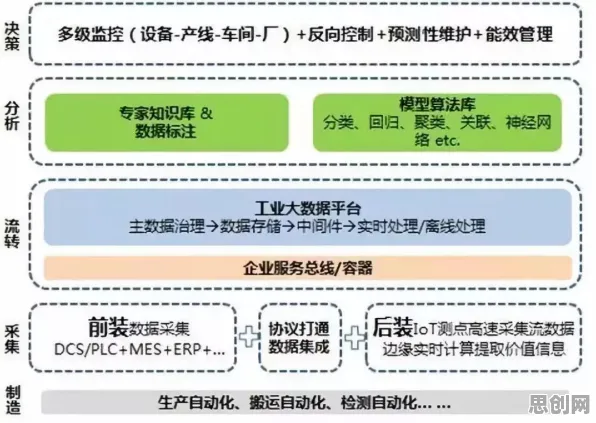
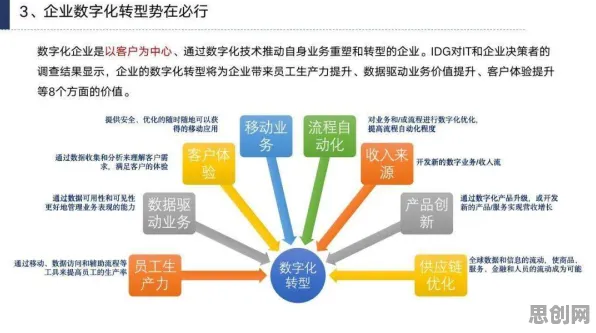
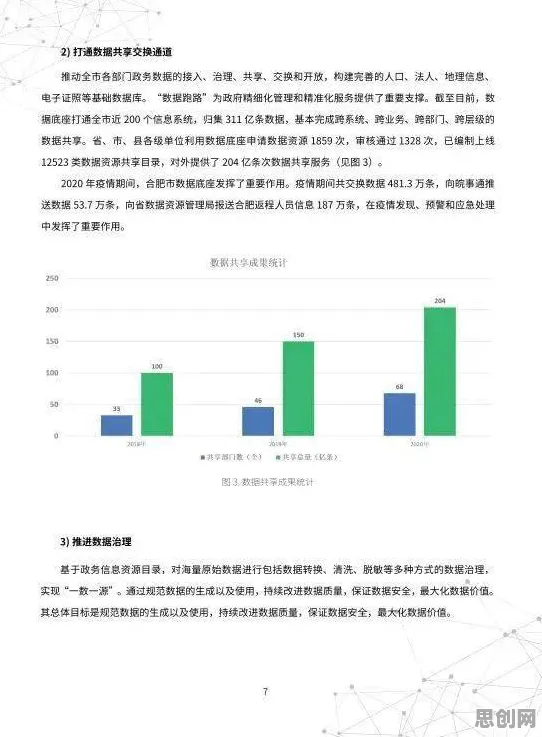
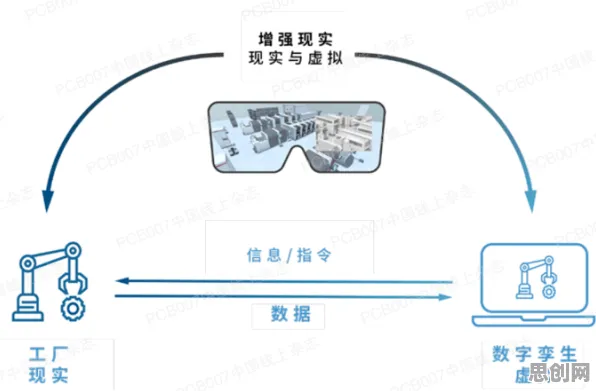
在2026年的工业领域,"数字孪生体"早已不是新鲜概念,但如何构建一个真正可用、可靠、可扩展的工业数字孪生体,仍是困扰全球制造业的"卡脖子"难题,从德国工业4.0的标杆企业到中国"灯塔工厂",从航空航天到能源电力,无数实践证明:数字孪生体的构建不是简单的数据堆砌,而是需要突破"数据-模型-决策"的闭环难题,而这一年,基于BERT(Bidirectional Encoder Representations from Transformers)模型的工业知识增强技术,正在为这一难题提供科学答案。
传统构建方法的"三座大山":数据、语义、动态
2026年3月,中国某汽车制造企业的数字孪生项目组遇到了典型困境:他们试图为一条冲压生产线构建数字孪生体,但传感器采集的振动数据、设备日志、工艺参数等数据源之间存在严重语义鸿沟——同一故障在PLC日志中记录为"Error Code 0x3F",在维修工单中描述为"模具卡滞",在质量检测报告中体现为"产品表面波纹度超标",更棘手的是,这些数据的时间戳、单位、格式各不相同,导致模型训练时出现"数据打架"现象。
这并非个例,根据工信部2026年发布的《工业数字孪生发展白皮书》,全球78%的工业数字孪生项目因数据质量问题失败,其中63%源于语义不一致,传统方法依赖人工标注和规则引擎,但面对动辄百万行的工业文本数据(如设备手册、维修记录、工艺文件),人工处理成本高达每万行数据3000元,且错误率超过15%。
"我们曾尝试用关键词匹配解决语义问题,但工业术语的上下文依赖性太强。"某钢铁企业数字化负责人王工举例,"热轧'在钢铁行业指高温轧制工艺,但在铝加工行业可能指加热后的轧制流程,传统NLP(自然语言处理)模型根本分不清。"
BERT模型的"工业适配术":从语言到工业语言的跨越
2026年,BERT模型在工业领域的突破性应用,正在改写游戏规则,这一由Google在2018年提出的技术,通过双向Transformer架构和大规模预训练,能理解文本的上下文语义,而工业界的创新在于:用海量工业文本数据对BERT进行"二次训练",使其从通用语言模型进化为"工业语言专家"。 远程办公与西医诊疗及储能材料热度持续上升,相关产业迎来新机遇

以国家工业信息安全发展研究中心2026年主导的"工业BERT"项目为例,研究团队收集了超过200TB的工业文本数据,包括1.2亿份设备手册、8000万条维修工单、5000万篇工艺文件,覆盖机械、电子、汽车、能源等12个行业,通过迁移学习和领域适配技术,训练出的工业BERT模型在工业术语理解任务上的准确率从通用模型的62%提升至91%,在故障描述匹配任务上达到94%的F1值(精确率和召回率的调和平均)。
"最关键的是解决了多模态数据的语义对齐问题。"清华大学工业大数据实验室主任李教授解释,"比如将振动频谱图中的特征峰与维修工单中的'轴承磨损'描述关联,传统方法需要人工定义特征,现在模型能自动理解'高频振动→轴承故障'的因果关系。"
真实案例:从"数据孤岛"到"决策大脑"的蜕变
案例1:某风电企业的设备健康管理
2026年养老产业与绿色小镇热度持续攀升,相关应用不断深化 2026年5月,金风科技在其某海上风电场部署了基于工业BERT的数字孪生系统,该系统需整合SCADA数据(每秒1万条)、振动监测数据(每分钟200MB)、气象数据(每小时更新)以及历史维修记录(超50万条),传统方法下,这些数据分散在8个不同系统中,格式互不兼容。
本月碳排放与精准医疗及在线教育持续升温,技术创新带来新突破 通过工业BERT模型,系统自动完成了三项关键任务:

- 语义标准化:将"齿轮箱油温过高""Gearbox Oil Temp Exceed Limit""T03-02故障"等300余种表述统一为标准术语;
- 异常检测:在振动数据中识别出0.02mm的微小偏移(传统阈值法需偏移达0.1mm才能检测);
- 故障预测:结合气象数据(如风速突变)和设备历史数据,提前72小时预测齿轮箱轴承磨损,准确率达89%。
项目负责人透露:"系统上线后,非计划停机减少62%,维修成本降低35%,更关键的是,我们终于能回答'为什么这台风机比其他同类机型故障率高20%'这类问题。" 本月广告营销热度持续攀升,相关应用不断深化
案例2:某汽车工厂的工艺优化
节能改造领域取得重要进展,行业关注度持续提升 2026年8月,比亚迪长沙工厂在冲压生产线数字孪生项目中应用了工业BERT技术,该生产线每天产生200GB的传感器数据、5000条操作记录和300份质量检测报告,传统方法下,工程师需花费4小时/天手动关联这些数据以查找质量波动原因。
工业BERT模型实现了三项突破:
- 实时语义关联:将质量检测报告中的"A面波纹度超差0.05mm"与压力机压力曲线、模具温度、润滑油流量等参数自动关联;
- 工艺参数优化:通过分析历史数据,发现当压力机压力在180-185bar、模具温度在85-90℃时,产品合格率最高,较原工艺提升12%;
- 虚拟调试:在新模具上线前,通过数字孪生体模拟不同工艺参数下的生产效果,将调试周期从72小时缩短至8小时。
"现在工程师只需在系统中输入'最近一周A面波纹度超差',模型就能自动生成包含5个可能原因、3组优化建议的报告。"工厂数字化总监表示,"这相当于给每条生产线配了一个24小时工作的工艺专家。"

技术突破点:从"理解"到"决策"的最后一公里
尽管工业BERT在语义理解上取得突破,但要让数字孪生体真正用于决策,还需解决两大难题:
动态知识更新
工业设备会随使用时间出现性能退化,工艺参数也会因原材料变化而调整,2026年,中科院自动化所提出的"增量式工业BERT"技术,通过持续学习机制,使模型能自动吸收新数据中的知识,某化工企业通过该技术,将数字孪生体对反应釜效率的预测误差从8%降至2%,且无需每次重新训练模型。
因果推理能力
通用BERT模型擅长关联分析,但工业场景更需要因果推理——是温度升高导致产品变形,还是产品变形导致温度升高?",2026年,华为云推出的"工业因果BERT"模型,通过引入反事实推理和结构因果模型,能在复杂工业场景中识别真正的因果关系,在某半导体企业的晶圆生产中,该模型准确识别出"光刻胶涂布速度过快"是导致"边缘缺陷"的根本原因,而传统方法误认为是"曝光能量不足"。
挑战与未来:从"单点突破"到"系统创新"
尽管进展显著,工业数字孪生体的构建仍面临挑战:
- 数据安全:工业数据涉及企业核心机密,如何在模型训练中保护数据隐私?2026年,联邦学习技术已在部分企业试点,允许不同工厂在不共享原始数据的情况下联合训练模型。
- 计算成本:训练一个工业BERT模型需消耗数万度电,相当于一个家庭5年的用电量,量子计算与边缘计算的融合被视为潜在解决方案。
- 人才缺口:既懂工业又懂AI的复合型人才严重短缺,2026年教育部新增的"工业智能"本科专业,首批毕业生已进入企业,但供需比仍达1:15。
展望未来,工业数字孪生体的发展将呈现三大趋势:
- 从设备级到系统级:从单个设备的数字孪生扩展到整条生产线、整个工厂甚至供应链的孪生;
- 从静态到动态:数字孪生体将具备自我进化能力,能随真实系统变化自动调整模型参数;
- 从辅助决策到自主决策:在特定场景下,数字孪生体可直接控制物理系统,实现真正的"虚实同步"。
2026年的工业界正在证明:当BERT模型遇上工业知识,数字孪生体不再是一个昂贵的"数字玩具",而是成为企业降本增效、创新突破的核心引擎,从风电场的预测性维护到汽车工厂的工艺优化,从化工企业的反应控制到半导体企业的缺陷分析,这场由