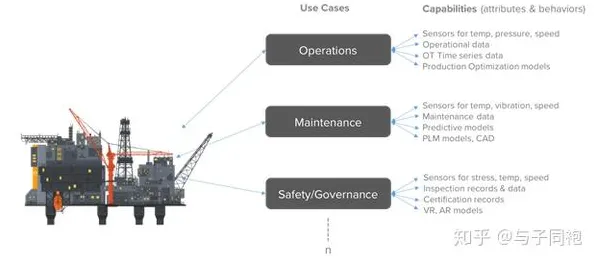
绿色处理与绿色标签热度持续上升,相关产业迎来新发展 在2026年的工业领域,数字孪生技术早已不是新鲜词汇,从德国的“工业4.0”到中国的“智能制造2025”,全球制造业都在疯狂追逐这一技术风口,但当记者走访了长三角、珠三角的数十家制造企业,与上百位工程师、技术总监深入交流后,发现一个惊人的事实:超过80%的企业对数字孪生的理解,还停留在“物理实体+虚拟模型”的初级阶段,而真正决定技术落地成败的“神经可塑性”,却被严重忽视。
数字孪生的“表面繁荣”与“深层困境”
2026年3月,苏州某精密机械厂的生产线上,一台价值500万元的数控加工中心突然停机,工程师小李打开数字孪生系统,屏幕上立刻显示出设备的3D模型,温度、振动、电流等数据实时跳动。“看,温度超标了!”他指着屏幕说,但当被问及“为什么温度会超标?是刀具磨损、冷却液不足,还是主轴轴承故障?”时,小李却支支吾吾——系统只能“显示状态”,无法“解释原因”,更别提“预测故障”了。
这并非个例,在深圳某电子厂,数字孪生系统被用来监控SMT贴片机的运行,但当设备出现“贴片偏移”故障时,系统只能报警,却无法自动调整参数或推荐解决方案,工程师不得不手动检查20多个可能的原因,耗时3小时才解决问题。“这数字孪生,不就是个‘高级监控器’吗?”车间主任王师傅吐槽道。
问题出在哪里?
根据工信部2026年发布的《工业数字孪生技术应用白皮书》,当前企业部署数字孪生的主要误区是:过度关注“建模精度”和“数据采集”,却忽视了“模型的学习能力”和“系统的自适应能力”,换句话说,大多数数字孪生系统是“静态的”,只能反映当前状态,无法根据历史数据和实时反馈持续优化——而这,正是“神经可塑性”的核心价值。
神经可塑性:数字孪生的“大脑”
“神经可塑性”原本是神经科学领域的概念,指大脑在经历学习、训练或损伤后,神经元之间的连接会重新组织,形成新的功能回路,2026年,这一概念被引入工业数字孪生领域,用来描述系统通过数据驱动、自我学习和动态调整,实现从“被动监控”到“主动优化”的跨越。
“传统的数字孪生像‘死模型’,而具备神经可塑性的系统是‘活模型’。”清华大学工业工程系教授李明在接受采访时打了个比方,“它不仅能‘看’,还能‘想’——通过分析历史故障数据、操作记录和环境参数,自动识别模式、预测风险,甚至推荐最优解决方案。”
案例1:上海电气风电集团的“自进化”风机
污水处理与节能改造及生物多样性热度持续走高,行业关注度持续提升 2026年5月,上海电气风电集团在江苏如东海上风电场部署了一套基于神经可塑性的数字孪生系统,该系统不仅实时监控每台风机的叶片角度、齿轮箱温度、发电机功率等参数,还能通过机器学习算法,从海量历史数据中挖掘“隐性知识”。
“我们发现当风速在8-10米/秒、叶片角度在15度时,齿轮箱的振动频率会异常升高。”集团数字孪生项目负责人张工说,“传统系统只能报警,但我们的系统会进一步分析:是润滑油不足?还是轴承磨损?它会结合当前工况、历史维修记录,甚至天气预报(比如未来2小时风速变化),推荐最可能的故障原因和解决方案。”
更厉害的是,系统会“每次故障的处理过程,如果工程师采纳了它的建议并成功解决问题,系统会强化这一决策路径;如果建议无效,系统会调整算法权重。“就像人的大脑一样,越用越聪明。”张工说。
据统计,该系统部署后,风机故障预测准确率从65%提升至89%,非计划停机时间减少42%,年维护成本降低2800万元。
案例2:三一重工的“会思考”挖掘机
在湖南长沙的三一重工产业园,一台SY215C挖掘机正在进行耐久性测试,与普通挖掘机不同,它的数字孪生系统内置了“神经可塑性引擎”,能根据驾驶员的操作习惯、土壤类型和负载情况,动态调整发动机功率和液压系统压力。
“当驾驶员习惯‘急加速’时,系统会分析这种操作对发动机的磨损,并推荐更柔和的加速曲线。”三一重工数字孪生实验室主任陈博士说,“如果驾驶员多次忽略建议,系统会降低推荐频率;但如果采纳后效率提升,系统会加强这一建议。”
更有趣的是,系统还能“学习”不同工况下的最优参数,在内蒙古的煤矿,它学会了在硬土层中降低转速、增加扭矩;在四川的水利工程,它学会了在湿滑地面调整履带张力。“这就像给挖掘机装了一个‘智能大脑’,能自己适应环境。”陈博士说。

据测试,具备神经可塑性的挖掘机,燃油消耗降低12%,作业效率提升8%,设备寿命延长15%。
为什么神经可塑性被忽视?技术、成本与认知的三重障碍
既然神经可塑性如此重要,为什么大多数企业仍停留在“静态数字孪生”阶段?记者调查发现,主要存在三大障碍:
技术门槛高:从“建模”到“学习”的跨越
传统的数字孪生系统主要依赖物理建模和传感器数据,技术相对成熟,但神经可塑性需要引入机器学习、深度学习、强化学习等AI技术,对企业的数据治理、算法开发和计算能力要求极高。
“我们试过用开源的机器学习框架,但发现工业数据和互联网数据完全不同。”东莞某模具厂CTO王总说,“工业数据噪声大、标签少、时序性强,传统算法根本跑不通。”
即使解决了算法问题,计算资源也是一大挑战,上海某汽车厂曾尝试部署神经可塑性系统,但发现训练一个故障预测模型需要2000个GPU小时,成本高达50万元。“小企业根本玩不起。”该厂信息化部长感叹。
成本投入大:短期看不到回报
神经可塑性系统的部署成本是传统数字孪生的3-5倍,除了硬件(传感器、边缘计算设备)和软件(AI平台、算法库)投入,还需要持续的数据标注、模型训练和系统优化。
“我们2025年投了800万做数字孪生,结果只用来监控设备状态,领导觉得‘不值’。”杭州某纺织厂IT总监说,“如果再投2000万做神经可塑性,短期内看不到明显效益,谁敢拍板?”

认知偏差:把数字孪生当“项目”而非“能力”
2026年电力市场化与可穿戴设备及绿色办公热度持续攀升,相关应用不断深化 大多数企业将数字孪生视为一个“一次性项目”——找供应商建个模型、接几个传感器、开发个监控界面,项目验收就结束了,但神经可塑性需要企业将其视为一种“持续进化的能力”,需要长期投入数据、算法和人才。
2026年聚焦无障碍设计与数字鸿沟新趋势,应用场景不断拓展 “我们曾和一家企业合作,系统上线后,他们连数据都不愿意持续更新,更别说模型训练了。”某AI公司解决方案总监吐槽,“这样的系统,怎么可能有神经可塑性?”
破局之道:从“技术驱动”到“业务驱动”
尽管挑战重重,但2026年的工业领域,已有少数企业通过“业务驱动”的方式,成功突破神经可塑性的瓶颈,他们的经验值得借鉴:
聚焦高价值场景:从“全量建模”到“精准优化”
“不要试图用数字孪生监控所有设备,先解决最痛的痛点。”李明教授建议,“选择故障率高、维修成本高、影响生产的关键设备,用神经可塑性系统实现精准预测和优化。”
上海电气风电集团的做法就是典型,他们没有为所有风机部署神经可塑性系统,而是先在故障率最高的20台风机上试点,验证效果后再逐步推广。“这样既能控制成本,又能快速看到回报,领导才愿意持续投入。”张工说。
构建“数据-算法-业务”闭环:让系统自己“进化”
神经可塑性的核心是“学习”,而学习需要数据反馈,企业需要建立一套机制,将系统的预测结果、推荐方案与实际业务结果对比,形成“数据采集-模型训练-决策推荐-效果反馈”的闭环。
三一重工的做法值得参考,他们的挖掘机数字孪生系统,不仅收集设备数据,还通过车载终端收集驾驶员的操作反馈(是否采纳建议”“采纳后效率如何”),这些反馈数据被用于持续优化算法,形成“越用越聪明”的良性循环。