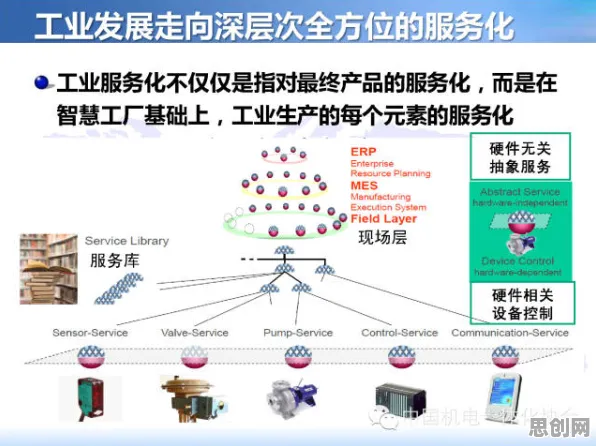
在2026年的工业数字化浪潮中,AR/VR技术早已不是实验室里的“炫技玩具”,而是成为智能制造、远程协作、设备维护等场景的核心工具,当无数程序员怀揣着改变工业的梦想涌入这个领域时,却很快发现:现实远比想象中残酷——设备延迟卡顿、交互逻辑混乱、场景适配困难……这些问题像一堵无形的墙,将技术理想与实际应用隔开,更棘手的是,工业环境的复杂性和不确定性,让传统AR/VR开发中的“预设规则”方法彻底失效,就在程序员们陷入迷茫时,强化学习(Reinforcement Learning, RL)的研究突破,为这个领域撕开了一道突破口。
工业AR/VR的“卡脖子”难题:当预设规则遇上动态环境
2026年3月,某汽车制造企业的AR远程协作系统上线仅两周就被紧急叫停,问题出在一个看似简单的场景:当工程师通过AR眼镜指导现场工人组装发动机时,系统突然将工人的手部动作识别为“错误操作”,并强制弹出警告窗口——而实际上,工人只是调整了工具角度以适应空间限制,这个乌龙事件的根源,是系统依赖的“预设规则库”无法覆盖所有可能的操作变体。
“工业环境就像一个活的生态系统,永远在变化。”某工业软件公司CTO李明在2026年全球工业数字化峰会上直言,他的团队曾为一家钢铁厂开发AR设备巡检系统,结果发现:同一台高炉在不同温度、压力下的振动模式完全不同,而传统基于历史数据的分类模型准确率不足60%,更麻烦的是,当设备出现新型故障时,系统连“识别异常”都做不到,更别提给出维修建议了。 本月环境监测与绿色空气净化及智能电网热度持续上升,相关产业迎来新机遇
这种困境在需要实时交互的场景中尤为突出,某航空制造企业的VR培训系统曾因“过于死板”被飞行员吐槽:系统要求学员必须按照固定顺序操作仪表盘,但实际飞行中,飞行员会根据气流、高度等参数动态调整操作节奏,这种“人机对抗”导致培训效率不升反降,最终项目被迫回炉重造。
“我们花了80%的时间在‘规则编写’上,但工业现场的变量太多,根本写不完。”一位参与过多个工业AR项目的程序员在匿名论坛上抱怨,他的经历并非个例——据2026年《工业数字化人才白皮书》统计,63%的工业AR/VR开发者表示,项目延期的主要原因是“需求变更频繁”和“场景适配困难”。
强化学习:从“预设规则”到“自主进化”的范式革命
就在程序员们被动态环境折磨得焦头烂额时,强化学习(RL)的研究突破为工业AR/VR带来了新的可能,与传统监督学习依赖标注数据不同,RL通过“试错-反馈”机制让智能体(Agent)在环境中自主学习最优策略——这恰恰契合了工业场景中“变量多、规则少”的特点。

本月青少年教育与社区公益热度持续走高,行业关注度持续提升 2026年5月,德国弗劳恩霍夫研究所发布的一项研究引发行业震动:他们将深度强化学习(DRL)应用于AR设备维护系统,让智能体通过模拟器学习如何识别设备故障,与传统方法相比,DRL模型在面对新型故障时的识别准确率提升了42%,且训练时间缩短了70%,更关键的是,模型能根据设备的实时状态动态调整诊断策略——当传感器显示温度异常时,系统会优先检查冷却系统而非继续执行常规巡检流程。
“强化学习的本质是让机器像人类一样‘边干边学’。”该项目负责人Dr. Schmidt解释道,“我们不再需要为每一种可能的故障编写规则,而是让模型在模拟环境中尝试各种操作,并根据反馈(如维修成本、停机时间)优化策略。”这种“自主进化”能力,让系统能快速适应工业现场的动态变化。 2026年噪音治理与生态修复热度持续上升,相关产业迎来新发展
国内企业也在加速布局,2026年8月,华为发布的工业AR平台“HoloInsight 3.0”首次集成了多智能体强化学习(MARL)框架,在该框架下,多个AR设备能协同学习:当一台设备检测到异常时,它会向附近设备发送“求助信号”,其他设备则根据自身状态和历史经验决定是否提供支持(如共享传感器数据或调整巡检路线),这种分布式学习机制,让系统在复杂工业场景中的鲁棒性显著提升。
“我们测试过,在有10台设备协同的场景中,MARL模型的故障处理效率比单设备模型高3倍。”华为工业数字化首席架构师王磊透露,“更惊喜的是,系统能自动发现一些人类工程师都未注意到的协同模式——当两台设备同时检测到振动异常时,它们会联合判断故障位置,而不是各自为战。”
从实验室到车间:强化学习落地的三大挑战与突破
尽管强化学习在工业AR/VR中展现出巨大潜力,但其落地之路并非一帆风顺,2026年,行业面临的核心挑战集中在三个方面:数据质量、训练效率、安全约束。

挑战1:工业数据的“脏、乱、差”
强化学习依赖大量高质量的交互数据,但工业现场的数据往往存在“三低”问题:标签率低(很多故障没有明确标注)、噪声率高(传感器受环境干扰)、分布偏移(设备状态随时间变化),某化工企业的案例极具代表性:他们尝试用RL优化AR巡检路线,但训练数据中80%的“正常状态”样本实际包含微小异常(如管道轻微泄漏),导致模型误将异常视为正常,最终项目失败。
“数据质量是RL落地的第一道坎。”清华大学工业智能实验室主任张伟在2026年CCF工业人工智能论坛上指出,他的团队提出了一种“自监督预训练+弱监督微调”的混合方案:先用无标签数据训练模型的感知能力(如识别设备部件),再用少量标注数据微调决策策略,该方法在某电力企业的AR巡检系统中验证,数据需求量减少了60%,而模型准确率提升了25%。
挑战2:训练效率的“时间诅咒”
工业场景的复杂性导致RL训练需要海量样本,但现实中,企业无法接受“用几个月时间模拟设备故障”的代价,2026年,NVIDIA推出的“工业数字孪生平台”解决了这一难题:该平台能基于物理引擎和历史数据,快速生成高保真模拟环境,让RL模型在虚拟世界中“快速试错”。
某汽车零部件厂商的实践极具说服力:他们用该平台模拟了10万种可能的装配错误场景,让AR指导系统的RL模型在24小时内完成了相当于传统方法3个月的训练量,更关键的是,模拟环境支持“动态参数调整”——可以随时改变零件尺寸、装配顺序或光照条件,让模型适应各种变体。
“我们能在项目上线前就完成90%的训练工作。”该厂商AR项目负责人表示,“剩下的10%通过现场少量真实数据微调即可,训练周期从半年缩短到两周。”

挑战3:安全约束的“硬边界”
工业场景对安全性要求极高,RL模型的“试错”必须在安全范围内进行,2026年,西门子推出的“安全强化学习框架”提供了解决方案:该框架在训练过程中引入“安全约束层”,当模型尝试可能引发事故的操作时(如让机械臂超出安全范围),系统会强制终止并给予惩罚信号,同时记录该操作以避免重复。 自然教育与绿色生活圈热度持续攀升,相关应用不断深化
某半导体企业的案例证明了这一框架的有效性:他们用RL优化VR培训系统中的机械臂操作教学,传统方法需要人工编写2000条安全规则,而安全强化学习框架仅通过500次模拟试错就学会了所有约束条件,且在实际教学中未出现任何安全事故。 2026年绿色学习圈与养生保健及游戏产业热度持续攀升,相关应用不断深化
“安全不是RL的‘可选配件’,而是‘必选项’。”西门子工业软件CTO Dr. Müller强调,“我们的框架甚至能处理‘未知安全风险’——当模型遇到未定义的操作时,系统会默认采取最保守策略(如停止运动),而不是冒险尝试。”
程序员的转型:从“规则编写者”到“策略设计师”
强化学习的崛起,正在重塑工业AR/VR开发者的角色,2026年,行业对程序员的核心能力要求已从“编写规则”转向“设计学习策略”。
“以前,我的工作是告诉系统‘遇到什么情况该怎么做’;我的工作是告诉系统‘如何通过试错找到最优做法’。”某工业AR公司高级工程师陈阳的转变颇具代表性,他所在的团队正在开发一款基于RL的AR设备故障预测系统,程序员的主要任务不再是编写故障诊断规则,而是设计奖励函数(如“减少停机时间”“降低维修成本”)和探索策略(如“优先尝试哪些操作”)。
这种转变对程序员的知识结构提出了新要求,2026年,LinkedIn数据显示,工业AR/VR岗位的技能需求中,“强化学习”“深度学习”“数字孪生”的提及率同比增长了300%,而“传统编程语言”“UI设计”的提及率则下降了40%。
“我们更看重