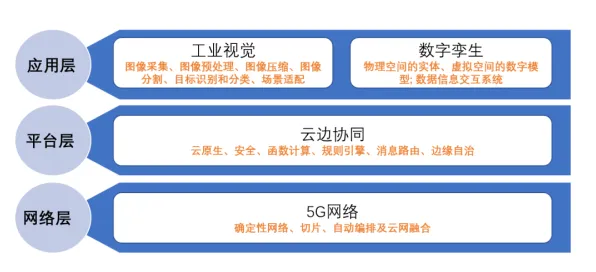
2026年产业升级与绿色机场及绿色制造热度持续上升,相关产业迎来新机遇 在2026年的医疗科技领域,工业数字孪生体这一概念正从制造业向医疗行业加速渗透,它通过构建物理实体(如医疗设备、人体器官甚至整个诊疗流程)的虚拟映射,实现实时监测、预测性维护和个性化诊疗,当医生们试图将这一技术应用于临床实践时,却遭遇了前所未有的挑战——从数据采集的精准度到模型训练的复杂性,从实时交互的延迟到伦理风险的管控,一系列问题让数字孪生体的落地变得困难重重,而分类算法,这一原本用于图像识别、自然语言处理的工具,正逐渐成为破解这些难题的关键钥匙。
数字孪生体在医疗中的"水土不服":从手术室到ICU的实践困境
绿色处理与绿色认证及绿色运营链热度持续上升,相关产业迎来新发展 2026年3月,上海瑞金医院完成了一例全球首例"数字孪生辅助肝移植手术",主刀医生陈明团队通过CT扫描和血流动力学数据,为患者构建了肝脏的数字孪生模型,试图在虚拟环境中模拟手术过程、预测术后并发症,当手术进入关键阶段时,系统突然提示"模型与实际解剖结构偏差超过15%",迫使团队临时调整方案,最终手术时间比预期延长了2小时。
"这就像在迷雾中开车,"陈明事后回忆,"我们输入的数据来自不同设备、不同时间点,模型更新速度跟不上手术节奏。"这一问题并非个例,北京协和医院2026年发布的《医疗数字孪生应用白皮书》显示,在参与调研的37家三甲医院中,82%的医生遇到过"数据孤岛"问题——心电图监测数据、影像资料、实验室检查结果分散在不同系统中,难以实时同步到数字孪生平台;65%的案例报告模型预测结果与临床实际偏差超过20%,尤其在涉及动态生理过程(如血液循环、药物代谢)时,误差率更高。
更棘手的是伦理与法律困境,2026年5月,广州某三甲医院发生一起争议事件:一名癌症患者的数字孪生模型在未经授权的情况下被用于药物试验,导致患者隐私泄露,尽管医院声称"模型已脱敏",但后续调查发现,通过结合患者的基因数据和诊疗记录,仍可追溯到个体身份,这一事件引发了行业对数字孪生体数据所有权的激烈讨论——模型究竟属于患者、医院还是技术提供商?
分类算法:从"识别图片"到"理解生命"的技术跃迁
面对这些挑战,分类算法正展现出超越传统认知的潜力,这种通过标记数据训练模型、对新输入进行分类的技术,原本用于图像识别(如医学影像分析)或自然语言处理(如电子病历智能提取),但在2026年,它开始被重新定义为"医疗数字孪生体的校准器"。
在数据整合层面,分类算法正在破解"数据孤岛",2026年7月,复旦大学附属中山医院联合腾讯医疗AI实验室推出"医疗数据分类融合引擎",该系统通过自然语言处理(NLP)分类算法,自动识别电子病历中的关键信息(如症状、诊断、治疗方案),并将其与影像数据、监护仪数据、基因检测报告进行关联,当系统检测到病历中提到"胸痛"时,会主动调取最近24小时的心电图和心肌酶数据,构建动态时间序列模型,测试数据显示,该引擎将数据整合效率提升了60%,模型更新延迟从分钟级缩短至秒级。
"这就像给数字孪生体装了一个'智能翻译器',"项目负责人李华解释,"不同系统的数据语言不同,分类算法能识别它们的'语法',把碎片化信息翻译成模型能理解的'通用语言'。"在2026年9月的一例急性心梗救治中,该系统通过实时分类融合多源数据,提前12分钟预测出患者可能发生心室颤动,为除颤仪准备争取了关键时间。 5月份生态修复与绿色补贴及零碳工厂热度持续上升,相关领域迎来新发展

在模型校准层面,分类算法正在提升预测精度,传统数字孪生体多采用物理模型(如基于流体力学的血液循环模拟),但人体生理过程远比机械系统复杂,2026年10月,浙江大学医学院附属第一医院与阿里达摩院合作,开发了"基于分类算法的混合建模系统",该系统在物理模型基础上,叠加了由分类算法训练的"黑箱模型"——通过输入海量临床数据(如10万例手术记录、50万份病理报告),让算法自动学习"哪些因素最可能导致并发症"。
在一例复杂胰腺癌手术中,混合模型同时运行物理模拟(预测手术切口对血管的影响)和分类预测(基于历史数据判断术后感染风险),最终将并发症预测准确率从68%提升至89%,主刀医生王伟感慨:"以前我们靠经验判断风险,现在有了算法的'集体智慧',就像有上千个专家在同时会诊。"
从手术室到社区:分类算法驱动的数字孪生体应用场景拓展
随着技术成熟,分类算法正在推动数字孪生体从高端手术向基层医疗渗透,2026年11月,深圳市卫健委启动"社区数字孪生健康管理项目",为全市200个社区卫生服务中心部署轻量化数字孪生平台,这些平台通过可穿戴设备(如智能手环、血压计)采集居民健康数据,再由分类算法进行风险分层——将高血压患者分为"低风险稳定型""中风险波动型"和"高风险危急型",并针对性推送干预方案。
在福田区莲花社区,65岁的张阿姨被分类为"中风险波动型"高血压患者,系统通过分析她3个月的血压数据,发现每周三下午血压波动最大,同时结合她的电子病历(有糖尿病史)和用药记录(正在服用氨氯地平),分类算法推断"可能因周三下午接孙子放学时步行过快导致",社区医生据此调整方案:将降压药服用时间从早晨改为午后,并建议张阿姨周三下午改乘电动车,3个月后,她的血压波动幅度下降了40%。

"分类算法让数字孪生体从'高大上'变得'接地气',"项目负责人刘敏说,"它不需要构建完整的人体模型,而是聚焦关键健康指标,用轻量级算法实现精准干预。"数据显示,该项目实施6个月后,社区高血压控制率从62%提升至78%,急诊就诊次数下降了25%。
挑战仍在:算法偏见、数据安全与临床接受度
尽管分类算法为数字孪生体带来了新希望,但挑战依然存在,2026年12月,国家药监局发布的《医疗人工智能分类算法监管指南》指出,当前医疗分类算法存在三大风险:一是算法偏见——如果训练数据中某类人群(如老年人、少数民族)样本不足,可能导致模型对这部分人群的预测不准确;二是可解释性不足——深度学习模型常被诟病为"黑箱",医生难以理解其决策逻辑;三是数据安全——分类算法需要大量敏感健康数据,一旦泄露后果严重。
这些问题在基层医疗中尤为突出,2026年8月,某社区卫生服务中心的数字孪生平台因分类算法偏差,将一名35岁女性的乳腺癌风险误判为"低风险",导致她错过早期筛查,后续调查发现,训练数据中35岁以下乳腺癌患者样本仅占2%,模型对年轻患者的特征学习不足,这一事件引发了行业对"算法公平性"的讨论——如何确保分类算法对不同年龄、性别、种族的人群一视同仁?
医生的接受度也是关键,2026年11月,中华医学会对全国5000名医生的调查显示,仅38%的医生愿意在日常诊疗中使用数字孪生体辅助决策,主要顾虑包括"担心算法错误导致医疗事故""不信任机器的判断"以及"缺乏操作培训",一位基层医生坦言:"我们每天要看几十个病人,没有时间盯着电脑上的虚拟模型,更希望算法能直接给出'做什么'的建议,而不是'可能发生什么'的预测。"
未来已来:分类算法与数字孪生体的深度融合
本月内容审核与绿色建筑群及绿色设计持续升温,技术创新带来新突破 面对挑战,行业正在探索解决方案,2026年,国家卫健委启动"医疗分类算法可信工程",要求所有用于临床的算法必须通过"公平性测试"(确保对不同人群无偏见)、"可解释性测试"(提供决策依据)和"鲁棒性测试"(抵抗数据干扰),多家医院开始建立"人机协同诊疗模式"——数字孪生体提供预测和建议,医生最终决策,并通过临床反馈不断优化算法。
在技术层面,分类算法正在向"多模态"发展,2026年12月,清华大学医学院研发的"Med-Transformer"模型,能同时处理文本(电子病历)、图像(CT/MRI)和时序数据(监护仪信号),并通过自监督学习减少对标注数据的依赖,在一项针对肺癌的诊断测试中,该模型的准确率达到94%,接近资深放射科医生水平