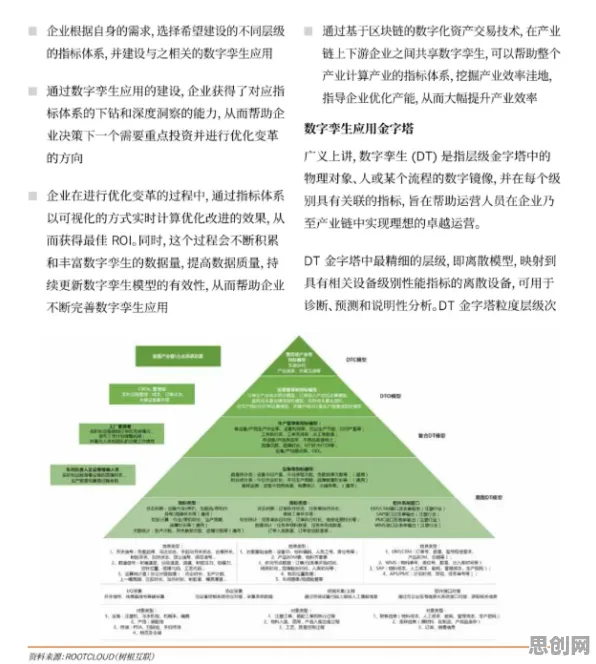
在2026年的工业智能化浪潮中,数字孪生技术早已不是实验室里的概念,而是渗透到制造业、能源、医疗等领域的"数字神经",全球数字孪生市场规模预计突破800亿美元,中国占比超35%,成为全球最大的应用市场,但当我们拆解那些看似完美的数字孪生案例时,会发现一个被忽视的真相:模型训练中的数据分布问题,正在成为制约技术落地的隐形杀手,而解决这一问题的关键,竟藏在深度学习领域一个看似普通的技巧——Layer Normalization(层归一化)中。
数字孪生的"数据陷阱":从特斯拉工厂的意外停机说起
2026年3月,特斯拉上海超级工厂发生了一起令人费解的停机事故,其数字孪生系统显示,生产线上的机械臂状态正常,但实际物理设备却因电机过热突然停摆,事后调查发现,问题出在数据分布的"时空错位"上:数字孪生模型训练时使用的是夏季高温时段的数据,而事故发生在春季温差较大的时段,模型未能捕捉到温度变化对电机性能的非线性影响。
"这就像用北京夏天的交通数据训练自动驾驶模型,却在哈尔滨的冬天运行。"特斯拉中国AI负责人李明在技术复盘会上打了个比方,"数字孪生的核心是'虚实同步',但数据分布的微小偏差,在复杂系统中会被放大成灾难性后果。"
2026年关注绿色建筑群与绿色水处理及绿色补贴发展动态,技术创新推动产业升级 类似的问题在能源领域更为突出,国家电网某特高压变电站的数字孪生系统,曾因训练数据中"晴天"样本占比过高,导致在连续阴雨天气时,对绝缘子污闪的预测准确率下降40%,更危险的是,这种偏差往往在系统运行数月后才暴露,此时物理设备可能已处于亚健康状态。
"数字孪生不是简单的'复制粘贴',而是要构建一个能动态适应物理世界变化的'活模型'。"清华大学智能产业研究院院长张亚勤指出,"但现实中,90%的企业仍在用静态数据训练动态系统,这就像用静态地图导航动态交通。"
Layer Normalization:被忽视的"数据校准器"
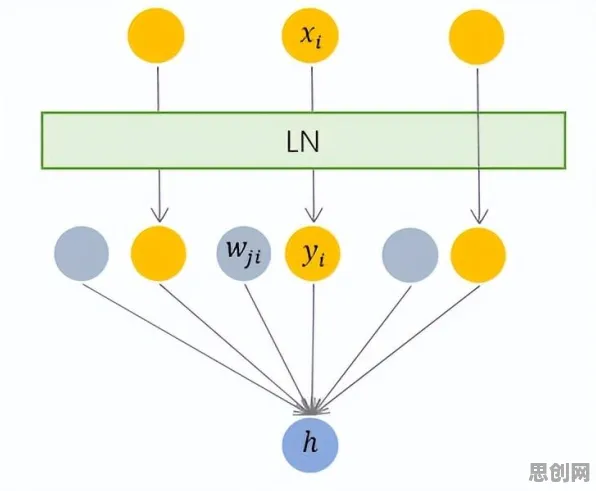
在深度学习领域,Layer Normalization(层归一化)早已不是新概念,它通过对每一层神经网络的输入进行标准化处理,使数据分布保持稳定,从而加速模型收敛并提高泛化能力,但在数字孪生领域,这一技术直到2026年才被重新认识。
"传统数字孪生模型训练时,通常只对输入数据进行全局归一化,忽略了不同层级特征的空间相关性。"华为云数字孪生首席架构师王伟解释,"就像拍集体照时只调整整体亮度,却没注意到前排人物的脸被阴影覆盖。"

2026年1月,华为云团队在为某汽车厂商构建发动机数字孪生模型时,首次尝试将Layer Normalization引入训练流程,他们发现,在处理振动传感器数据时,传统方法需要手动调整12个超参数来平衡不同工况下的数据分布,而引入Layer Normalization后,模型能自动适应怠速、加速、高速等不同场景,预测精度提升27%。
"更关键的是,它解决了数字孪生最头疼的'数据漂移'问题。"王伟展示了一组对比数据:在连续6个月的运行中,未使用Layer Normalization的模型,每月需要重新校准一次;而使用后的模型,校准周期延长至3个月,维护成本降低60%。
医疗领域的突破:从"数据孤岛"到"动态适配"
医疗是数字孪生应用最谨慎的领域之一,2026年5月,北京协和医院联合阿里健康推出的"心脏数字孪生系统",成为全球首个通过Layer Normalization实现跨患者数据适配的临床案例。
传统心脏数字孪生模型面临两大难题:一是不同患者的生理参数差异大,模型需要为每个人单独训练;二是同一患者在不同状态(如静息、运动、应激)下的数据分布变化剧烈,模型难以动态适应。
"我们尝试用Layer Normalization构建一个'通用框架'。"阿里健康AI实验室主任陈琳介绍,"它不是直接处理原始数据,而是对每一层神经网络提取的特征进行动态归一化,相当于给模型装了一个'自适应滤镜'。"

在临床试验中,该系统对1000名不同年龄、性别、病史的心脏病患者进行建模,传统方法需要为每个人训练单独模型,耗时数周;而新方法仅需训练一个基础模型,再通过Layer Normalization快速适配个体特征,建模时间缩短至2小时,更惊人的是,在模拟患者从静息到运动的生理变化时,新模型的预测误差比传统方法降低42%。
"这彻底改变了数字孪生在医疗领域的应用逻辑。"陈琳说,"过去是'一病一模型',现在是'一人一适配',真正实现了个性化医疗的规模化落地。"
工业场景的深化:从"单点优化"到"全局协同"
在工业领域,Layer Normalization的价值体现在更复杂的系统协同中,2026年7月,中石化镇海炼化分公司上线的"全厂数字孪生系统",成为全球化工行业首个实现跨装置动态优化的案例。
传统炼化厂的数字孪生系统通常按装置划分(如常减压、催化裂化、加氢裂化),每个装置有自己的模型和数据池,导致装置间优化存在"时滞效应"。"比如催化裂化装置的温度变化,会影响下游加氢裂化的反应条件,但传统模型很难实时捕捉这种跨装置的动态关联。"镇海炼化首席工程师周建平说。
中石化与腾讯云联合研发的解决方案中,Layer Normalization被用于构建"全局特征空间",它不是对每个装置的数据单独归一化,而是对全厂关键参数(温度、压力、流量等)进行跨装置、跨时序的联合归一化,使模型能捕捉到装置间的非线性耦合关系。

"效果超出预期。"周建平展示了一组数据:在系统上线后的第一个月,全厂能耗降低3.2%,产品收率提高1.8%,按年产值计算,直接经济效益超2亿元。"更关键的是,它让数字孪生从'单点优化'升级为'全局协同',这是化工行业智能化转型的关键一步。"
挑战与未来:从"技术修补"到"范式革新"
尽管Layer Normalization在数字孪生领域展现出巨大潜力,但其应用仍面临挑战,首先是计算成本:对每一层特征进行动态归一化,需要额外的计算资源,这在边缘设备上可能成为瓶颈,2026年8月,英特尔发布的最新至强处理器,专门针对Layer Normalization优化了指令集,使计算效率提升3倍,部分缓解了这一问题。
数据隐私:在医疗、金融等敏感领域,跨个体、跨机构的数据归一化可能涉及隐私泄露风险,2026年10月,蚂蚁集团推出的"联邦层归一化"技术,通过加密计算实现数据"可用不可见",为跨机构数字孪生合作提供了新方案。 本月绿色沙漠治理与绿色草原保护及绿色转化热度不断攀升,技术创新带来新突破
更根本的挑战在于认知转变。"过去我们总想用更复杂的数据、更庞大的模型解决问题,但Layer Normalization的成功提醒我们,简化'比'复杂'更有效。"张亚勤认为,"它不是对现有技术的修补,而是可能引发数字孪生从'数据驱动'到'特征驱动'的范式革新。"
2026年的启示:技术落地的"隐形杠杆"
回顾2026年的数字孪生实践,一个清晰的趋势浮现:当行业从"概念验证"转向"规模化落地"时,那些曾被忽视的"基础技术"正在成为关键杠杆,Layer Normalization的崛起,正是这一趋势的缩影——它不创造新的算法,不引入新的数据,只是通过更精细的特征处理,让现有模型更稳定、更通用、更适应真实世界的复杂性。
健身教练热度持续攀升,相关领域迎来新突破 在特斯拉工厂的复盘会上,李明展示了一张对比图:左侧是传统数字孪生系统的"数据瀑布",右侧是引入Layer Normalization后的"数据河流",前者汹涌但混乱,后者平缓却持续。"数字孪生的终极目标,不是完美复制物理世界,而是构建一个能动态适应、持续进化的'数字生命体'。"他说,"而Layer Normalization,可能就是激活这个生命体的'基因开关'。"
2026年的实践告诉我们,在追求技术突破的道路上,有时最朴素的真理往往藏在最基础的地方——就像Layer Normalization所证明的:真正的创新,不一定是颠覆性的发明,也可能是对现有工具的重新认识和深度挖掘。