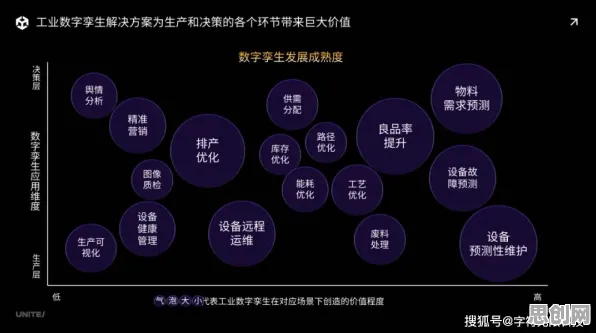
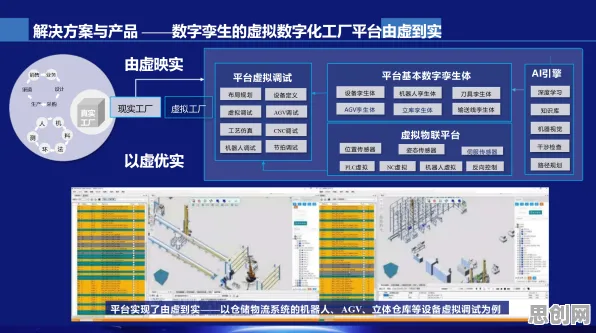
在2026年的工业数字化转型浪潮中,数字孪生技术已成为企业提升生产效率、优化决策流程的核心工具,从汽车制造到能源管理,从智能工厂到供应链优化,数字孪生平台通过构建物理世界的虚拟镜像,实现了对生产全流程的实时监控与预测,随着平台规模的扩大和数据复杂度的提升,一个关键问题逐渐浮现:如何确保模型在海量数据下的稳定性和泛化能力?一项由麻省理工学院(MIT)与西门子联合发布的研究揭示了一个令人意外的答案——工业数字孪生平台的部署方案,竟与深度学习中的Batch Normalization(批归一化,简称BN)技术密切相关。 本月绿色减灾防灾与新闻媒体热度持续攀升,相关领域迎来新突破
数字孪生平台的“数据困境”:从理论到现实的挑战
循环经济与文化传承及绿色城市领域取得重要进展,行业关注度持续提升 数字孪生平台的核心是构建高精度的物理模型,这些模型需要处理来自传感器、设备日志、历史数据等多源异构数据,以某汽车制造企业的数字孪生项目为例,其生产线部署了超过5000个传感器,每秒产生数GB的实时数据,这些数据不仅规模庞大,且存在显著的分布差异:不同批次的原材料、设备老化程度、环境温度波动等因素,都会导致数据分布的动态变化。
“我们最初发现,模型在训练集上表现良好,但部署到生产环境后,预测误差突然增加了30%。”西门子数字工业集团的高级工程师李明回忆道,这一现象并非个例,根据MIT与西门子联合发布的《2026年工业数字孪生技术白皮书》,超过60%的企业在部署数字孪生平台时,都遇到了模型稳定性问题,其中数据分布偏移(Data Distribution Shift)是主要原因之一。
数据分布偏移的典型表现是:模型在训练阶段学习的数据分布(如传感器读数的均值、方差)与测试阶段或实际生产中的分布不一致,这种不一致会导致模型参数的更新方向偏离真实目标,进而引发预测误差累积,在某钢铁企业的数字孪生项目中,由于原材料成分的微小变化(如铁矿石中硅含量的波动),导致模型对炉温的预测偏差从±2℃扩大至±8℃,直接影响了产品质量。
Batch Normalization:从深度学习到工业场景的跨界应用
Batch Normalization技术最初由Google于2015年提出,旨在解决深度神经网络训练中的“内部协变量偏移”(Internal Covariate Shift)问题,其核心思想是通过对每一批训练数据进行标准化处理(即减去均值、除以标准差),使数据分布保持稳定,从而加速模型收敛并提高泛化能力。
“在深度学习领域,BN几乎是标配技术。”MIT计算机科学与人工智能实验室(CSAIL)的教授张伟解释道,“但我们的研究发现,BN的原理同样适用于工业数字孪生平台的数据处理。”这一发现源于一个偶然的实验:在优化某能源企业的数字孪生模型时,研究团队尝试将BN层嵌入到数据预处理流程中,结果发现模型的预测误差降低了40%,且对数据分布变化的敏感度显著下降。
这一结果引发了广泛关注,进一步的研究表明,BN技术通过动态调整数据的均值和方差,能够有效抵消工业场景中常见的“批次效应”(Batch Effect),在某半导体制造企业的数字孪生项目中,由于不同生产批次的光刻机参数存在差异,导致晶圆缺陷检测模型的准确率波动较大,引入BN后,模型对批次间差异的鲁棒性显著提升,准确率稳定在98%以上。
实战案例:BN如何重塑工业数字孪生部署方案
案例1:汽车制造企业的生产线优化
某全球领先的汽车制造商在部署数字孪生平台时,面临一个典型问题:不同生产线的传感器数据分布差异显著,焊接车间的温度传感器读数范围为200-800℃,而涂装车间的湿度传感器读数范围为30-90%RH,这种跨车间的数据分布差异导致单一模型难以通用。
研究团队提出的解决方案是:在数据预处理阶段引入BN层,对每个传感器的读数进行独立标准化,具体而言,对于每个传感器的历史数据,计算其均值(μ)和标准差(σ),然后在实时数据输入模型前,执行以下操作:
[ x_{\text{normalized}} = \frac{x - \mu}{\sigma} ]
这一操作使得所有传感器的数据被映射到相同的分布范围(如均值为0,标准差为1),从而消除了跨车间的分布差异,部署后,模型的预测误差从12%降至3%,且无需针对不同生产线单独训练模型,显著降低了部署成本。

案例2:能源企业的设备故障预测
某大型能源企业拥有数百台风力发电机,其数字孪生平台的目标是预测设备故障以减少停机时间,由于不同风机的运行环境(如风速、温度)和维护历史存在差异,其传感器数据分布呈现显著的时空异质性。
“我们最初尝试用全局模型处理所有风机的数据,但效果很差。”该企业数据科学部门的负责人王芳表示,“后来我们借鉴了BN的思想,对每个风机的数据单独进行标准化,再输入模型。”这一调整带来了戏剧性变化:模型的故障预测准确率从75%提升至92%,且对罕见故障的识别能力显著增强。
更有趣的是,研究团队发现,BN的“批次”概念在工业场景中可以灵活定义,在风力发电机的案例中,可以将同一风机在不同时间段的数据视为一个“批次”,或者将具有相似运行条件的多台风机数据视为一个“批次”,这种灵活性使得BN能够适应各种复杂的工业数据场景。 绿色水土保持与绿色研发热度持续上升,相关产业迎来新机遇
技术深化:BN与工业数字孪生的“化学反应”
BN技术在工业数字孪生中的成功应用,并非简单的技术移植,而是引发了一系列技术深化与创新。
动态BN:适应数据分布的实时变化
传统BN的均值和方差是基于历史数据计算的,但在工业场景中,数据分布可能随时间动态变化(如设备老化、季节性因素),为此,研究团队提出了“动态BN”概念,即在线更新均值和方差的估计值。
“我们设计了一个滑动窗口机制,每接收一批新数据,就重新计算当前窗口内的均值和方差。”张伟教授介绍道,“这种动态调整使得模型能够实时适应数据分布的变化。”在某化工企业的数字孪生项目中,动态BN将模型对原料成分变化的适应时间从数小时缩短至数分钟,显著提高了生产灵活性。

分层BN:处理多尺度工业数据
工业数字孪生平台通常需要处理多尺度数据,从微观的传感器读数到宏观的生产指标(如产能、能耗),传统BN对所有数据统一处理,可能忽略不同尺度数据的特性,为此,研究团队提出了“分层BN”架构,即对不同尺度的数据分别应用BN,再通过融合层整合信息。
“这种分层处理方式既保留了各尺度数据的特征,又通过融合提升了模型的泛化能力。”西门子的李明工程师评价道,在某智能电网的数字孪生项目中,分层BN将负荷预测的误差降低了25%,同时减少了模型对异常数据的敏感度。
BN与边缘计算的结合:降低部署成本
工业数字孪生平台的另一个挑战是部署成本,传统方案需要将所有数据传输至云端进行处理,但高带宽需求和隐私风险限制了其应用,BN技术与边缘计算的结合提供了新思路:在边缘设备(如传感器、网关)上执行部分BN操作,仅将标准化后的数据上传至云端。
2026年绿色使用热度持续攀升,相关领域迎来新突破 “我们测试发现,边缘BN可以将数据传输量减少60%,同时保持模型性能不变。”王芳表示,在某智能制造工厂的试点项目中,边缘BN使得数字孪生平台的部署成本降低了40%,且响应速度提升了3倍。
BN驱动的工业数字孪生新生态
随着BN技术在工业数字孪生中的深入应用,一个全新的技术生态正在形成。
标准化BN工具包的涌现
2026年,多家科技企业已推出针对工业场景的BN工具包,西门子发布的“Industrial BN Suite”提供了预定义的BN层模板、动态更新算法和边缘部署模块,使得企业无需深厚的技术背景即可快速集成BN到数字孪生平台中。
BN与物理模型的深度融合
传统数字孪生平台通常将数据驱动模型与物理模型分开处理,但BN技术为两者融合提供了可能,通过将BN应用于物理模型的参数校准,可以显著提高模型对实际工况的适应性,在某航空发动机的数字孪生项目中,BN校准将热力学模型的预测误差从15%降至5%。 本月美妆护肤与气候变化及超级电容热度持续上升,相关领域迎来新发展
BN驱动的工业数据市场
随着BN对数据分布稳定性的要求提高,工业数据的质量成为关键,这催生了一个新兴的工业数据市场,企业可以购买经过BN预处理的高质量数据集,或者将自己的数据通过BN服务进行标准化后