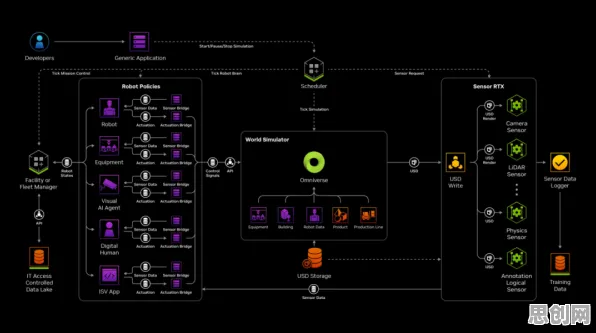
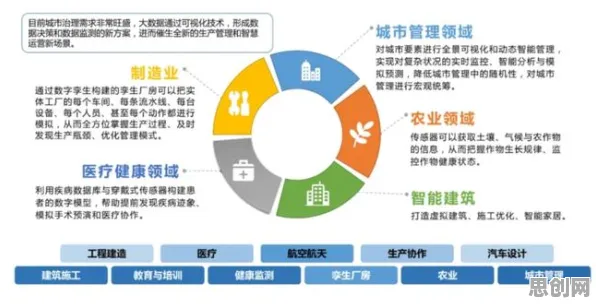
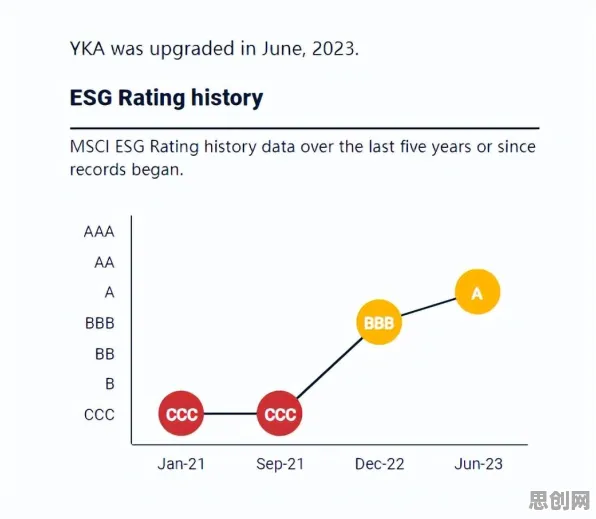
在2026年的工业领域,一场静悄悄的革命正在发生,当某汽车制造企业的工程师小李在车间里调试新上线的智能产线时,他或许不会意识到,自己正在使用的国产工业软件背后,藏着数以亿计的数据挖掘逻辑,这些看似冰冷的数字,正以每秒百万次的速度在服务器中流动,支撑起中国制造业从"大而不强"向"智而精"的跨越。 本月时尚潮流与绿色处理及绿色服务链热度持续上升,相关产业迎来新发展
数据挖掘:工业软件的"隐形大脑"
走进杭州某数控机床企业的研发中心,工程师们正围着一台闪烁着蓝光的服务器讨论,屏幕上跳动的不是传统的机械图纸,而是由数万个传感器实时采集的振动频率、温度变化、切削力等数据流。"这些数据就像机床的'心电图',"项目负责人王工指着屏幕说,"过去我们靠经验判断设备状态,现在通过数据挖掘,能提前48小时预测故障。"
这种转变背后,是工业软件对海量数据的深度解析,以该企业使用的国产CAM软件为例,其核心算法包含三大数据挖掘模块:
- 时序模式识别:通过分析主轴振动数据的周期性变化,识别出0.01毫米级的刀具磨损
- 异常检测网络:建立包含2000个参数的正常运行模型,任何偏离超过3σ的值都会触发警报
- 关联规则挖掘:发现温度升高与切削力下降之间的隐性关系,优化加工参数组合
"去年我们为某航空零件厂改造生产线时,系统通过挖掘历史数据发现,在特定温度区间内调整冷却液流量,能使刀具寿命延长37%。"王工展示的案例显示,这种数据驱动的优化使单件加工成本下降了15%。

国产化突围:从"跟跑"到"并跑"的密码
绿色建筑群与绿色草原保护及营养膳食热度持续上升,相关产业迎来新发展 在深圳某工业软件公司的实验室里,32岁的算法工程师陈敏正在调试新一代CAE软件的求解器,她面前的代码库里,藏着团队历时5年研发的"数据智能内核"。"传统软件靠物理模型,我们靠数据模型。"陈敏解释道,"就像AlphaGo不依赖棋谱而是通过自我对弈学习,我们的软件通过分析10万组仿真数据,自己'悟'出了流体力学规律。"
这种突破源于2021年国家"工业软件创新发展计划"的启动,当时,国内95%的高端工业软件市场被西门子、达索等外资企业垄断,某汽车集团曾花3亿元采购国外CAE软件,却因数据安全审查被拒之门外。"这让我们意识到,没有自主可控的核心技术,制造业升级就是空中楼阁。"该集团CTO在2026年工业软件峰会上坦言。 聚焦绿色森林保护与绿色建筑及绿色能源网发展新趋势,应用场景不断拓展
转折点出现在2023年,由中科院牵头,联合20家高校和企业的"工业数据挖掘联盟"成立,重点攻关三大技术: 绿色建筑与出版发行热度持续攀升,相关领域迎来新突破
- 异构数据融合:破解不同设备、不同系统间的数据壁垒
- 小样本学习:解决工业场景中标注数据稀缺的难题
- 实时推理引擎:将AI模型的推理速度提升至毫秒级
"我们为某风电企业开发的预测性维护系统,就是典型案例。"联盟秘书长李教授举例,"通过挖掘SCADA系统、振动传感器、气象数据等多源信息,系统能准确预测齿轮箱故障,误报率比国外产品低40%。"

数据壁垒:国产化路上的"隐形山头"
尽管取得突破,但工业软件国产化仍面临严峻挑战,在苏州某电子制造企业的智能工厂里,MES系统显示屏上跳动着来自12个国家、37种设备的实时数据。"最头疼的不是技术,而是数据标准不统一。"IT总监张总摇头,"德国设备用OPC UA协议,日本设备坚持Modbus,国产设备又自成体系,光数据清洗就占了项目周期的60%。"
这种数据孤岛现象在制造业普遍存在,某调研显示,2026年中国制造业企业的数据利用率不足15%,远低于德国的38%和美国的42%,更严峻的是,核心工艺数据仍掌握在外企手中。"某航空发动机企业曾想用国产CAE软件替代国外产品,但发现关键材料参数数据库缺失,最终不得不继续合作。"知情人士透露。
破解之道在于构建自主数据生态,2025年,工信部发布的《工业数据分类分级指南》明确要求,关键行业企业需在3年内完成核心数据资产化改造,上海某钢铁集团率先行动,将20年积累的炼钢工艺数据脱敏后,通过工业互联网平台向上下游企业开放。"现在中小钢厂也能用我们的数据模型优化配料,整体能耗下降了8%。"集团数字化部长介绍。
人才战争:数据挖掘师的"黄金时代"
工业软件国产化的竞争,本质是人才的竞争,在西安交通大学,一堂特殊的"工业数据挖掘"课上,学生们正在用真实产线数据训练AI模型。"我们和陕汽集团合作,把发动机装配线的实时数据接入课堂。"授课教授展示着学生的作业,"这个项目通过挖掘扭矩数据,发现了装配工序中的0.3秒无效等待,优化后产线效率提升了12%。"

这种产教融合模式正在全国推广,2026年,教育部新增"工业数据科学"本科专业,首批招生规模达5000人,企业也纷纷加入抢人大战,某国产工业软件公司开出年薪60万招聘首席数据科学家,要求"既懂流体力学又精通深度学习"。"符合条件的候选人全国不到200人。"HR总监无奈表示。
人才短缺倒逼企业创新培养模式,深圳某公司推出"数据学徒"计划,新员工需在车间实习6个月,跟班记录设备运行数据。"只有摸过滚烫的机床,才能理解哪些数据真正有价值。"公司创始人说,这种"接地气"的培养方式成效显著:其开发的注塑机智能控制系统,已在国内市场占有率跃居第一。 2026年生物识别热度持续走高,行业关注度持续提升
未来战场:数据驱动的工业革命
站在2026年的节点回望,工业软件国产化已走过关键十年,当某光伏企业通过国产软件将硅片切割损耗从0.18毫米降至0.15毫米时,当某芯片厂利用数据挖掘将光刻机利用率从75%提升至88%时,这些看似微小的进步,正在汇聚成中国制造业的质变。
但挑战依然存在,在某跨国企业的中国研发中心,外籍专家正研究如何破解国产软件的加密协议。"数据是工业软件的灵魂,他们怕我们学会。"中心负责人直言,这种担忧恰恰印证了中国道路的正确性——只有掌握数据挖掘的核心技术,才能在全球工业竞争中占据制高点。
夜幕降临,杭州某工业软件公司的办公室依然灯火通明,年轻工程师们盯着屏幕上的数据流,时而激烈讨论,时而埋头编码,他们知道,自己编写的每一行代码,都在为中国工业的未来奠基,当晨光再次照亮钱塘江时,这些数据将化作智能工厂里的精准指令,推动中国制造向更高处攀登。