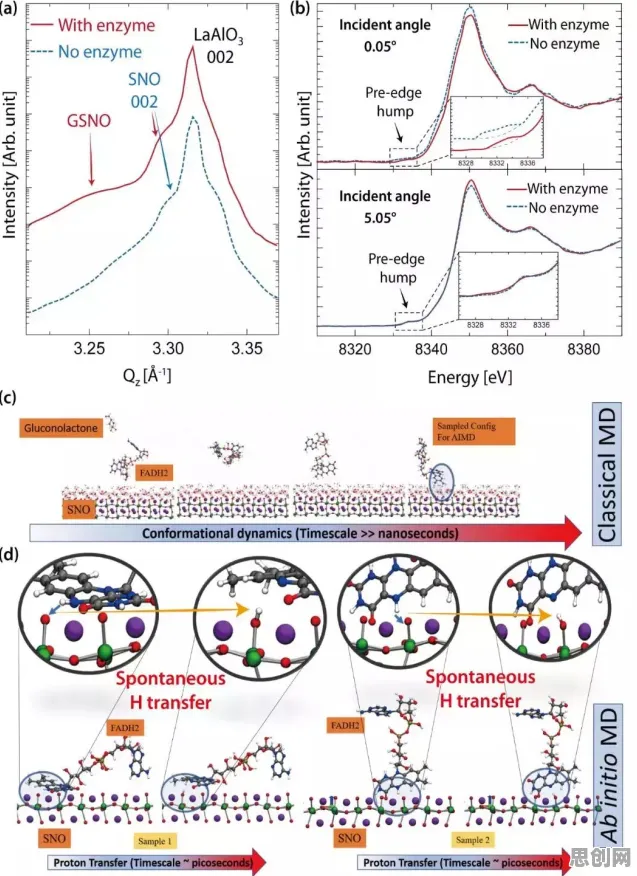
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何将其真正落地并发挥最大效能,仍是众多企业和技术团队探索的核心命题,尤其是在环保要求日益严苛的当下,工业数字孪生平台与智能环保系统的深度融合,正成为推动产业绿色转型的关键力量,我们在多个实际项目中发现了一个关键规律:数字孪生平台的部署质量,直接决定了智能环保系统的运行效率与优化空间,这一发现不仅颠覆了传统环保系统的设计逻辑,更让企业看到了“用数据治污、用模型降耗”的可行路径。
从“被动应对”到“主动预测”:数字孪生如何重构环保逻辑?
传统工业环保系统的痛点在于“滞后性”——企业往往在污染物排放超标、能耗异常后,才通过监测数据发现问题,再手动调整工艺参数,这种“事后补救”的模式不仅成本高,且难以避免环境风险,而数字孪生技术的核心价值,在于通过构建物理实体的虚拟镜像,实现“实时映射+预测推演”,让环保系统从“被动应对”转向“主动预防”。
2026年绿色冷能与绿色应急响应及数字孪生热度持续上升,相关领域迎来新机遇 以2026年某钢铁集团的案例为例:该集团在部署数字孪生平台前,其高炉工序的氮氧化物排放波动频繁,环保设备频繁启停导致能耗激增,技术团队通过在孪生平台中集成高炉温度、风量、原料配比等200余个参数,构建了高精度的工艺模型,当实际生产中某个参数偏离最优区间时,系统会立即在虚拟模型中模拟调整效果,并自动生成优化建议,当风量参数异常时,模型预测显示调整后氮氧化物排放可降低15%,同时减少环保设备启停次数30%,这一改变让该集团年减排氮氧化物超200吨,环保设备能耗下降18%。
更关键的是,数字孪生平台还能通过历史数据训练,预测未来72小时的排放趋势,2026年夏季,该集团所在城市遭遇持续高温,空气质量压力增大,平台提前48小时预测到高炉工序的二氧化硫排放可能超标,技术团队据此提前调整原料配比,避免了限产停产的风险,这种“未雨绸缪”的能力,正是传统环保系统无法比拟的。

部署方案的核心:数据、模型与场景的“铁三角”
数字孪生平台的部署并非简单的“软件安装”,而是需要构建“数据采集-模型训练-场景应用”的完整闭环,我们在2026年的实践中总结出三个关键环节,缺一不可。
数据采集:从“粗放”到“精准”的跨越
工业现场的数据质量直接决定孪生模型的准确性,某化工企业的案例极具代表性:该企业原有环保监测系统仅覆盖10个关键点位,数据采样频率为每10分钟一次,导致模型训练时出现大量“盲区”,部署数字孪生平台时,技术团队增加了300个传感器,覆盖原料仓、反应釜、尾气处理装置等全流程,并将采样频率提升至每秒一次,通过边缘计算设备对数据进行初步清洗,剔除异常值后上传至云端,这一改造让模型对污染物排放的预测误差从±25%降至±5%,为后续优化提供了可靠基础。
模型训练:让机器“理解”工业逻辑
数字孪生的核心是模型,但工业场景的复杂性决定了模型不能“生搬硬套”,以水泥行业为例,其熟料煅烧过程涉及温度、压力、成分等多变量耦合,传统物理模型难以准确描述,2026年,某水泥企业与高校合作,采用“机理模型+数据驱动”的混合建模方式:先基于热力学原理构建基础模型,再通过历史生产数据训练神经网络,修正模型偏差,最终训练出的模型不仅能准确预测氮氧化物排放,还能反向推导出最优原料配比,使吨熟料氨水消耗量下降12%,年节约成本超500万元。
场景应用:从“单点优化”到“全局协同”
数字孪生的价值最终体现在应用场景中,某汽车制造企业的实践提供了典型范本:该企业将数字孪生平台与智能环保系统深度集成,覆盖涂装、焊接、总装等全工序,在涂装车间,系统通过模型模拟不同喷涂参数下的挥发性有机物(VOCs)排放,自动调整喷枪压力和涂料流量,使VOCs排放浓度降低30%;在焊接车间,系统实时监测烟尘浓度,动态调整通风设备风量,既保障工人健康,又减少能源浪费,更值得关注的是,平台还能与企业ERP系统对接,根据订单需求预测未来一周的环保设备运行负荷,提前安排维护计划,避免非计划停机。

智能环保系统的“隐藏规律”:数据密度决定优化上限
在2026年的多个项目中,我们发现一个普遍规律:数字孪生平台采集的数据密度(即单位时间内采集的数据量)与智能环保系统的优化效果呈正相关,这一规律在电力行业尤为明显。
某火电厂的案例极具说服力:该厂原有环保监测系统仅采集烟气流量、二氧化硫浓度等5个参数,数据更新频率为每分钟一次,部署数字孪生平台后,技术团队增加了燃料成分、炉膛温度、脱硝催化剂活性等20个参数,数据更新频率提升至每秒一次,基于高密度数据训练的模型,不仅能精准预测氮氧化物排放,还能识别出催化剂失活的早期迹象,系统通过分析炉膛温度与脱硝效率的关联数据,发现当温度超过1200℃时,催化剂活性会加速下降,据此,电厂调整了燃烧控制策略,将炉膛温度稳定在1150-1200℃之间,使催化剂使用寿命延长40%,年节约更换成本超200万元。
这一规律背后,是工业场景的“非线性特性”——污染物排放与工艺参数的关系往往不是简单的线性关系,而是存在多个临界点,只有通过高密度数据捕捉这些临界点的特征,模型才能准确描述其变化规律,正如某环保技术专家所言:“数据密度每提升一个数量级,模型对复杂工况的适应能力就会提升一个台阶。” 本月绿色转化与乡村振兴热度持续上升,相关领域迎来新发展
挑战与突破:如何跨越“数据孤岛”与“模型黑箱”?
尽管数字孪生在智能环保领域展现出巨大潜力,但部署过程中仍面临两大挑战:一是“数据孤岛”问题,二是“模型黑箱”问题。

数据孤岛:从“各自为政”到“互联互通”
工业现场的数据往往分散在多个系统中:DCS系统记录生产参数,环保监测系统记录排放数据,设备管理系统记录维护记录,这些系统由不同供应商提供,数据格式、采样频率各异,难以直接整合,2026年,某石化企业通过部署工业互联网平台解决了这一问题:该平台采用统一的数据接口标准,将DCS、环保监测、设备管理等系统的数据实时汇聚到云端,再通过数据治理工具进行清洗、标注和关联分析,将反应釜温度数据与尾气处理装置的运行数据关联后,模型发现当温度超过450℃时,尾气中的二氧化硫浓度会显著上升,据此,企业优化了反应釜的温度控制策略,使二氧化硫排放浓度下降20%。
模型黑箱:从“不可解释”到“可追溯”
深度学习模型虽然预测准确,但往往被诟病为“黑箱”——难以解释其决策逻辑,在环保场景中,这一缺陷可能导致企业不敢完全依赖模型建议,2026年,某钢铁企业与科研机构合作,开发了“可解释性数字孪生模型”:通过在神经网络中嵌入物理约束条件(如质量守恒、能量守恒),使模型输出不仅包含预测值,还包含关键参数的贡献度分析,当模型建议调整高炉风量时,会同时显示“风量增加10%可使氮氧化物排放降低15%,其中温度贡献8%、原料配比贡献5%、风量自身贡献2%”,这种“透明化”的模型让企业能够理解决策依据,从而更放心地应用优化建议。
未来展望:数字孪生与智能环保的“深度融合”
站在2026年的节点回望,数字孪生技术已从“概念验证”走向“规模应用”,其与智能环保系统的融合也进入新阶段,这一领域将呈现两大趋势:
一是“全要素孪生”——不仅覆盖生产设备,还将延伸至供应链、能源网络等外部环节,某汽车企业正在探索将供应商的原材料生产数据纳入孪生平台,通过模拟不同供应商的原料对涂装车间VOCs排放的影响,优化采购策略。 本月机器人技术与健康中国及算法推荐热度持续上升,相关产业迎来新机遇
二是“自主优化”——通过强化学习技术