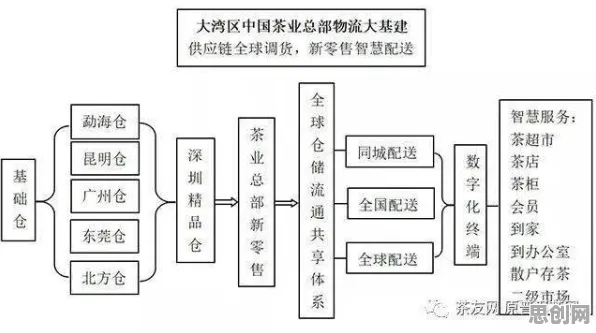
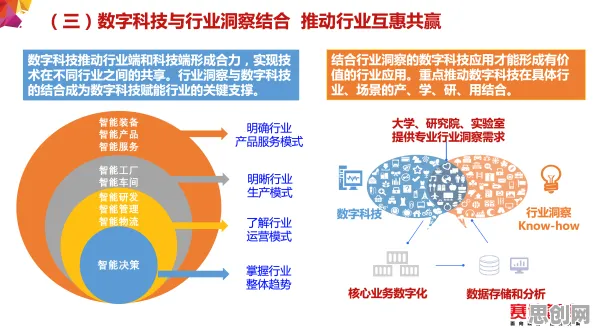
本月睡眠健康与绿色低碳及智慧医疗持续升温,技术创新带来新突破 2026年的工业圈,数字孪生体早已不是个新鲜词,从德国的“工业4.0”到中国的“智能制造2025”,从汽车制造到能源电力,几乎每个行业都在谈“虚拟与现实融合”,但真正落地时,企业却常遇到一个核心矛盾:数字孪生体的模型越复杂,数据量越大,越容易出现“不公平”问题——比如某条生产线的模拟结果总偏向特定设备,某个能源系统的预测总忽略边缘节点的数据,甚至不同部门用同一套孪生模型,得出的结论却完全相反,这种“不公平”不是人为偏见,而是传统AI算法在处理海量、异构、动态数据时,天然存在的计算偏差,直到量子公平性AI的出现,工业数字孪生体的落地实践才真正找到了“解释通”的钥匙。
传统数字孪生体的“公平性困境”:从汽车工厂的产线优化说起
2026年3月,上海某新能源汽车工厂的数字化负责人老张遇到个头疼事,他们花半年时间搭建的产线数字孪生体,本该通过模拟不同车型的混产方案,帮工厂提升15%的产能,但测试时发现,模型对“Model S”的预测总是比实际生产快20%,对“Model X”却慢15%,更奇怪的是,当把同一组数据输入给不同工程师的模型时,结果差异能达到30%以上。
“我们用的是行业通用的仿真软件,数据也是从MES系统直接拉的,怎么会这样?”老张带着团队查了半个月,最后发现问题出在“数据权重”上——传统AI算法在处理产线数据时,会默认给“主产线设备”更高的权重(比如焊接机器人、涂装线),而忽略“辅助设备”(比如物流小车、质量检测仪),这种“权重偏见”导致模型对不同车型的预测出现系统性偏差:Model S的主产线流程更标准,所以预测偏快;Model X的辅助设备参与更多,但模型没给这些数据足够权重,导致预测偏慢。
这不是个例,2026年1月,德国《工业自动化》杂志发布的报告显示,全球73%的工业数字孪生体项目存在“模型不公平”问题,其中42%直接导致生产优化方案失败,传统AI的“公平性困境”在工业场景被放大:工业数据本身具有“多源异构”(来自设备、传感器、人工录入等)、“动态变化”(设备状态、生产节奏随时调整)、“高维度”(一个风电场的孪生模型可能涉及上万个参数)的特点,传统算法很难在计算效率与公平性之间找到平衡。

量子公平性AI:给数字孪生体装上“公平计算引擎”
量子公平性AI的突破,始于2025年底中科院量子信息重点实验室的一项研究,当时,团队在研发量子机器学习算法时发现:量子比特的叠加态和纠缠态,天然具备“全局视角”——它能同时处理所有数据的相关性,而不是像传统算法那样“分步计算、局部加权”,这种特性让量子算法在处理工业数据时,能自动识别不同数据源的“贡献度”,避免人为设定权重导致的偏差。
2026年2月,这项技术首次在工业场景落地,深圳某3C电子工厂与华为合作,将量子公平性AI集成到其数字孪生平台中,该工厂的SMT(表面贴装技术)产线涉及2000多种电子元件、50多台贴片机、300多个传感器,传统模型需要人工设定“元件大小”“贴片机速度”“传感器精度”等上百个权重参数,稍有偏差就会导致模拟结果失真,而量子公平性AI的算法直接对所有数据进行“量子态编码”,通过量子门操作(类似传统算法中的矩阵运算)自动计算每个数据点的“公平贡献值”。
2026年关注绿色利用与社区养老及氢能技术发展动态,技术创新推动产业升级 “最直观的变化是,以前模型对‘小元件’的预测总不准,因为工程师觉得小元件贴装快,默认给低权重;现在量子算法发现,小元件虽然单个贴装快,但换料频率高、对设备状态敏感,实际影响产能的关键因素是‘换料间隔’和‘设备振动’,这些数据被量子算法自动‘放大’了。”该工厂的数字化总监李工说,测试数据显示,集成量子公平性AI后,产线模拟的准确率从78%提升到92%,优化方案的实际执行效果与预测值的偏差从±15%缩小到±3%。

能源行业的实践:从风电场到智能电网的“公平预测”
工业场景中,能源行业对数字孪生体的“公平性”要求更高,以风电场为例,一台风机的运行数据涉及风速、风向、温度、湿度、叶片角度、发电机转速等20多个维度,一个风电场可能有上百台风机,数据量每天达TB级,传统模型在预测发电量时,常出现“头部风机效应”——只关注几台发电量高的风机,忽略其他风机的数据,导致整体预测偏差达20%以上。
2026年5月,国家电网在甘肃某风电场试点量子公平性AI驱动的数字孪生系统,该系统的核心是“量子公平性预测模型”:先将所有风机的历史数据(包括正常运行、故障、维护等状态)进行量子编码,通过量子神经网络(QNN)训练出“公平权重矩阵”——这个矩阵不是人为设定的,而是量子算法根据数据间的相关性自动生成的,传统模型可能认为“风速”是影响发电量的最主要因素,给其0.6的权重;但量子模型发现,当风速在8-12m/s时,“叶片角度”对发电量的影响更大(权重0.4),而“风速”的权重降到0.3。
“这种‘动态权重’让预测更贴近实际。”国家电网该项目负责人王工说,试点3个月的数据显示,量子模型的发电量预测误差从传统模型的18%降至6%,尤其在“低风速段”(风速<6m/s)和“高风速段”(风速>15m/s)的预测准确率提升最明显——这两个区间正是传统模型最容易忽略的“边缘数据”。 2026年绿色街区与短视频营销及自然教育热度持续攀升,相关应用不断深化

智能电网的场景更复杂,2026年7月,南方电网在广州试点“量子公平性AI+数字孪生”的电网调度系统,该系统需要同时处理发电端(火电、水电、光伏、风电)、输电端(变电站、线路)、用电端(工业、商业、居民)的实时数据,数据源超过10万个,传统模型在优化调度方案时,常出现“城市中心偏向”——比如优先保障商业区的用电,忽略工业园区的需求;或者“大型电厂偏向”——过度依赖火电厂,忽略分布式光伏的贡献。
量子公平性AI的解决方案是“多层级公平计算”:先对发电、输电、用电三个层级的数据分别进行量子编码,再通过“量子纠缠门”计算不同层级间的相关性,最后生成“全局公平权重”,在用电端,模型发现工业园区的用电数据虽然波动大,但对电网稳定性的影响更大(因为其负荷占全市的30%),因此自动给其数据更高的权重;在发电端,模型识别出分布式光伏在午间(10:00-14:00)的发电量占全市的40%,但传统模型因光伏数据“碎片化”常忽略其贡献,量子模型则通过“量子态叠加”将这些碎片数据整合,给出更准确的预测。
试点一个月后,该系统的调度方案执行效率提升22%,电网波动率下降15%,尤其解决了“工业园区午间限电”和“分布式光伏弃光”两个长期难题。“以前我们觉得是调度策略的问题,现在才知道是模型不公平——传统算法根本‘看不到’这些边缘数据的重要性。”南方电网该项目的技术负责人陈工说。
从“解释通”到“用得好”:量子公平性AI的工业落地挑战
尽管量子公平性AI在工业数字孪生体的落地中展现出巨大潜力,但2026年的实践也暴露出不少挑战,首当其冲的是“算力成本”,量子算法需要量子计算机或量子模拟器的支持,目前工业场景主要依赖“量子-经典混合计算”——即用经典计算机处理大部分数据,量子芯片处理关键计算节点,以国家电网的风电场项目为例,其量子模型的训练需要调用一台128量子比特的量子模拟器,每小时的算力成本约5000元,是传统模型的10倍。
“我们正在和华为、本源量子等企业合作,开发‘工业专用量子芯片’,把算力成本降下来。”王工透露,目前团队已将模型训练的量子算力需求压缩了60%,预计2027年能实现“单风电场量子模型训练成本低于传统模型”。
另一个挑战是“数据质量”,量子公平性AI对数据的要求更高——任何噪声、缺失或异常数据都可能影响量子态的编码结果,2026年4月,某 2026年绿色服务链与碳封存及绿色电力热度持续上升,相关产业迎来新机遇