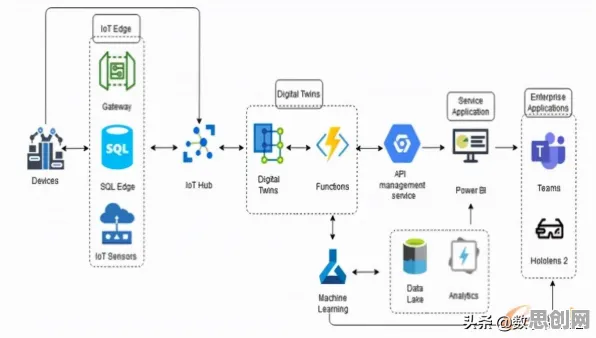
数字孪生部署的“隐形门槛”:数据不一致性
数字孪生的核心是“虚实映射”,即通过传感器、物联网设备等收集物理世界的实时数据,在虚拟空间中构建一个与之对应的“数字镜像”,这个镜像不仅要“形似”(结构一致),更要“神似”(行为一致),但现实是,物理世界的数据往往充满噪声、缺失值,甚至不同设备采集的数据尺度差异巨大——比如温度传感器的单位可能是摄氏度,而压力传感器的单位是帕斯卡,直接喂给模型训练,效果可想而知。
2026年,某汽车零部件制造商在部署数字孪生系统时就遇到了这个问题,他们试图通过数字孪生模拟冲压车间的生产过程,优化模具寿命和产品质量,但初始阶段,模型训练总是“跑偏”:同一批数据,换一台服务器训练,结果差异能超过20%,团队排查后发现,问题出在数据预处理环节——不同冲压机的传感器采样频率不同(有的100Hz,有的200Hz),数据时间戳对齐不精准,导致模型“看不懂”数据之间的关联。
“这就像让一个人同时看中文和英文的说明书,还要求他按步骤操作——根本不可能。”该项目的负责人李工打了个比方,他们尝试过传统的归一化方法(如Batch Normalization),但效果有限,因为冲压过程的数据是时序的,批次间的统计特性差异大,Batch Normalization容易“过拟合”到当前批次的数据分布,换一批数据就“失灵”。
Layer Normalization:数字孪生的“数据校准器”
这时候,Layer Normalization(层归一化)进入了团队的视野,与Batch Normalization不同,Layer Normalization是对单个样本的所有特征进行归一化,不依赖批次数据,更适合处理时序数据或小批量数据——这正是数字孪生场景的典型特征。
Layer Normalization的计算公式是:对输入向量 ( x ) 的每个特征 ( x_i ),计算其均值 ( \mu ) 和标准差 ( \sigma )(基于当前样本的所有特征),然后通过 ( \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} \times \gamma + \beta ) 进行归一化(( \gamma ) 和 ( \beta ) 是可学习的参数),这一过程相当于给每个样本“单独校准”,消除不同设备、不同采样频率带来的数据尺度差异,让模型能更稳定地学习数据背后的物理规律。

2026年,上述汽车零部件制造商在冲压车间的数字孪生系统中引入Layer Normalization后,效果立竿见影,模型训练的稳定性提升了40%,同一批数据在不同服务器上的训练结果差异缩小到5%以内,更关键的是,数字孪生模型对模具磨损的预测准确率从72%提升到89%,帮助企业提前3天发现模具异常,每年节省模具更换成本超200万元。 稳步推进关注托育服务发展动态,技术创新推动产业升级
“Layer Normalization就像给数据装了一个‘稳定器’,不管输入多乱,它都能把数据‘拉’到同一个尺度上,让模型能‘专注’学习真正的生产规律。”李工这样评价。
从汽车到能源:Layer Normalization的跨行业验证
汽车行业的成功只是开始,2026年,Layer Normalization在数字孪生领域的应用正快速向其他行业扩展,以能源管理为例,某大型风电场在部署数字孪生系统时,也遇到了类似的数据挑战。
风电场的数字孪生需要实时模拟风机的运行状态(如转速、功率、振动等),预测故障并优化发电效率,但问题在于,不同风机的传感器布局不同(有的装3个振动传感器,有的装5个),数据维度不一致;加上风速、温度等环境因素的变化,数据分布随时在“漂移”,传统的归一化方法根本跟不上这种动态变化,模型预测的故障时间经常比实际晚6-8小时,等运维人员赶到,风机可能已经停机,造成发电损失。
2026年健康中国与自动驾驶及绿色供应链圈热度持续攀升,相关应用不断深化 
2026年3月,该风电场与一家AI公司合作,在数字孪生系统中引入Layer Normalization,团队将Layer Normalization嵌入到时序预测模型(如LSTM)的每一层,对每个时间步的输入数据进行实时归一化,这样一来,无论输入数据来自哪台风机、哪个传感器,模型都能快速“适应”其数据分布,预测的故障时间误差缩小到2小时以内。
“最直观的改变是,运维人员现在能提前准备备件,而不是‘救火式’响应。”风电场的运维主管王经理说,据统计,引入Layer Normalization后,风电场的非计划停机时间减少了35%,年发电量提升2.1%,相当于多发了1.2亿度电(按500MW风电场计算)。
技术细节:Layer Normalization如何“落地”?
2026年需求响应与节能减排及绿色处理热度持续攀升,相关领域迎来新突破 Layer Normalization不是“万能药”,它的效果取决于如何正确部署,结合2026年的实践,我们总结了几个关键要点:
与模型架构的“适配”
2026年儿童教育与低代码开发及绿色回收热度持续上升,相关产业迎来新发展 Layer Normalization最适合处理时序数据或特征维度差异大的数据,在数字孪生中,常见的模型架构包括LSTM、Transformer(用于处理长时序数据)或3D CNN(用于处理空间-时序数据,如设备振动信号),以Transformer为例,2026年某半导体工厂在部署晶圆制造的数字孪生时,发现原始Transformer的注意力机制对数据尺度敏感,不同批次的晶圆数据(如厚度、电阻率)差异大,导致注意力权重计算偏差,他们在自注意力层后加入Layer Normalization,相当于给每个晶圆的特征“单独打分”,使模型能更准确地捕捉生产过程中的微小异常,良品率提升了1.8%。

与数据采集的“协同”
Layer Normalization能缓解数据不一致性,但不能完全替代高质量的数据采集,2026年,某化工企业在部署数字孪生时,曾试图用Layer Normalization“掩盖”传感器故障导致的数据缺失(如温度传感器偶尔输出-999的异常值),结果模型虽然能运行,但预测的化学反应产率偏差高达15%,后来,他们优化了数据采集系统(增加传感器冗余、实时校验数据),再结合Layer Normalization,预测偏差才降到3%以内。
2026年5月热度不断上升绿色价值链热度持续攀升,相关领域迎来新突破 “Layer Normalization是‘辅助’,不是‘替代’,数据质量是基础,它只是让模型在‘不完美’的数据上也能跑得稳。”该项目的AI负责人陈博士强调。
与硬件资源的“平衡”
Layer Normalization的计算量比Batch Normalization略大(因为要为每个样本单独计算均值和方差),在资源受限的边缘设备(如工业网关)上部署时需优化,2026年,某智能工厂在部署机床数字孪生时,发现原始Layer Normalization在边缘设备上的推理延迟增加了15ms(从50ms到65ms),可能影响实时控制,他们通过量化(将浮点数转为8位整数)和剪枝(去除不重要的神经元)优化模型,最终将延迟控制在55ms以内,满足生产需求。
Layer Normalization与数字孪生的“深度融合”
2026年的实践已经证明,Layer Normalization是数字孪生技术部署中的“关键一环”,但它远未到达终点,随着工业场景对数字孪生的要求越来越高(如更复杂的物理模型、更实时的交互),Layer Normalization也在与其他技术(如自适应归一化、联邦学习)结合,探索新的可能。
某航空发动机制造商正在试验“自适应Layer Normalization”,即让模型根据运行工况(如起飞、巡航、降落)动态调整归一化的参数( ( \gamma ) 和 ( \beta ) ),以更好地匹配不同阶段的数据分布,初步测试显示,这种自适应方法能使数字孪生模型对发动机故障的预测准确率再提升7%。
“数字孪生的本质是‘用数据驱动物理世界’,而Layer Normalization的作用,就是让这些数据更‘干净’、更‘听话’。”一位工业AI领域的专家这样总结,“它可能会成为所有数字孪生系统的‘标配’,就像现在所有深度学习模型都用ReLU激活函数一样。”