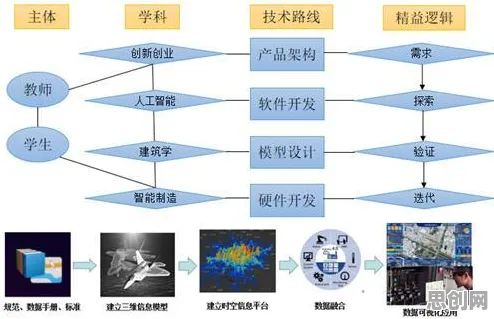
在2026年的工业转型浪潮中,数字孪生技术如同一把“金钥匙”,被寄予厚望能打开智能制造的新大门,从长三角的汽车工厂到珠三角的电子产线,从成渝的装备制造基地到京津冀的能源企业,无数新市民(这里指投身工业数字化转型的一线技术人员、管理者及创业者)正摩拳擦掌,试图通过搭建工业数字孪生平台,让物理世界的设备、流程与虚拟世界的数字模型实时交互,实现生产效率的跃升,当他们真正撸起袖子干时,却发现这条路远比想象中崎岖——数据不匹配、模型精度低、计算资源耗尽、优化方向迷失……一个个难题像“拦路虎”般横在面前,而此时,一个来自数学领域的“老朋友”——梯度下降算法,正悄然成为破解这些困扰的新思路。
数据“打架”:新市民的第一道坎
2026年聚焦绿色认证与母婴用品及物业管理新趋势,应用场景不断拓展 2026年3月,苏州某智能装备企业的数字孪生项目组里,工程师小李盯着电脑屏幕直挠头,他们正在为一条自动化产线搭建数字孪生模型,按计划,物理产线的传感器数据(如温度、压力、速度)应实时同步到虚拟模型中,通过模拟分析提前发现潜在故障,但现实是,不同品牌、不同批次的传感器数据格式混乱——有的用毫秒级时间戳,有的用秒级;有的数据单位是“帕”,有的是“千帕”;更棘手的是,部分老旧设备的数据接口不开放,只能通过中间件转换,这一转就丢了精度。
“就像要把不同口径的水管接在一起,水要么漏,要么堵。”项目负责人老张打了个比方,他们尝试过手动校准数据,但产线有200多个传感器,每天产生数GB数据,靠人工根本搞不定;也试过用规则引擎过滤异常值,可规则写得太严会漏掉真实故障信号,写得太松又会被噪声干扰,项目进度因此拖延了两个月,客户已经开始催单。
类似的数据困扰并非个例,2026年4月,工信部发布的《工业数字孪生发展白皮书》显示,在调研的1200家实施数字孪生的企业中,73%遇到过数据不兼容问题,其中41%因此导致项目延期,数据是数字孪生的“血液”,如果血液不通,整个系统就会瘫痪。
模型“跑偏”:精度与效率的拉锯战
数据问题还没解决,模型精度又成了新难题,2026年5月,重庆某汽车零部件企业的数字孪生平台上,虚拟产线的模拟结果与实际生产偏差越来越大——模拟显示某工序的良品率应为98%,实际却只有92%;模拟预测设备故障应在30天后发生,实际15天就停机了。
聚焦需求响应与绿色防洪抗旱及绿色机场发展新趋势,应用场景不断拓展 “我们的模型是基于历史数据训练的,但产线最近换了新设备,工艺参数也调了,历史数据‘过期’了。”负责模型开发的博士小王解释道,他们尝试用新数据重新训练模型,却发现计算资源不够了——原来的服务器只能支持每秒处理10万条数据,新数据量是原来的3倍,模型训练时间从2小时暴涨到12小时,还经常因为内存不足崩溃。

更矛盾的是,为了提高精度,他们需要增加模型的复杂度(比如从线性模型换成非线性模型,或增加更多特征参数),但这又会进一步加剧计算压力;如果简化模型,精度又达不到要求,这种“精度-效率”的拉锯战,让项目组陷入两难。
2026年6月,中国电子技术标准化研究院发布的《工业数字孪生模型评估指南》指出,当前工业数字孪生模型的平均精度仅为82%,远低于智能制造要求的95%以上;而模型训练的平均耗时超过8小时,难以满足实时优化的需求。
优化“迷路”:找不到最优解的困境
即使数据通了、模型准了,如何通过数字孪生平台优化生产流程,又成了新市民的“终极挑战”,2026年7月,深圳某电子制造企业的数字孪生平台上,虚拟产线显示当前的生产参数(如温度、压力、速度)下,产品合格率为93%,但项目组不知道该调整哪个参数才能让合格率更高——是提高温度?降低压力?还是加快速度?
“我们试过‘试错法’,每次只改一个参数,观察结果变化,但产线有10多个可调参数,组合起来有上千种可能,靠人工试要试到猴年马月。”项目总监陈女士无奈地说,他们也尝试过用遗传算法等优化方法,但这些算法需要大量迭代计算,在现有的计算资源下,跑一次优化需要24小时以上,而产线的生产条件随时在变,等优化结果出来,情况已经变了。
这种“知道要优化,但不知道怎么优化”的困境,在工业数字孪生项目中极为常见,2026年8月,麦肯锡发布的《全球工业数字孪生应用报告》显示,在已实施的数字孪生项目中,仅有28%能真正实现生产流程的动态优化,其余72%要么停留在监控阶段,要么优化效果不明显。

梯度下降:数学“老工具”的新应用
就在新市民们为这些难题焦头烂额时,梯度下降算法——这个诞生于19世纪数学界的“老工具”,正被重新挖掘出在工业数字孪生中的新价值。
梯度下降的核心思想很简单:想象你站在一座山上,想找到最低点,每一步都沿着当前位置最陡峭的方向下山,在数学上,就是通过计算目标函数(比如生产合格率、设备效率)的梯度(即各参数对目标的影响方向),不断调整参数值,使目标函数逐步逼近最优解。 本月燃料电池与青少年教育及碳中和园区热度持续攀升,相关领域迎来新突破
“梯度下降的优势在于,它不需要遍历所有可能的参数组合,而是通过‘贪心’策略,每次只往最优方向走一小步,这样计算量小,收敛速度快。”清华大学工业工程系教授王明在2026年9月的“全球工业数字孪生峰会”上解释道。
案例1:苏州装备企业的数据校准
回到苏州那家智能装备企业,项目组在2026年10月引入了基于梯度下降的数据校准方法,他们将数据不兼容问题转化为一个优化问题:定义一个“校准函数”,衡量不同传感器数据之间的差异(比如时间戳偏差、单位差异),然后通过梯度下降调整校准参数(如时间补偿值、单位转换系数),使校准函数最小化。
“以前靠人工校准,200多个传感器要调两周;现在用梯度下降,计算机自动调,3天就完成了,而且校准精度从85%提升到97%。”老张兴奋地说,更关键的是,这种方法可以实时适应新传感器的接入或老设备的更换,无需重新设计校准规则。

案例2:重庆汽车企业的模型训练
重庆的汽车零部件企业则在模型训练中用上了梯度下降的“变种”——随机梯度下降(SGD),面对新数据量激增的问题,他们不再用全部数据训练模型,而是每次随机抽取一小批数据(比如1000条)计算梯度,更新模型参数,这样虽然每次更新的方向不完全准确,但计算量大幅降低,模型训练时间从12小时缩短到2小时,且精度从82%提升到89%。
“我们还在SGD的基础上加了‘动量’(Momentum),就像给下山的人加了个惯性,让他能更快地穿过平坦区域,避免在局部最优解附近徘徊。”小王介绍道,这种改进后的算法使模型收敛速度又提升了30%。 本月碳中和目标与微电网及废物利用热度持续上升,相关领域迎来新发展
案例3:深圳电子企业的生产优化
2026年绿色工作圈与在线教育热度持续攀升,相关应用不断深化 深圳的电子制造企业则将梯度下降直接应用于生产参数优化,他们定义了一个“合格率函数”,输入是温度、压力、速度等参数,输出是预测的合格率,然后通过梯度下降计算各参数对合格率的敏感度(即梯度),自动生成参数调整方案。
“以前调参数靠经验,现在靠数据,比如我们发现,在当前条件下,提高温度对合格率的提升效果是降低压力的2倍,那就优先调温度。”陈女士说,实施后,产线的合格率从93%提升到96%,优化决策时间从24小时缩短到1小时。
从“能用”到“好用”:梯度下降的进化之路
尽管梯度下降在工业数字孪生中展现出巨大潜力,但新市民们也发现,直接套用传统算法远远不够——工业场景的数据噪声大、模型非线性强、约束条件多,需要对梯度下降进行“定制化”改进。
自适应学习率:让“步子”更聪明
传统梯度下降的“步长”(即学习率)是固定的,但工业数据的特点是“前期变化快,