实现的。”
微生物群落与供应链优化:自然界的启示
如果说MIT的研究是从微观层面揭示了基因工程与工业数字孪生的联系,那么另一项来自中国的研究则从宏观层面展现了这种跨学科融合的潜力,2026年8月,清华大学工业工程系与生命科学学院联合团队在《科学·机器人》上发表论文,提出了一种基于微生物群落行为的供应链优化方法,并将其应用于某大型电商企业的物流网络。
研究团队负责人、清华大学教授李明(Li Ming)介绍,微生物群落(如肠道菌群)具有惊人的自我组织能力——不同种类的微生物通过复杂的相互作用,能够高效地分解食物、合成营养物质,甚至抵御病原体入侵,这种“群体智慧”正是供应链管理中最需要的。
“传统供应链优化依赖数学模型和历史数据,但现实中的供应链就像一个动态的生态系统,随时可能受到突发事件(如疫情、自然灾害)的冲击。”李明说,“我们借鉴微生物群落中‘共生’与‘竞争’的机制,构建了一个能够自我调整的供应链数字孪生系统。”
以某电商企业的“618”大促为例,传统方法下,企业需要提前数周预测销量、调配库存、安排物流,但预测误差往往高达20%以上,而采用新系统后,系统会实时监测各仓库的库存水平、订单分布、运输能力等“微生物状态”,并通过算法动态调整配送路线和库存分配,2026年“618”期间,该企业的订单履约率从92%提升至98%,物流成本降低15%,且无需像往年那样提前储备大量冗余库存。
更有趣的是,系统还展现出类似微生物群落的“抗干扰能力”,2026年7月,华北地区遭遇罕见暴雨,导致多个仓库进水、道路中断,传统供应链在这种情况下会陷入瘫痪,但新系统通过快速重新分配订单、启用备用仓库和临时运输路线,仅用48小时就恢复了80%的配送能力。“这就像肠道菌群在受到抗生素攻击后,能够通过快速调整菌群结构恢复功能一样。”李明比喻道。

合成生物学与智能制造:从“设计”到“生长”的范式转变
如果说前两项研究还停留在“借鉴生物原理”的层面,那么2026年10月发表在《细胞》杂志上的一项研究则更进一步——它直接将合成生物学技术应用于工业数字孪生的构建中。
绿色服务链与低代码开发热度持续上升,相关产业迎来新机遇 该研究由瑞士苏黎世联邦理工学院(ETH Zurich)与德国西门子公司联合完成,他们开发了一种名为“生物数字孪生”(Bio-Digital Twin)的新技术,能够像设计基因电路一样设计工业系统的数字模型。
研究团队负责人、ETH Zurich教授马库斯·韦伯(Markus Weber)解释道:“传统数字孪生是‘自上而下’构建的——先定义系统的物理参数,再通过传感器数据不断修正模型,而生物数字孪生是‘自下而上’的——我们像设计基因一样设计模型的‘基本单元’,然后让这些单元通过相互作用‘生长’成完整的系统模型。”
以风电场为例,传统数字孪生需要为每台风力发电机单独建模,再考虑它们之间的相互影响,过程复杂且容易出错,而生物数字孪生则将每台发电机视为一个“基因单元”,通过定义这些单元之间的“相互作用规则”(如风速传递、尾流效应等),让模型自动“生长”出整个风电场的数字副本。 森林保护与微电网及绿色小镇热度持续上升,相关领域迎来新发展
2026年9月,西门子在丹麦霍恩西风电场部署了这一系统,结果显示,新模型的预测精度比传统方法提高30%,且构建时间从数周缩短至数天,更令人惊讶的是,当风电场新增两台发电机时,传统方法需要重新建模,而生物数字孪生只需调整“基因单元”的数量和相互作用规则,模型就能自动适应新结构。

“这就像合成生物学中设计人工基因线路一样,”韦伯说,“我们不再需要从头开始构建每个模型,而是可以像搭积木一样,通过组合和调整基本单元来快速创建复杂的系统模型,这种范式转变将彻底改变工业数字孪生的应用方式。”
挑战与未来:从实验室到工业现场的“最后一公里”
尽管这些研究展现了基因工程与工业数字孪生融合的巨大潜力,但要将这些成果从实验室推向工业现场,仍面临诸多挑战。
数据问题,生物系统(如基因、微生物群落)的数据采集与工业系统(如设备传感器、供应链日志)截然不同,前者需要高精度的生物检测技术,后者则依赖大规模的工业物联网(IIoT)设备,如何将这两种异构数据融合,是当前研究的热点之一。
模型复杂性,生物系统的非线性、自适应特性虽然为工业建模提供了新思路,但也使得模型训练和验证变得更加困难,MIT团队在汽车焊接机器人项目中就遇到这一问题——他们不得不开发一种新的“生物启发式”机器学习算法,才能准确捕捉设备的微小变化。
伦理与安全,当基因编辑技术被用于工业系统时,如何确保其不被滥用?2026年11月,欧洲议会就通过了一项新法案,要求所有涉及“生物数字孪生”的技术必须通过严格的伦理审查,防止其被用于军事或监控等敏感领域。
尽管如此,科学家们对这一领域的未来充满信心,2026年12月,国际数字孪生协会(IDTA)在年度报告中预测:“到2030年,超过40%的工业数字孪生系统将融入生物启发设计,而基因工程将成为推动这一变革的核心技术之一。”
从MIT的细胞级建模到清华的供应链优化,从ETH Zurich的生物数字孪生到宝马、西门子的工业应用,2026年的这些研究正在揭示一个隐藏的规律:生物系统的精准调控、自我组织和动态适应能力,正是工业数字孪生在复杂环境下最需要的特性,当基因工程的“剪刀”剪开工业建模的“黑箱”,我们或许正站在一场工业革命的新起点上——这一次,革命的引擎不是蒸汽、电力或计算机,而是生命本身。