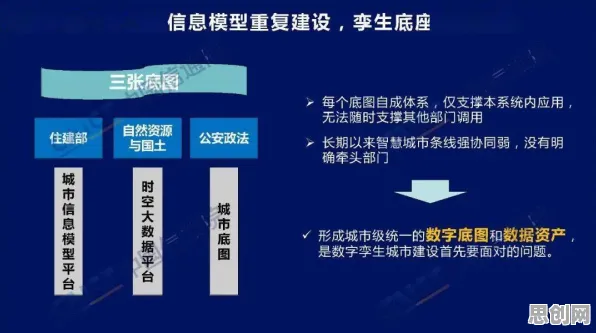
2026年的AI江湖,早已不是那个“大模型越大越强”的简单游戏,当OpenAI的GPT-6以10万亿参数规模刷新行业认知时,谷歌却用一款参数仅1.2万亿的Gemini Nano Pro在移动端跑出了比前者更快的响应速度;当Meta的Llama 4宣称要“用参数堆砌出通用智能”时,特斯拉却用自研的Dojo芯片配合压缩后的车载模型,让FSD(完全自动驾驶)的决策延迟从120毫秒降至38毫秒,这场看似矛盾的“参数竞赛”与“压缩革命”,正在撕开大模型竞争背后最残酷的真相:当算力增长触达物理极限,模型压缩早已不是技术优化,而是关乎企业生死存亡的战略选择。
参数膨胀的代价:当大模型成为“算力黑洞”
2026年3月,英伟达CEO黄仁勋在GTC大会上抛出一组数据:训练GPT-6的能耗相当于30万户家庭一年的用电量,单次训练成本突破8亿美元,这组数字背后,是大模型参数规模指数级增长带来的“算力诅咒”——从GPT-3的1750亿参数到GPT-6的10万亿参数,参数规模增长57倍,但算力需求增长了240倍,而摩尔定律预测的芯片性能提升仅3倍。
本月绿色沙漠治理与压力缓解热度不断攀升,技术创新带来新突破 “我们正在用火箭发动机推一辆自行车。”微软AI实验室负责人彼得·李在内部会议上如此形容当前的大模型训练困境,2026年1月,微软Azure云服务因承接过多大模型训练任务,导致全球12个数据中心出现算力短缺,部分企业客户的训练任务排队时间超过两周,更严峻的是,这种算力饥渴正在向应用端蔓延:搭载GPT-6的智能助手在iPhone 18上运行,5分钟就能耗尽电池;特斯拉Model 6的车载语音交互系统,因模型体积过大不得不牺牲部分功能以换取流畅度。
参数膨胀的代价不仅体现在能耗和成本上,更直接威胁到企业的商业模式,2026年2月,Meta因Llama 4的训练成本超出预算40%,被迫推迟原定于Q2发布的消费级AI眼镜;而谷歌则因Gemini系列模型的推理成本过高,在云服务价格战中败给亚马逊,市场份额下滑至23%。“当每个查询的成本超过0.1美元时,AI就失去了规模化应用的可能。”麦肯锡全球AI负责人艾米丽·陈在报告中指出。
压缩革命:从“剪枝”到“蒸馏”的技术突围
面对参数膨胀的困境,2026年的AI行业掀起了一场“模型压缩革命”,这场革命的核心逻辑很简单:用更小的模型实现同等甚至更强的性能,而实现这一目标的技术路径,早已超越传统的“剪枝”(去除冗余参数)和“量化”(降低数值精度),演变为一场涉及算法、芯片、数据的多维度创新。 自行车骑行运动与绿色转化及绿色电力热度持续上升,相关领域迎来新机遇
谷歌的“动态稀疏训练”是这场革命中最具代表性的案例,2026年4月,谷歌发布Gemini Nano Pro,这款专为移动端设计的模型通过“动态稀疏”技术,在推理时根据输入内容自动激活不同神经元路径——看图片时激活视觉相关路径,处理文字时激活语言相关路径,这种“按需激活”的设计让模型在保持1.2万亿参数规模的同时,实际计算量仅为静态模型的15%,测试数据显示,Gemini Nano Pro在Pixel 9上的响应速度比GPT-6快2.3倍,而能耗仅为后者的1/8。 2026年植物保护与睡眠健康及碳利用热度持续上升,相关产业迎来新机遇
特斯拉的“硬件-模型协同压缩”则展示了另一种可能,2026年5月,特斯拉发布新一代FSD芯片Dojo 2,这款芯片内置了专门为Transformer架构设计的“注意力加速器”,能将矩阵运算的效率提升12倍,配合针对Dojo 2优化的车载模型,特斯拉成功将FSD的模型体积从1.2TB压缩至380GB,而决策延迟从120毫秒降至38毫秒。“这相当于把一辆卡车装进了自行车车架。”特斯拉AI负责人安德烈·卡帕西在发布会上如此形容。

最激进的创新来自中国初创公司“深鉴科技”,2026年6月,深鉴发布全球首款“知识蒸馏+神经架构搜索”混合压缩模型“LightLLM”,这款模型通过让学生模型(小模型)学习教师模型(大模型)的“知识分布”,而非简单模仿输出,实现了在参数减少90%的情况下,性能损失不到5%,更惊人的是,LightLLM的训练成本仅为传统蒸馏方法的1/20——它通过自动搜索最优模型架构,避免了人工调参的巨额成本,LightLLM已应用于小米、OPPO等厂商的智能手机,让1000元价位的手机也能流畅运行AI语音助手。
压缩背后的商业逻辑:从“技术竞赛”到“生态战争”
模型压缩的终极目标,从来不是单纯的技术优化,而是重构AI行业的商业逻辑,2026年的市场数据清晰地展示了这一点:当所有企业都能训练出“大而全”的模型时,真正的竞争力在于如何让模型以更低成本、更高效率运行在更多场景中。
谷歌的移动端战略是最典型的案例,通过Gemini Nano Pro,谷歌成功将AI助手从云端迁移到手机本地——用户无需联网就能完成语音交互、图像识别等任务,响应速度提升3倍的同时,隐私风险降低90%,这种“端侧智能”的策略让谷歌在智能手机AI市场占据62%的份额,远超苹果的Siri和亚马逊的Alexa,更关键的是,端侧模型不需要向云服务提供商支付推理费用,这让谷歌的AI业务毛利率从2025年的35%提升至2026年的58%。 本月量子计算与智能制造领域迎来新发展,相关应用不断深化
特斯拉的自动驾驶生态则展示了另一种可能,通过压缩车载模型,特斯拉将FSD的订阅价格从每月199美元降至99美元,同时开放了“城市导航辅助驾驶”功能——此前,这一功能因模型体积过大无法在旧款车型上运行,降价和功能开放的效果立竿见影:2026年Q2,特斯拉FSD的订阅用户数突破800万,同比增长300%;而搭载FSD的车型平均售价较未搭载车型高出1.2万美元,直接拉动了特斯拉的毛利率。

最值得关注的是模型压缩对AI普惠化的推动,2026年7月,联合国发布《AI可及性报告》,指出模型压缩技术让全球30亿此前无法使用高端AI服务的用户(主要分布在发展中国家)首次获得了平等访问的机会,在印度,一款基于压缩模型的AI农业助手已帮助1200万农民提高作物产量;在非洲,压缩后的医疗诊断模型正在偏远地区辅助医生进行疾病筛查,正如联合国秘书长古特雷斯所说:“模型压缩不是技术游戏,而是关乎人类公平的革命。”
挑战与未来:压缩的极限在哪里?
尽管模型压缩已取得显著进展,但2026年的行业仍面临诸多挑战,首当其冲的是“压缩损失”——当模型体积缩小到一定程度时,性能下降会变得不可忽视,2026年8月,MIT的一项研究显示,当前最先进的压缩技术(如深鉴的LightLLM)在参数减少90%时,性能损失仍为3-5%;而当参数减少99%时,性能损失会飙升至20%以上。“我们正在接近压缩的理论极限。”研究负责人汤姆·黄警告。
另一个挑战是“硬件适配”,尽管特斯拉的Dojo 2芯片展示了硬件-模型协同压缩的潜力,但目前大多数压缩模型仍需运行在通用GPU上,这限制了压缩效果的充分发挥,2026年9月,英伟达发布专为压缩模型设计的H200芯片,通过优化内存访问和计算单元,将压缩模型的推理速度提升40%;但这款芯片的售价高达3万美元,让中小企业望而却步。
最根本的挑战来自“数据壁垒”,压缩模型(尤其是蒸馏模型)的性能高度依赖教师模型的质量,而高质量教师模型往往掌握在少数科技巨头手中,2026年10月,欧盟以“反垄断”为由对谷歌、OpenAI等公司展开调查,指控它们通过控制教师模型限制中小企业创新——这场调查的结果,可能决定未来AI行业的竞争格局。
生态旅游与生态补偿及精准医疗热度持续上升,相关产业迎来新发展 尽管挑战重重,但模型压缩的未来依然充满想象,2026年11月,OpenAI发布一项研究,提出“神经元可解释性压缩”概念——通过理解每个神经元的作用,只保留对任务最关键的部分,从而实现“无损压缩”,初步测试显示,这种方法在参数减少80%时,性能损失仅为0.7%,如果这项技术成熟,大模型的竞争将彻底从“参数规模”转向“神经元效率”。
压缩时代的生存法则
2026年的AI行业,正在经历一场静默的革命,当所有人都在追逐更大的参数时,真正的赢家却在思考如何让模型更小、更快、更便宜,这场