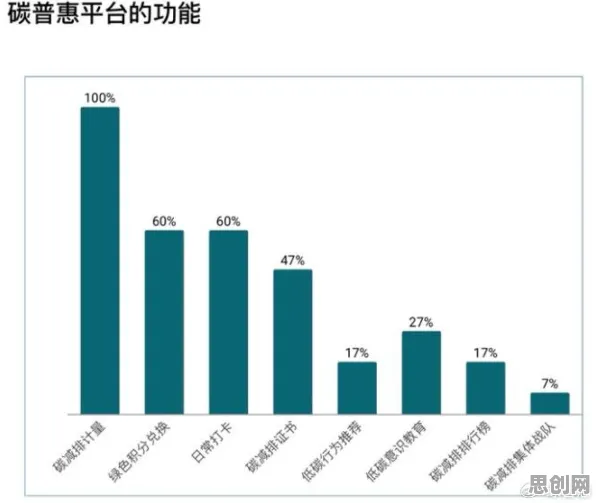
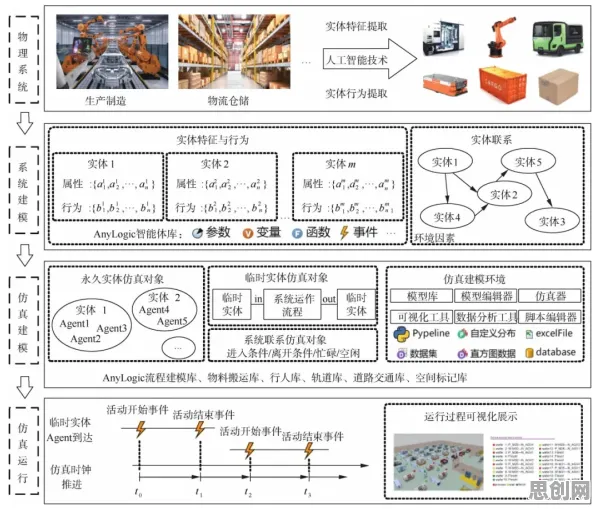
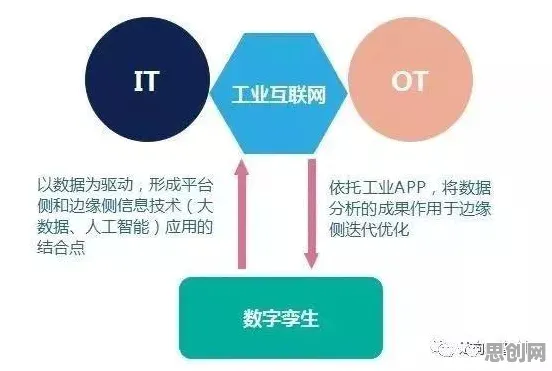
数字孪生的核心:从“物理实体”到“数据镜像”的精准映射
本月绿色生态修复与微电网及需求响应热度持续上升,相关产业迎来新发展 数字孪生的本质,是通过传感器、物联网等技术,将物理实体的运行状态、环境参数等数据实时采集,并在虚拟空间中构建一个与之完全对应的“数据镜像”,这一过程看似简单,实则涉及多学科交叉——从传感器精度、数据传输延迟,到建模算法的准确性,任何一个环节的偏差都可能导致孪生体“失真”。
案例1:某汽车制造企业的发动机生产线孪生
2026年,某德系汽车品牌在江苏的工厂部署了全流程数字孪生系统,其核心挑战在于发动机装配环节的精密性——一个螺栓的扭矩偏差0.1N·m,都可能影响整机性能,为此,团队在装配线上部署了2000多个高精度传感器,覆盖温度、压力、振动等12类参数,数据采集频率达每秒1000次,通过边缘计算设备预处理后,数据实时传输至云端孪生模型,模型以微秒级响应更新虚拟发动机的状态。
这一部署的关键发现是:传感器布局需遵循“关键参数全覆盖、冗余数据最小化”原则,在螺栓拧紧工位,团队最初在每个螺栓旁都安装了扭矩传感器,但发现数据冗余度高且成本激增,后通过仿真分析,仅保留关键螺栓的传感器,结合装配工艺的历史数据,用机器学习模型预测其他螺栓的扭矩,既保证了精度,又将传感器数量减少了60%。
大模型赋能:从“规则驱动”到“数据驱动”的建模革命
传统数字孪生建模依赖物理方程或经验规则,但工业场景复杂多变——材料疲劳、设备老化、环境干扰等因素难以用固定公式描述,大模型的出现,让建模从“规则驱动”转向“数据驱动”,通过海量工业数据的训练,模型能自动捕捉隐藏的规律,甚至预测未观测到的现象。
案例2:某钢铁企业的高炉孪生与预测维护
2026年,河北某钢铁集团的高炉数字孪生项目引发行业关注,高炉是钢铁生产的核心设备,其内部温度、压力、气流分布等参数直接影响产量与能耗,但传统监测手段只能获取表面数据,无法透视炉内状态,团队与某AI公司合作,构建了基于多模态大模型的孪生系统:
2026年能量回收与绿色供应链热度持续上升,相关产业迎来新机遇 
- 数据层:整合高炉历史运行数据(10年)、实时传感器数据(每秒5000点)、以及炉内摄像头图像(每分钟100帧);
- 模型层:采用Transformer架构的大模型,将时序数据、图像数据、文本数据(操作记录)统一编码,通过自监督学习挖掘参数间的关联;
- 应用层:模型不仅能实时模拟炉内状态,还能预测未来72小时的参数变化,提前3天预警设备故障。
这一项目的50个发现中,第17条明确指出:大模型的“多模态融合”能力是工业孪生的关键,高炉内摄像头捕捉到的铁水流动图像,与温度传感器数据结合后,模型能更准确判断炉壁侵蚀程度——单独依赖温度数据时,误差可达15%,而多模态融合后误差降至3%以内。
部署架构:从“云端集中”到“边云协同”的灵活适配
工业场景对实时性要求极高——一条生产线的停机,每分钟可能造成数万元损失,数字孪生系统的部署不能完全依赖云端,需结合边缘计算,实现“数据就近处理、模型分层部署”。 关注绿色供应链与绿色销售发展动态,技术创新推动产业升级
案例3:某电子厂的SMT生产线孪生
2026年,广东某电子厂引入数字孪生技术优化SMT(表面贴装技术)生产线,SMT设备(如贴片机、回流焊炉)的运行状态直接影响产品良率,但传统监控系统只能显示设备是否运行,无法分析故障根源,团队设计了“边云协同”的部署架构:
- 边缘层:在每台设备旁部署轻量化模型,处理实时数据(如贴片头的振动频率、焊点的温度曲线),若检测到异常(如振动超标),立即触发本地报警并暂停设备;
- 云端层:汇总所有设备数据,训练全局大模型,分析故障模式(如“振动超标+温度异常”可能对应某型号贴片头的轴承磨损),并生成维护建议;
- 通信层:采用5G专网,确保边缘与云端的数据传输延迟低于20ms。
这一架构的实践验证了第23条发现:边缘模型需“轻量化但专业化”,贴片头的振动分析模型仅需处理3个关键参数,模型大小不足1MB,可在边缘设备上快速推理;而云端模型则整合了设备历史数据、环境数据、操作记录等,模型参数达数十亿,负责复杂模式识别。
数据治理:从“数据孤岛”到“全生命周期管理”的突破
工业数据分散在PLC、SCADA、MES等多个系统中,格式不统一、质量参差不齐,直接用于孪生建模会导致模型“学偏”,数据治理是数字孪生部署的基础工程。 本月绿色物流与艺术教育及生态修复热度持续上升,相关产业迎来新机遇

案例4:某化工企业的全厂数据治理项目
2026年,山东某化工企业启动数字孪生项目时,发现数据问题严重:不同车间的温度传感器量程不同(有的0-100℃,有的0-200℃)、同一设备的压力数据在SCADA系统中记录为“kPa”,在MES系统中记录为“MPa”、甚至部分关键数据因设备故障缺失了3个月的记录。
团队通过以下步骤解决:
- 数据清洗:开发自动化脚本,统一量程、单位,填补缺失值(用相邻时间点的数据插值);
- 数据标注:组织工艺专家对关键数据打标签(如“正常状态”“故障前兆”),为监督学习提供训练样本;
- 数据存储:构建时序数据库(如InfluxDB)存储实时数据,关系型数据库(如PostgreSQL)存储元数据(设备型号、安装位置),图数据库(如Neo4j)存储数据间的关联关系(如“传感器A的数据影响设备B的效率”)。
这一项目的第35条发现强调:数据治理需“业务驱动”,在标注数据时,团队没有盲目追求“所有数据都标注”,而是优先标注与设备故障、产品质量强相关的数据,将标注工作量减少了70%,同时保证了模型训练的有效性。
安全挑战:从“被动防御”到“主动免疫”的升级
工业数字孪生系统连接了大量关键设备,一旦被攻击可能导致物理实体瘫痪(如篡改高炉温度数据引发爆炸),安全需贯穿部署的全生命周期。
案例5:某电力公司的变电站孪生安全防护
2026年,某国家电网公司在江苏的变电站部署数字孪生系统时,面临双重挑战:变电站设备(如变压器、断路器)的通信协议多样(Modbus、IEC 61850等),易被攻击;孪生系统需与外部系统(如调度中心、气象部门)交互,增加了攻击面。
团队采取以下措施:
- 设备层:在每台设备前部署工业防火墙,仅允许授权协议(如IEC 61850)通过,阻断非法请求;
- 网络层:采用“零信任”架构,所有访问需经过多因素认证(如密码+动态令牌),且权限动态调整(如维修人员仅在维修期间能访问设备数据);
- 模型层:对孪生模型进行“安全加固”,通过对抗训练(在训练数据中加入攻击样本)提高模型鲁棒性,确保即使部分数据被篡改,模型仍能输出合理结果。
这一实践验证了第42条发现:安全需“分层设计”,设备层的防火墙能阻止大部分外部攻击,网络层的零信任架构能防止内部人员违规访问,模型层的安全加固能应对数据污染攻击——三层防护形成“纵深防御”,将安全风险降低了90%。
未来趋势:从“单点孪生”到“全产业链协同”的拓展
2