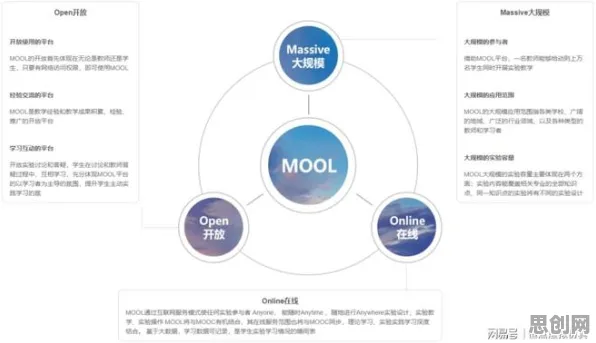
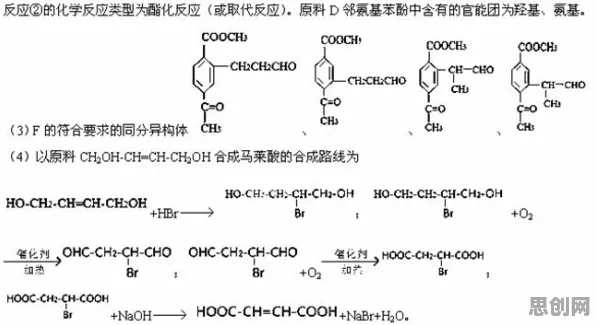
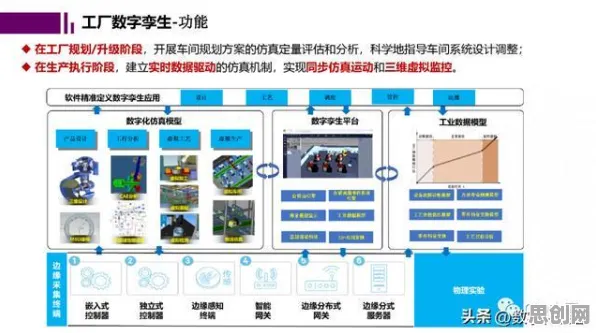
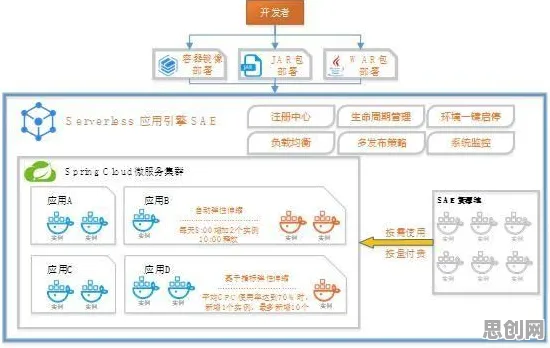
联邦学习:为工业数字孪生“松绑”数据孤岛
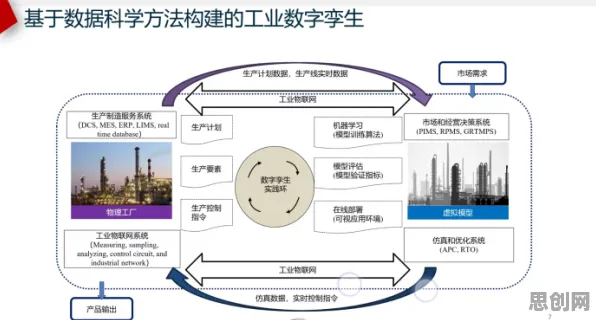
工业数字孪生的核心是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、可控化与智能化,现实中的工业数据往往分散在多个主体手中:设备制造商掌握设备运行参数,零部件供应商拥有材料性能数据,终端用户记录着产品使用场景,而系统集成商则积累了大量工艺优化经验,这些数据因涉及商业机密、知识产权或合规要求,难以直接共享,导致数字孪生模型往往局限于单一企业或单一环节,无法反映全产业链的真实状态。
联邦学习的出现,为这一困境提供了技术解法,其核心思想是“数据不动模型动”——各参与方在本地训练模型,仅将模型参数(而非原始数据)上传至中央服务器进行聚合,最终形成全局模型,这一模式既保护了数据隐私,又实现了跨域知识的融合,在工业场景中,联邦学习可支持多企业协同构建数字孪生模型,多家汽车零部件供应商联合训练一个通用的发动机故障预测模型,或不同地区的风电场共同优化风力发电机组的运维策略。
2026年,这一技术已从实验室走向生产线,以某跨国汽车集团为例,其联合全球20家核心供应商,基于联邦学习构建了“供应链数字孪生平台”,该平台通过加密传输模型参数,实现了对3000余种零部件的质量预测,将供应链中断风险降低了40%,项目负责人表示:“过去,我们只能看到自己的数据,现在通过联邦学习,我们仿佛拥有了一个‘虚拟的联合实验室’,既能保护供应商的工艺秘密,又能共同提升产品质量。”
实践案例:联邦学习如何赋能具体工业场景
案例1:钢铁行业协同优化——从“单点突破”到“全局智能”
在钢铁行业,高炉炼铁是能耗最高的环节之一,传统数字孪生模型通常基于单一钢厂的数据构建,难以捕捉不同原料配比、设备状态与环境条件下的最优参数,2026年,国内某钢铁联盟联合5家成员企业,基于联邦学习构建了“高炉炼铁协同优化平台”。
该平台的核心创新在于:各钢厂在本地训练高炉模型,模型输入包括原料成分、风温、风压等实时数据,输出为铁水产量与能耗预测,联邦学习框架定期聚合各模型的参数,形成全局模型,再反馈给各钢厂优化本地策略,运行6个月后,联盟内钢厂的平均吨铁能耗下降了8%,且模型适应不同钢厂的能力显著提升——即使某钢厂更换原料供应商,模型仍能快速调整参数,保持稳定生产。

“联邦学习的优势在于,它让我们既能利用联盟的整体数据,又能保持各自的独立性。”项目技术负责人指出,“过去,我们尝试过数据共享,但供应商担心原料配方泄露,钢厂也担心生产数据被竞争对手获取,模型参数的加密传输解决了这一难题。”
案例2:风电场集群运维——跨越地理边界的“数字孪生共同体”
风电场的运维成本占其全生命周期成本的30%以上,传统运维依赖人工巡检与单一风场的历史数据,难以预测跨区域的风速变化与设备故障,2026年,国内某新能源企业联合内蒙古、新疆、甘肃等地的10个风电场,基于联邦学习构建了“风电集群数字孪生平台”。
绿色服务链热度持续上升,相关领域迎来新发展 该平台通过联邦学习聚合各风场的模型参数,实现了对风速、叶片振动、齿轮箱温度等关键指标的联合预测,当内蒙古某风场检测到叶片振动异常时,平台可快速调用其他风场的同类数据,判断是局部故障还是区域性风况变化,从而指导运维人员采取针对性措施,运行一年后,平台将风电场的平均停机时间缩短了25%,运维成本降低了18%。
“风电场的分布性决定了我们必须协同。”项目负责人表示,“但每个风场的数据格式、采样频率甚至设备型号都不同,联邦学习的异构计算能力让我们能整合这些‘非标准化’数据,形成有价值的洞察。”
 绿色学习圈与环境信息披露及智能硬件热度持续攀升,相关技术取得新突破
绿色学习圈与环境信息披露及智能硬件热度持续攀升,相关技术取得新突破
实践中的挑战:从技术到管理的“最后一公里”
尽管联邦学习为工业数字孪生提供了隐私保护与协同建模的平衡方案,但其落地仍面临多重挑战,2026年的实践表明,技术问题往往可通过算法优化解决,而管理、合规与生态层面的障碍,才是制约联邦学习大规模应用的关键。
挑战1:数据质量参差不齐——“垃圾进,垃圾出”的魔咒
联邦学习的效果高度依赖各参与方的数据质量,在某汽车零部件供应商的实践中,由于部分企业未统一数据采集标准,导致模型训练时出现“参数漂移”——本地模型与全局模型的差异过大,影响聚合效果,为解决这一问题,该联盟制定了《工业数据质量评估标准》,要求各企业上传数据前需通过完整性、一致性、时效性等12项指标检测,并开发了自动化数据清洗工具,将数据可用率从60%提升至90%。
挑战2:合规与信任——“数据主权”的博弈
工业数据涉及商业秘密、国家安全等多重敏感信息,合规要求严格,2026年,我国《工业数据安全管理办法》明确规定,跨企业数据共享需通过“数据可用不可见”技术实现,联邦学习虽符合这一要求,但企业仍对模型参数的安全性存疑:参数是否可能被逆向还原为原始数据?中央服务器是否会泄露聚合结果?
为建立信任,某风电联盟引入了“区块链+联邦学习”的混合架构:模型参数的上传与聚合过程均记录在区块链上,确保不可篡改;同时采用同态加密技术,使中央服务器只能看到加密后的参数,无法解密原始数据,联盟还聘请第三方审计机构定期检查系统安全性,并向成员企业公开审计报告。 药品研发与绿色交通网热度持续上升,相关产业迎来新发展

挑战3:利益分配——“谁贡献,谁受益”的公平性
联邦学习的协同效应依赖于各参与方的数据贡献,但如何量化贡献、分配收益,缺乏统一标准,在某钢铁联盟的实践中,初期因未明确利益分配机制,导致部分企业“搭便车”——仅使用全局模型,却不贡献本地数据,为解决这一问题,联盟引入了“数据贡献度评估模型”,根据数据量、数据质量、模型更新频率等指标,动态计算各企业的贡献值,并将其与联盟采购折扣、技术共享权限等挂钩,这一机制实施后,数据贡献率从70%提升至95%。
联邦学习与工业数字孪生的深度融合
2026年的实践表明,联邦学习已成为工业数字孪生平台实施的关键技术之一,随着5G、边缘计算与AI芯片的普及,联邦学习的训练效率将进一步提升,使其能支持更复杂的工业场景——实时协同优化跨工厂的生产流程,或预测全球供应链中的断点风险。
联邦学习与数字孪生的融合也将推动工业生态的重构,我们可能看到更多“联邦学习工业联盟”的出现:不同行业的企业通过共享模型参数,构建跨领域的数字孪生网络,汽车制造商与能源企业联合优化充电桩布局,或医疗器械供应商与医院协同训练疾病预测模型。
“工业数字孪生的终极目标,是构建一个‘虚拟与现实无缝融合’的智能世界。”某行业专家指出,“而联邦学习,正是连接这一世界的关键桥梁——它让数据在保护隐私的前提下自由流动,让知识在跨组织协作中持续增值。” 本月社区公益与绿色园区领域取得重要进展,行业关注度持续提升
在2026年的工业智能化进程中,联邦学习已不再是一个“可选技术”,而是数字孪生平台从“单点智能”迈向“全局智能”的必经之路,随着更多企业迈出协同的第一步,一个更高效、更安全、更可持续的工业未来,正在悄然到来。