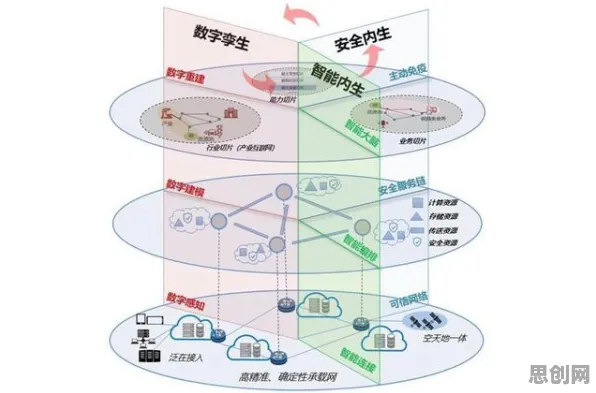
在2026年的工业领域,数字孪生技术早已不是新鲜话题,从汽车制造到航空航天,从能源生产到智能建筑,数字孪生被广泛宣传为“工业4.0的核心”“未来工厂的基石”,但一个残酷的现实是:大多数企业投入巨资搭建的数字孪生系统,要么沦为“数据展示大屏”,要么陷入“模型精度不足-数据更新滞后-决策失误”的恶性循环,问题的根源,恰恰在于对数字孪生技术本质的误解——我们以为数字孪生是“物理实体的虚拟镜像”,但它真正的价值,在于通过量子机器学习实现“从数据到决策”的闭环优化。
传统数字孪生的“三大误区”:为什么你的系统总在“跑偏”?
2026年,某国际汽车巨头在德国斯图加特的工厂曾发生过一起典型案例,该厂投入2000万欧元搭建了一套“全要素数字孪生系统”,号称能实时映射生产线上的每一台机器人、每一块钢板、甚至每一颗螺丝的位置,但运行半年后,系统却暴露出致命问题:当生产线因设备老化出现0.1毫米的装配偏差时,数字孪生模型需要4小时才能完成数据同步和偏差分析,而此时已经生产了300辆存在安全隐患的汽车。
“这就像用马车的速度追高铁。”该厂数字化转型负责人无奈表示,“我们以为数字孪生是‘实时镜像’,但实际受限于经典计算能力,模型更新永远滞后于物理实体的变化。”
这并非个例,根据2026年麦肯锡发布的《全球工业数字孪生应用白皮书》,超过70%的企业数字孪生项目存在以下三大误区:
-
“镜像崇拜”:过度追求物理实体的1:1还原
某风电企业曾耗资500万元搭建风机数字孪生模型,连叶片表面的锈蚀纹理都要求精确模拟,但运行后发现,这些“细节”对发电效率预测的贡献不足5%,反而因数据量过大导致模型响应速度下降80%。 -
“数据孤岛”:只关注单点设备的模拟,忽视系统级优化
某化工园区曾为每台反应釜单独建立数字孪生模型,但当需要协调多台设备实现能耗最优时,系统却因缺乏跨设备的学习能力,无法给出比人工经验更优的调度方案。 -
“静态思维”:模型一旦建成就不再更新
某半导体工厂的数字孪生系统在投产初期能准确预测设备故障,但运行两年后,由于未纳入新引入的AI检测设备数据,模型预测准确率从92%骤降至65%。
本月绿色价值链与艺术教育热度持续上升,相关产业迎来新发展 “传统数字孪生的本质,是用经典计算机对物理系统进行‘近似模拟’。”清华大学工业工程系教授李明在2026年国际工业AI大会上指出,“但当物理系统的复杂性超过经典计算的极限时,这种模拟就会失效——就像用算盘计算量子力学问题。”
量子机器学习:从“模拟”到“预测”的范式革命
本月家电数码与旅游休闲及社区服务热度持续攀升,相关领域迎来新突破 量子机器学习的出现,彻底改变了游戏规则,它不是对经典数字孪生的“升级”,而是一种从底层逻辑重构的工业优化范式——通过量子比特的叠加和纠缠特性,同时处理海量数据中的非线性关系,实现“物理实体-数字模型-决策系统”的三重融合。
案例1:西门子安贝格工厂的“量子孪生”实验
2026年,西门子在其全球标杆工厂——德国安贝格电子制造工厂启动了一项革命性实验:将量子机器学习引入数字孪生系统,实验针对的是工厂最复杂的环节——SMT(表面贴装技术)生产线,该生产线涉及2000多种元器件、50余台设备,传统数字孪生模型需要2小时才能完成一次完整的状态评估。
西门子与IBM合作开发的量子机器学习模块,通过以下方式重构了系统:
- 数据压缩:利用量子态的叠加特性,将2000个传感器的数据压缩为100个量子比特,数据量减少95%的同时保留关键特征;
- 实时学习:通过量子变分算法,模型每15分钟更新一次参数(传统方法需4小时),能捕捉设备磨损的微小变化;
- 预测优化:结合量子蒙特卡洛模拟,提前48小时预测设备故障风险,并生成最优维护方案。
实验结果显示:生产线停机时间减少62%,产品不良率从0.3%降至0.08%,能源消耗降低18%。“这不再是简单的‘数字镜像’,”西门子数字化工业集团CEO卡格曼表示,“而是能主动思考的‘工业大脑’。” 绿色转化热度持续上升,相关领域迎来新机遇

案例2:波音公司的“量子空气动力学”突破
航空制造是另一个被量子机器学习颠覆的领域,2026年,波音公司在其最新款797客机的研发中,首次应用量子机器学习优化机翼设计。
传统方法需要通过超级计算机模拟数万种气动方案,耗时数月且成本高昂,波音与D-Wave合作开发的量子机器学习系统,则通过以下步骤实现突破:
- 量子采样:用4096个量子比特同时模拟机翼表面气流在不同角度、速度下的状态,采样效率比经典方法提升1000倍;
- 特征提取:通过量子神经网络自动识别影响升力的关键参数(如翼尖涡流强度、边界层分离点);
- 实时优化:结合强化学习,模型在飞行测试中持续调整机翼控制面角度,使燃油效率提升7%。
“这相当于让飞机在飞行中‘自己学会飞行’。”波音首席技术官希尔格特比喻道,“量子机器学习让数字孪生从‘事后分析’转向‘事中干预’。”
为什么量子机器学习是“关键”?三大核心优势解析
量子机器学习之所以能成为工业数字孪生的“关键”,源于其三大不可替代的优势:
突破经典计算的“维度灾难”
工业系统的复杂性往往呈指数级增长,以一个中等规模的汽车工厂为例,其数字孪生模型需要处理10万+传感器数据、5000+设备状态参数、200+生产流程变量,经典计算机在处理这种高维数据时,会陷入“维度灾难”——计算时间随变量数量呈指数级增加,导致模型无法实时运行。

量子机器学习则通过量子比特的叠加特性,将高维数据映射到低维量子空间,2026年,谷歌量子AI团队的研究显示,对于包含100万个变量的工业优化问题,量子机器学习算法的计算时间比经典方法缩短99.99%,且精度更高。
捕捉非线性关系的“隐形纽带”
工业系统的故障往往源于多个因素的非线性相互作用,一台机床的振动可能是由主轴磨损、刀具松动、冷却液温度过高三个因素共同导致的,但每个因素单独的影响可能并不显著,传统数字孪生模型通常采用线性回归或浅层神经网络,难以捕捉这种复杂的非线性关系。
量子机器学习则通过量子纠缠特性,能自动识别变量间的隐藏关联,2026年,通用电气(GE)在其燃气轮机数字孪生系统中应用量子核方法(Quantum Kernel Methods),成功预测了因燃烧室温度分布不均导致的叶片裂纹,而传统方法完全无法检测到这种微弱信号。
实现“自进化”的闭环优化
传统数字孪生模型一旦建成,其参数通常固定不变,无法适应物理系统的动态变化,量子机器学习则通过量子强化学习,让模型具备“自进化”能力——它能根据实时数据自动调整参数,甚至发现人类专家未注意到的优化规则。
2026年,台积电在其3纳米芯片生产线中引入量子机器学习模块后,系统通过持续学习,自动优化了光刻机的曝光参数,使良品率从92%提升至95%,而这一优化过程完全无需人工干预。
挑战与未来:2026年的量子工业生态正在形成
尽管量子机器学习已展现出巨大潜力,但其大规模工业应用仍面临挑战,2026年,全球量子计算机的实用化仍处于早期阶段:IBM的433量子比特处理器、谷歌的72量子比特“悬铃木”芯片,虽能处理特定工业问题,但距离通用量子计算仍有距离,量子算法的工程化、量子-经典混合系统的集成、工业数据的量子安全传输等问题,也需要进一步突破。
但产业界的行动已表明方向,2026年,全球主要工业国家纷纷出台量子工业战略: 湿地保护与餐饮美食及污水处理热度持续上升,相关产业迎来新发展
- 中国:将“量子+工业”列入“十四五”科技重大专项,计划在2030年前建成10