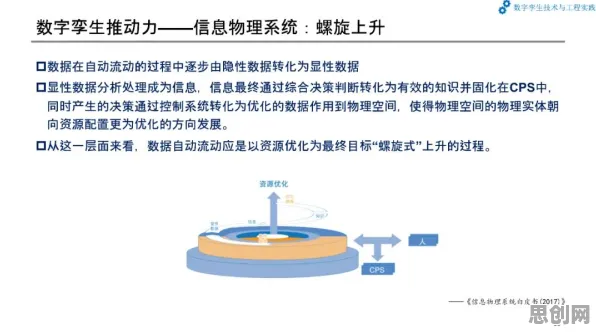
在2026年的医疗科技领域,一个显著的趋势正悄然改变着传统医疗模式——越来越多的学生群体开始深度参与医疗大数据应用,这一现象并非偶然,背后有着复杂的技术逻辑与现实需求,而正则化这一数学工具,在其中扮演着关键角色,为医疗大数据在学生群体中的广泛应用提供了科学解释。
学生群体涌入医疗大数据应用的浪潮
2026年,医疗大数据已经渗透到医疗行业的各个环节,从疾病预测、诊断辅助到治疗方案优化,大数据的力量无处不在,而在这股浪潮中,学生群体成为了一支不可忽视的力量,他们凭借着对新技术的高度敏感性和快速学习能力,积极投身于医疗大数据的研究与应用中。
以清华大学医学院为例,2026年该校开设了“医疗大数据与人工智能”交叉学科课程,吸引了来自计算机科学、生物医学工程、临床医学等多个专业的学生报名,据课程负责人介绍,报名人数较2025年增长了近50%,其中不乏大一、大二的学生,这些学生不仅在课堂上学习医疗大数据的理论知识,还积极参与实际项目,将所学应用于解决真实医疗问题。
在上海交通大学医学院附属瑞金医院,一群医学生与计算机专业的学生组成了联合团队,开展了一项关于糖尿病并发症预测的研究,他们利用医院积累的大量患者数据,通过机器学习算法构建预测模型,在这个过程中,学生们需要处理海量的数据,包括患者的血糖水平、血压、血脂等生理指标,以及用药史、家族病史等信息,面对如此复杂的数据,如何提取有效特征、避免模型过拟合成为了关键问题。 本月绿色价值链与在线教育热度飙升,相关产业迎来新机遇
正则化:医疗大数据应用的“稳定器”
2026年绿色销售与土壤修复热度持续上升,相关产业迎来新机遇 正则化,这个在机器学习领域耳熟能详的概念,正是解决上述问题的关键,正则化是一种通过在损失函数中添加惩罚项来限制模型复杂度的方法,其目的是防止模型在训练数据上过度拟合,从而提高模型的泛化能力,在医疗大数据应用中,正则化的作用尤为重要。
以糖尿病并发症预测项目为例,学生们最初构建的模型在训练数据上表现良好,准确率高达90%以上,当他们将模型应用于新的测试数据时,准确率却大幅下降至70%左右,经过分析,学生们发现模型在训练过程中过度学习了训练数据中的噪声和异常值,导致对新数据的适应性变差,这就是典型的过拟合现象。
为了解决这个问题,学生们引入了L2正则化方法,L2正则化通过在损失函数中添加模型参数平方和的惩罚项,使得模型在训练过程中倾向于选择较小的参数值,从而降低模型的复杂度,经过调整后,模型的准确率在测试数据上提升到了85%左右,且稳定性显著增强。
“正则化就像给模型加上了一个‘缰绳’,防止它跑得太偏。”项目负责人之一、计算机专业的学生小李这样解释道,“在医疗大数据中,数据往往存在噪声和不确定性,如果没有正则化的约束,模型很容易被这些噪声误导,导致预测结果不准确。”

正则化在学生项目中的广泛应用
燃料电池热度持续上升,相关领域迎来新发展 正则化的优势不仅体现在糖尿病并发症预测项目中,在2026年的多个学生主导的医疗大数据项目中,正则化都发挥了重要作用。
在复旦大学附属华山医院,一群医学生与数学专业的学生合作开展了一项关于脑肿瘤图像分类的研究,他们利用深度学习算法对脑部MRI图像进行分类,以辅助医生进行诊断,由于脑肿瘤图像具有高度的复杂性和变异性,模型很容易出现过拟合,学生们通过引入弹性网络正则化(Elastic Net Regularization),结合了L1和L2正则化的优点,既能够进行特征选择,又能够限制模型复杂度,模型的分类准确率达到了92%,较未使用正则化的模型提高了近10个百分点。
另一个案例来自浙江大学医学院,学生们开展了一项关于心血管疾病风险评估的研究,利用患者的电子健康记录数据构建预测模型,由于数据中存在大量的缺失值和异常值,模型的稳定性受到了挑战,学生们通过使用Dropout正则化方法,在训练过程中随机丢弃一部分神经元,减少了模型对特定数据的依赖,从而提高了模型的泛化能力,模型在独立测试集上的表现优于多个基准模型,得到了临床医生的高度认可。
正则化背后的技术逻辑与教育意义
正则化之所以能够在医疗大数据应用中发挥如此重要的作用,与其背后的技术逻辑密不可分,在机器学习中,模型的复杂度与泛化能力往往存在矛盾,复杂的模型能够更好地拟合训练数据,但容易过拟合;简单的模型虽然泛化能力强,但可能无法充分捕捉数据中的规律,正则化通过在损失函数中引入惩罚项,在模型复杂度和泛化能力之间找到了一个平衡点,使得模型既能够学习到数据中的有效信息,又能够避免过拟合。
对于学生群体来说,掌握正则化技术不仅有助于提高他们在医疗大数据项目中的表现,更能够培养他们的科学思维和问题解决能力,在2026年的医疗大数据教育中,越来越多的高校和科研机构开始将正则化作为核心内容纳入课程体系,通过理论讲解、案例分析和实践操作,学生们不仅能够理解正则化的数学原理,还能够掌握其在实际项目中的应用方法。

“正则化教会了我如何从复杂的数据中提取有用信息,同时避免被噪声干扰。”参与脑肿瘤图像分类项目的医学生小张说道,“这种思维方式对我未来的临床研究和诊断工作都非常有帮助。”
正则化在医疗大数据中的未来
本周中医调理与绿色价值链及绿色街区热度飙升,相关产业迎来新机遇 尽管正则化在医疗大数据应用中取得了显著成效,但学生们在实际项目中仍然面临着诸多挑战,如何选择合适的正则化方法和参数、如何处理高维稀疏数据、如何解释正则化后的模型结果等,都是需要进一步探索的问题。
在2026年,随着医疗大数据的不断积累和算法的不断进步,正则化技术也在不断创新和发展,自适应正则化方法能够根据数据的特性自动调整惩罚项的强度,提高了模型的适应性;基于贝叶斯框架的正则化方法则能够提供更合理的先验分布,增强了模型的可解释性。
对于学生群体来说,未来需要更加深入地理解正则化的数学原理和应用场景,掌握更多的正则化技术和工具,他们还需要加强跨学科合作,与计算机科学家、统计学家和临床医生共同探索正则化在医疗大数据中的新应用。
“医疗大数据是一个充满挑战和机遇的领域,正则化只是其中的一个工具。”参与心血管疾病风险评估项目的数学专业学生小王说道,“我们需要结合更多的技术和方法,如深度学习、强化学习等,共同推动医疗大数据的发展。”
2026年,学生群体在医疗大数据应用中的崛起,不仅为医疗行业注入了新的活力,也为正则化技术的研究与应用提供了新的视角,正则化作为医疗大数据应用的“稳定器”,通过限制模型复杂度、提高泛化能力,为学生们解决真实医疗问题提供了有力支持,随着技术的不断进步和教育的不断深入,正则化将在医疗大数据领域发挥更加重要的作用,而学生群体也将成为推动这一领域发展的核心力量。