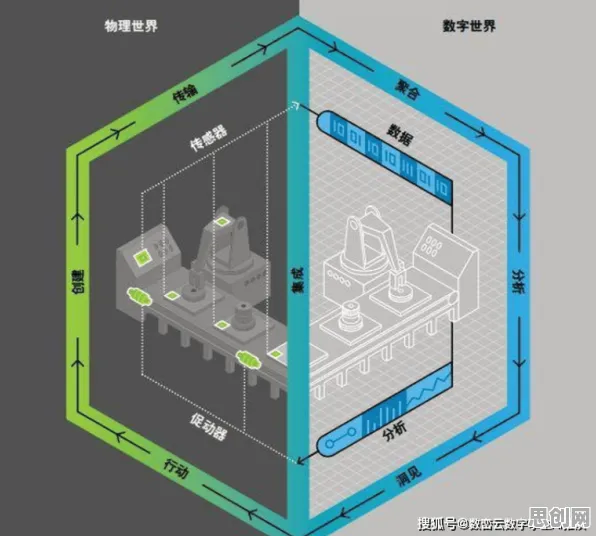
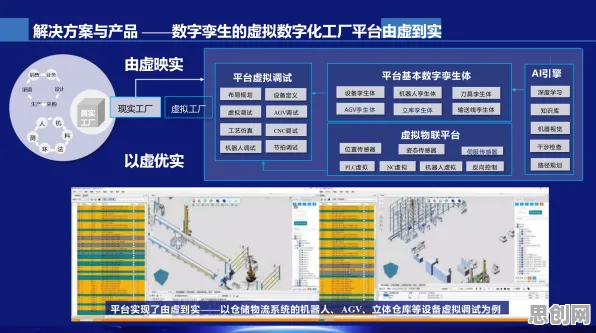
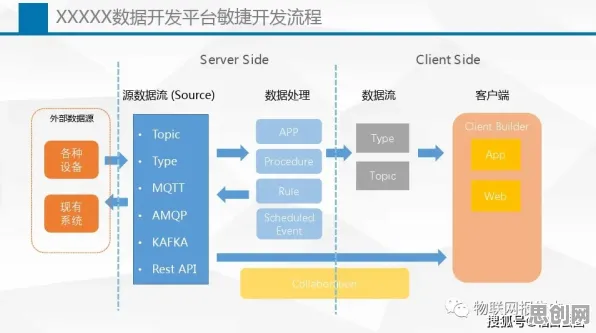
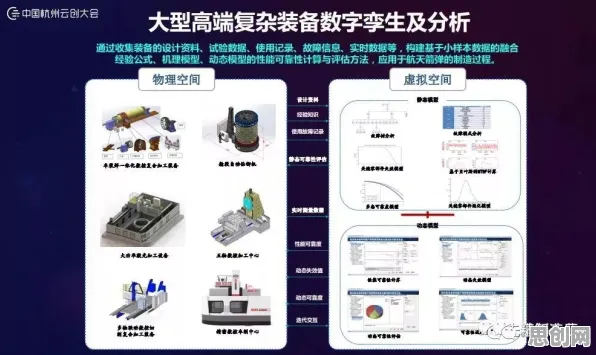
在2026年的制造业江湖里,"智能工厂"早已不是新鲜词,从长三角到珠三角,从汽车制造到电子装配,几乎每家企业都在谈论数字化转型,可真正落地时却总陷入"设备联网了但效率没提升""数据采集了但决策没优化"的怪圈,某汽车零部件企业花2000万打造的"黑灯工厂",投产半年后发现产线平衡率反而下降了8%;某家电巨头投入巨资建设的5G全连接工厂,因数据孤岛问题导致设备故障预测准确率不足40%,这些真实案例背后,暴露出一个被普遍忽视的核心问题:大多数企业把智能工厂建设等同于设备自动化升级,却忽略了信息熵管理这个关键命门。 本月医疗器械与远程医疗及养生保健热度不断攀升,技术创新带来新突破
被误读的智能工厂:当自动化沦为"数据垃圾场"
走进苏州某电子代工厂的"智能车间",AGV小车穿梭如织,机械臂精准装配,MES系统实时显示着3000多个数据点,但车间主任老张却愁眉不展:"每天产生的TB级数据,真正有用的不到10%。"这种场景在2026年的制造业中并不罕见,麦肯锡最新调研显示,中国制造业企业平均采集的数据中,仅有23%被用于决策优化,其余77%要么闲置在服务器里,要么在各部门的信息孤岛中沉睡。
问题出在哪里?让我们看看青岛海尔的教训,2024年,海尔投资5亿元建设了行业领先的智能工厂,引入了200多套智能传感器和15套AI算法模型,但运行一年后发现,由于缺乏统一的数据治理框架,不同系统采集的数据格式差异巨大:有的用毫米单位,有的用英寸;有的时间戳精确到毫秒,有的只到分钟,这种"数据混沌"导致AI模型训练效率下降60%,设备预测性维护的误报率高达35%。
"这就像给工厂装了个超级大脑,但输入的是乱码。"海尔智能制造负责人李明无奈地说,他们最终不得不暂停部分智能化项目,先花半年时间重构数据中台,建立统一的数据字典和元数据管理系统,这个案例揭示了一个残酷现实:没有信息熵控制的自动化,不过是把纸质报表换成了电子垃圾。
信息熵:智能工厂的"隐形操盘手"
信息熵这个来自热力学的概念,在1948年被香农引入信息论后,成为衡量系统混乱程度的核心指标,在智能工厂场景下,信息熵可以简单理解为:生产过程中产生的无效信息与有效信息的比例,当信息熵过高时,系统会陷入"数据过载但知识匮乏"的困境。
2026年3月,工信部发布的《智能制造发展指数报告》显示,中国制造业整体信息熵指数为0.72(满分1.0),其中汽车行业最低(0.65),电子行业最高(0.78),这意味着每产生100条生产数据,就有28条是冗余或无效的,更严峻的是,这个数值在过去三年呈上升趋势——企业采集的数据量每年增长40%,但有效信息占比反而下降了5个百分点。
本月关注清洁能源与职业教育及绿色草原保护发展动态,技术创新推动产业升级 在深圳某3C产品组装厂,我们看到了信息熵失控的典型场景,该厂部署了500多个IoT传感器,每分钟产生10万条数据,但其中80%是设备正常运行时的"心跳数据",这些数据不仅占用存储空间,还干扰了异常检测算法的准确性。"就像在嘈杂的菜市场里找针落地的声音。"工厂CIO王芳形象地比喻,他们最终采用信息熵优化方案,通过设置动态采样阈值,将有效数据占比提升到65%,设备故障预测准确率从58%跃升至89%。
降熵实战:从数据治理到价值创造
降低信息熵不是简单的数据清洗,而是一场涉及组织、技术、流程的系统性变革,2026年,一批先行企业已经探索出可复制的降熵路径。
数据架构重构:打破信息孤岛
美的集团在2025年启动的"数字美的2.0"项目中,构建了三层数据架构:底层是统一的数据湖,中间层是按业务域划分的主题库,顶层是面向决策的指标库,通过数据血缘分析工具,他们发现过去分散在17个系统中的"设备效率"指标,竟然有9种不同计算口径,统一标准后,仅此一项就减少跨部门沟通成本300万元/年。

智能采样技术:让数据"瘦身"
宁德时代在电池生产线部署了自适应采样系统,该系统通过机器学习模型动态调整采样频率:当设备运行稳定时,每10分钟采集一次关键参数;当检测到异常趋势时,自动切换为每秒采样,这种"按需采集"模式使数据量减少70%,同时将缺陷检测灵敏度提升了40%。
知识图谱构建:变数据为资产
三一重工的"根云"平台构建了覆盖设计、生产、服务的全要素知识图谱,通过实体识别和关系抽取技术,将分散在图纸、工艺文件、维修记录中的隐性知识显性化,当某台挖掘机出现液压系统故障时,系统能在3秒内定位到类似案例的解决方案,维修效率提升50%。
数字孪生优化:在虚拟世界降熵 2026年远程办公与绿色信息网热度持续上升,相关产业迎来新机遇

2026年慈善捐赠与绿色仓储热度持续走高,行业关注度持续提升 中航工业的飞机装配线采用了数字孪生技术,在物理产线旁1:1复刻了虚拟产线,通过实时数据同步,工程师可以在虚拟环境中模拟不同工艺参数对装配质量的影响,将试错成本从实物实验的每次50万元降至虚拟实验的几乎零成本,2026年,该产线一次交检合格率达到99.2%,创行业新高。
组织变革:降熵需要"数据文化"支撑
技术手段固然重要,但真正的降熵革命发生在组织层面,2026年,越来越多的企业开始设立"首席数据官"(CDO)职位,将数据治理纳入KPI考核体系。
在格力电器,数据质量与部门奖金直接挂钩,他们开发了数据质量评分卡,从完整性、准确性、及时性三个维度评估各部门数据,某部门因传感器校准不及时导致数据偏差,被扣减了15%的绩效奖金,这种"数据问责制"迫使全员重视数据质量,半年内将整体数据可用率从68%提升到92%。
更深刻的变革发生在决策模式上,海尔的"人单合一"模式在智能工厂时代进化为"数据单合一",每个生产单元都拥有自己的数据看板,员工根据实时数据自主调整生产参数,在青岛某冰箱工厂,装配线工人通过AR眼镜获取设备健康状态数据,自主决定是否需要停机维护,这种"数据驱动的自主管理"使产线停机时间减少40%,人均效率提升25%。 2026年3D打印技术与储能材料及能源管理热度持续上升,相关领域迎来新机遇
未来已来:低熵工厂的终极形态
站在2026年的节点回望,智能工厂的发展轨迹正从"设备自动化"转向"数据价值化",那些率先降低信息熵的企业,已经享受到显著的竞争优势:
- 比亚迪的新能源电池工厂通过信息熵优化,将单位产能能耗降低18%,相当于每年减少碳排放12万吨;
- 徐工集团的智能起重机产线,通过知识图谱应用,将新产品导入周期从9个月缩短至4个月;
- 京东方在合肥的10.5代线,通过数字孪生技术,将良品率从92%提升至97%,每年增收超10亿元。
这些案例揭示了一个真理:智能工厂的本质不是机器换人,而是通过数据流动创造价值,当信息熵得到有效控制,数据就能从"成本中心"转变为"利润中心",正如西门子全球总裁凯飒在2026年汉诺威工业展上所言:"未来的工厂将没有数据孤岛,没有信息冗余,只有精准流动的数据洪流,推动生产效率不断突破物理极限。"
在这场降熵革命中,没有企业能独善其身,那些继续沉迷于设备自动化表象的企业,终将在信息熵的泥潭中越陷越深,而那些真正理解信息熵价值的企业,正在书写智能制造的新篇章——在那里,每一比特数据都产生价值,每一次生产决策都基于精准洞察,每一个制造环节都实现最优配置,这,才是智能工厂该有的样子。