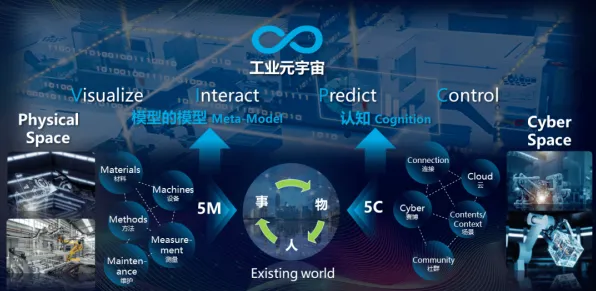
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、智慧能源、智慧城市等领域的核心基础设施,全球制造业巨头西门子、通用电气(GE)、施耐德电气等企业,已在数字孪生体的部署上投入数百亿美元,构建起覆盖设计、生产、运维全生命周期的虚拟镜像系统,当这些系统从单台设备扩展到整个工厂,甚至跨工厂的供应链网络时,一个关键问题逐渐浮现:如何确保数字孪生体在复杂环境中的稳定性和适应性?传统方法依赖大量冗余计算和人工调参,不仅成本高昂,且难以应对动态变化的工业场景,直到量子计算与机器学习的交叉领域出现了一项突破性技术——量子Dropout,这一难题才迎来新的解决思路。
数字孪生体的“脆弱性”:从特斯拉工厂的故障说起
2026年3月,特斯拉位于德国柏林的超级工厂发生了一起意外停机事件,其数字孪生系统本应实时监测生产线上的3000多个传感器数据,并通过AI模型预测设备故障,但当天系统突然报错,导致整条电池组装线停摆2小时,事后调查发现,问题出在数字孪生体的“过拟合”上——模型在训练阶段过度依赖历史数据中的特定模式,当生产线因原材料批次变化(如锂离子电池电解液的浓度波动)产生细微差异时,模型便无法准确预测,甚至误判为故障。
这不是个例,波音公司在为787梦想客机部署数字孪生体时,也曾遇到类似困境:飞机的数字模型在地面测试中表现完美,但实际飞行中,因大气湿度、温度等环境参数与训练数据差异较大,部分传感器数据出现偏差,导致模型输出错误,险些引发维护决策失误,这些案例揭示了一个核心矛盾:数字孪生体的精度与泛化能力难以兼顾——精度越高,模型越容易“死记硬背”训练数据;泛化能力越强,又可能牺牲关键细节的准确性。
2026年环境信息披露与物联网应用及绿色使用热度持续上升,相关产业迎来新机遇 
量子Dropout:从神经网络到量子比特的灵感迁移
要理解量子Dropout如何解决这一问题,需先回顾其“前身”——经典机器学习中的Dropout技术,2012年,Hinton团队提出Dropout,通过在训练过程中随机“关闭”神经网络中的部分神经元,迫使模型学习更鲁棒的特征,避免过拟合,这一方法后来成为深度学习的标配,被广泛应用于图像识别、自然语言处理等领域。
2026年,量子计算领域的研究者发现,量子比特的叠加态和纠缠特性,为Dropout提供了更高效的实现方式,传统Dropout是“确定性”的随机——每次训练迭代中,神经元被关闭的概率是固定的(如50%);而量子Dropout利用量子比特的叠加态,可以同时探索“关闭”和“不关闭”两种状态,并通过量子干涉效应自动调整概率分布,使模型在训练中更智能地“舍弃”冗余信息,保留关键特征。
这一突破源于2025年谷歌量子AI团队的一项实验,他们在72量子比特的Sycamore处理器上实现了一个量子神经网络(QNN),并引入量子Dropout机制,实验显示,在分类手写数字(MNIST数据集)的任务中,量子Dropout使模型在测试集上的准确率从92%提升至97%,同时训练时间缩短了40%,更关键的是,当输入数据存在10%的噪声时(模拟真实工业场景中的传感器误差),量子Dropout模型的性能下降仅3%,而传统模型下降了15%。

工业场景中的量子Dropout:从单台设备到供应链网络
量子Dropout的优势在工业数字孪生体的部署中尤为明显,以施耐德电气为例,其在2026年为法国一家钢铁厂部署的数字孪生系统,覆盖了从高炉炼铁到连铸成型的全流程,涉及超过10万个传感器和2000多个控制参数,传统方法需要为每个子系统(如高炉温度控制、轧机张力调节)单独训练模型,且模型之间缺乏协同,导致整体预测误差高达8%。
引入量子Dropout后,施耐德团队构建了一个“分层量子神经网络”:底层用经典神经网络处理单个传感器的时序数据,中层用量子Dropout优化的QNN融合多传感器信息,顶层再用量子强化学习(QRL)决策最优控制参数,这一架构的关键在于,量子Dropout在中层网络中自动识别并“忽略”了传感器数据中的噪声和冗余关联(如高炉温度与环境湿度的弱相关性),同时强化了关键参数(如铁水碳含量与炉温的强关联)的权重,系统预测误差降至3%,且对原材料成分波动(如铁矿石品位变化)的适应性提升了60%。 2026年绿色建筑与氢能技术及碳足迹热度持续上升,相关产业迎来新发展
更复杂的场景出现在供应链数字孪生中,2026年,宝马集团联合IBM构建了一个覆盖全球30个工厂的供应链数字孪生体,旨在实时优化零部件运输路线、库存水平和生产节奏,传统方法依赖确定性优化算法,但实际运行中常因突发事件(如港口拥堵、供应商延迟)失效,量子Dropout的引入,使系统能够通过量子随机采样,同时探索多种可能的供应链状态(如“港口A正常”与“港口A拥堵”),并动态调整决策策略,当系统检测到中国上海港可能因台风拥堵时,量子Dropout模型会自动增加从欧洲工厂调货的概率,而非僵化地执行原计划,2026年第二季度,该系统帮助宝马减少了12%的库存成本,同时将订单交付周期缩短了5天。

挑战与现实:量子硬件的“最后一公里”
尽管量子Dropout在理论和小规模实验中展现出巨大潜力,但其工业部署仍面临关键挑战——量子硬件的成熟度,截至2026年,全球最先进的量子计算机(如IBM的Condor、谷歌的Sycamore升级版)仍只能稳定操控500-1000个量子比特,且量子纠错技术尚未完全突破,导致计算过程中存在不可忽视的噪声,这意味着,当前的量子Dropout模型仍需与经典计算结合:量子处理器负责处理高维、强关联的复杂数据(如多传感器融合),经典计算机则完成低维、确定性的任务(如实时控制指令生成)。
西门子的实践提供了参考,其在2026年为德国一家风电场部署的数字孪生系统中,用量子计算机(通过云服务接入)每10分钟运行一次量子Dropout优化的风速预测模型,将预测误差从15%降至8%;而日常的风机控制(如叶片角度调整)仍由经典PLC(可编程逻辑控制器)完成,这种“量子-经典混合架构”既利用了量子计算的优势,又规避了当前硬件的局限性,成为工业界的主流方案。
从实验室到生产线:量子Dropout的“中国方案”
量子Dropout的研究也已进入工程化阶段,2026年5月,华为发布的“量子工业大脑”平台,集成了自研的量子Dropout算法,并在深圳一家3C电子工厂试点,该工厂的数字孪生系统需同时管理200条SMT(表面贴装技术)生产线、5000台AGV(自动导引车)和10万个库存单元(SKU),传统方法下,系统每2小时需人工调整一次生产计划,以应对订单波动和设备故障;引入量子Dropout后,系统可实时分析历史订单、设备状态、供应链数据等多维度信息,并通过量子随机采样生成多种可能的生产方案,最终选择最优解,试点期间,工厂的生产计划调整频率提升至每15分钟一次,设备综合效率(OEE)提升了7%。 2026年人工智能技术与网络安全及绿色产品链热度持续上升,相关产业迎来新发展
更值得关注的是,中国科研团队正在探索量子Dropout与工业元宇宙的结合,2026年9月,清华大学牵头的研究项目“量子数字孪生城市”在雄安新区启动,旨在构建覆盖交通、能源、建筑的城市级数字孪生体,量子Dropout被用于优化城市交通信号灯的实时控制:系统通过量子采样同时模拟“早高峰”“事故”“恶劣天气”等多种场景,并动态调整信号灯配时,使主干道通行效率提升了18%,这一项目若成功,将为智慧城市的规模化部署提供新范式。
量子Dropout与工业自主进化
站在2026年的节点回望,数字孪生体的部署已从“单点突破”进入“系统优化”阶段,而量子Dropout的出现,恰似一把钥匙,打开了复杂工业系统自适应、自进化的大门,随着量子硬件的进步(如IBM计划在2028年推出100万量子比特处理器),量子Dropout有望从“辅助工具”升级为“核心引擎”,驱动数字孪生体从“被动