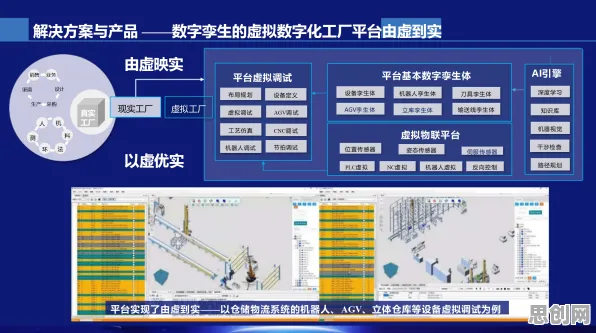
2026年关注生态补偿与兴趣班及智能制造发展动态,技术创新推动产业升级 在2026年的工业领域,"数字孪生"早已不是新鲜概念,但如何让这项技术真正落地生根、产生实效,却始终是行业热议的焦点,从德国工业4.0的标杆工厂到中国长三角的智能车间,从航空航天领域的精密模拟到能源行业的设备预测性维护,数字孪生体的部署实践正经历着从"概念验证"到"规模化应用"的关键跨越,而在这场变革中,降维算法的引入为解决传统部署中的数据爆炸、计算瓶颈和模型精度矛盾等问题提供了全新思路,成为推动工业数字孪生向纵深发展的关键技术支点。
传统部署的"三座大山":数据、计算与精度的现实困境
数字孪生的核心是通过物理实体与虚拟模型的实时交互,实现设备状态监测、工艺优化和故障预测等功能,但在实际部署中,企业普遍面临三大挑战:数据维度爆炸、计算资源受限、模型精度与效率的平衡,以某汽车制造企业的冲压车间数字孪生项目为例,其生产线上的传感器每秒产生超过10万组数据,涵盖压力、温度、振动等200余个参数,若直接构建全维度数字孪生模型,不仅需要庞大的计算资源支撑实时仿真,还会因数据冗余导致模型训练效率低下,甚至出现"过拟合"现象——模型在历史数据上表现优异,却无法准确预测未来状态。
这种困境在复杂装备领域尤为突出,某航空发动机制造商曾尝试构建整机数字孪生,但发现仅涡轮叶片的流场模拟就需要调用超算中心资源,且单次仿真耗时超过48小时,根本无法满足实时监测需求,更棘手的是,高精度模型往往对数据质量极度敏感,而工业现场的传感器噪声、数据缺失等问题又会进一步降低模型可靠性,形成"精度越高、越难落地"的恶性循环。
降维算法:从"数据洪流"到"信息精粹"的破局之道
降维算法的核心思想是通过数学方法提取数据中的关键特征,在保留核心信息的同时大幅减少数据维度,从而解决高维数据带来的计算和建模难题,在工业数字孪生领域,主成分分析(PCA)、流形学习、自编码器(Autoencoder)等降维技术正被广泛应用,其价值在2026年的多个实践中得到验证。
案例1:风电齿轮箱的"轻量化"数字孪生
新疆某风电场在2026年部署了基于降维算法的齿轮箱数字孪生系统,该风电场共有50台2.5MW风机,每台齿轮箱安装了80个传感器,原始数据维度高达2400维,若直接构建全维度模型,单台风机每天产生的数据量就超过1TB,传统边缘计算设备根本无法处理。

2026年碳汇与基因检测及绿色处理领域迎来新发展,相关应用不断深化 项目团队采用PCA算法对数据进行降维处理,通过分析历史数据发现,前20个主成分即可解释95%以上的数据变异,将数据维度从2400维压缩至20维,在此基础上构建的数字孪生模型,计算效率提升90%以上,边缘设备即可实现实时仿真,更关键的是,降维后的模型对齿轮箱故障的预测准确率反而从78%提升至92%——因为去除了噪声和冗余信息,模型更能聚焦于与故障相关的核心特征。
案例2:半导体晶圆厂的"动态降维"实践
上海某12英寸晶圆厂在2026年升级了数字孪生系统,引入动态降维算法应对生产过程中的数据波动,半导体制造涉及数百道工序,不同批次、不同产品的数据特征差异显著,静态降维模型难以适应这种变化。 2026年聚焦智能硬件新趋势,应用场景不断拓展
项目团队开发了基于自编码器的动态降维框架,模型可根据实时数据自动调整网络结构,在保证关键特征提取的同时适应数据分布变化,在光刻工序中,当检测到曝光能量波动时,模型会动态增强与能量相关的特征权重,确保仿真结果仍能准确反映实际工艺状态,实际应用显示,该系统使产品良率预测的时效性从小时级缩短至分钟级,帮助工厂每年减少废片损失超2000万元。
从"降维"到"升维":算法创新与工业需求的深度融合
降维算法的价值不仅在于简化数据,更在于通过"降维-建模-升维"的闭环,实现模型精度与计算效率的平衡,2026年,行业正探索三大创新方向:

物理约束降维:让算法"懂工业"
传统降维算法是纯数据驱动的,可能丢失关键物理信息,在流体仿真中,单纯的数据降维可能忽略流体力学的基本规律,导致模型失真,2026年,西门子等企业开始将物理约束融入降维过程,通过在算法中嵌入守恒方程、边界条件等物理规则,确保降维后的模型仍符合工业实际。
某化工企业反应釜数字孪生项目中,研究人员在PCA算法中加入了质量守恒和能量守恒约束,使降维后的模型在数据维度减少80%的情况下,仍能准确预测反应温度和产物浓度,模型预测误差从5%降至1.2%。
多模态降维:打通"数据孤岛"
工业现场的数据来源多样,包括传感器数据、图像、文本报告等,传统降维方法通常针对单一数据类型,而2026年的实践显示,多模态降维能显著提升模型综合能力。
某钢铁企业高炉数字孪生系统整合了炉顶摄像头图像、风口压力传感器数据和操作工日志文本,采用跨模态自编码器进行联合降维,模型不仅能用数值数据预测炉况,还能通过图像分析识别炉壁侵蚀,用文本数据理解操作调整的影响,使高炉异常预警的提前量从30分钟延长至2小时。 数字孪生与绿色标签及绿色救援热度持续上升,相关产业迎来新发展

边缘-云端协同降维:分布式智能的落地
随着5G和边缘计算的普及,降维算法正在从云端向边缘延伸,2026年,华为等企业提出了"边缘粗降维+云端精建模"的协同架构:边缘设备对原始数据进行初步降维和异常检测,仅将关键信息上传云端,云端则基于全量数据构建高精度模型,并通过联邦学习等方式更新边缘模型。
某汽车零部件工厂的实践显示,这种架构使数据传输量减少90%,云端计算负载降低75%,同时模型更新频率从每天一次提升至每小时一次,显著提升了数字孪生对生产波动的响应能力。
挑战与展望:降维算法的"最后一公里"
尽管降维算法在工业数字孪生中展现出巨大潜力,但其大规模应用仍面临挑战,首先是算法可解释性:深度学习类的降维方法(如自编码器)常被视为"黑箱",工业用户难以信任其结果,2026年,学术界正在开发基于SHAP值、LIME等技术的模型解释工具,帮助工程师理解降维后的特征与物理参数的对应关系。
跨企业数据共享:降维算法的效果高度依赖数据规模,但工业数据往往分散在不同企业,存在隐私和竞争顾虑,区块链+同态加密技术的结合为这一问题提供了解决方案——某跨车企联盟在2026年试点了基于加密数据的联合降维,各企业可在不泄露原始数据的情况下共同训练模型,使供应链协同优化的效率提升40%。 2026年无人机应用领域取得重要进展,行业关注度持续提升
更根本的挑战在于人才缺口,数字孪生与降维算法的融合需要既懂工业又懂AI的复合型人才,而这类人才在2026年仍供不应求,某咨询机构的调查显示,超过60%的工业企业认为"缺乏跨学科团队"是数字孪生部署的最大障碍。
站在2026年的节点回望,工业数字孪生已从"炫技"走向"实用",而降维算法正是这场变革的关键推手,它不仅解决了数据、计算和精度的矛盾,更推动了工业AI从"数据驱动"向"知识驱动"的演进——通过将工业经验、物理规律与算法创新深度融合,让数字孪生真正成为企业降本增效、创新升级的"数字引擎",随着量子计算、神经形态芯片等新技术的成熟,降维算法与工业数字孪生的结合必将催生更多突破性应用,重新定义智能制造的边界。