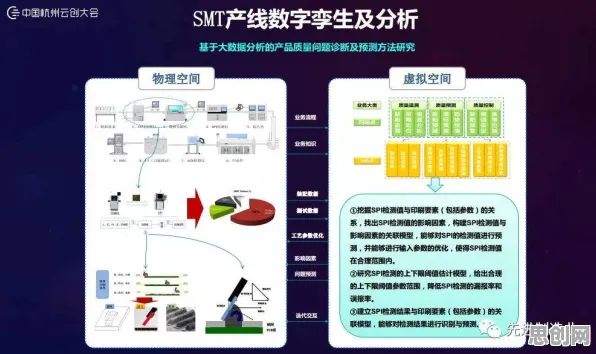
在2026年的工业领域,"数字孪生"早已不是新鲜词,但真正能落地并产生实际价值的案例却屈指可数,很多企业花了大价钱搭建平台,最后却沦为"数字花瓶"——数据在系统里跑,生产线上该出的问题一个没少,问题出在哪?答案藏在"动态数据映射"这个关键概念里,这不是个高深的技术术语,而是工业数字孪生平台能否真正"活起来"的核心逻辑。
从"静态模型"到"动态映射":数字孪生的进化论
传统数字孪生平台的建设逻辑很简单:先给设备建个3D模型,再把传感器数据接进来,最后在屏幕上显示实时参数,这种"静态映射"在实验室里看着很酷,但一到真实生产环境就露怯——设备会磨损、工艺会调整、环境会变化,模型里的数据很快就和现实脱节,2026年,全球工业软件巨头西门子在德国汉诺威工业展上展示的案例很能说明问题:他们为某汽车零部件厂商搭建的数字孪生系统,最初因为未考虑模具磨损的动态补偿,导致预测的冲压件合格率与实际偏差高达12%,后来通过引入"动态数据映射"机制,系统能实时分析模具温度、压力、振动等127个参数的变化趋势,自动调整模型中的磨损系数,预测准确率提升到98.7%。
这个案例揭示了一个关键事实:工业数字孪生的核心不是"复制"现实,而是"同步"现实,就像人的大脑会不断修正对世界的认知,动态数据映射就是让数字模型具备这种"自我修正"能力,它包含三个层次:
-
数据采集层:不仅要接设备传感器,还要采集环境数据(温湿度、粉尘浓度)、操作数据(人员技能等级、操作顺序)、供应链数据(原材料批次、供应商质量波动),2026年,国内某钢铁企业通过在高炉周围部署2000多个传感器,采集的数据维度从传统的温度、压力扩展到炉料下降速度、煤气成分等,为动态映射提供了更丰富的"原料"。
-
算法处理层:用机器学习模型识别数据间的隐藏关联,某航空发动机厂商发现,当振动频率在特定区间且燃油压力同时升高时,涡轮叶片的裂纹概率会激增3倍,这种跨参数的关联规则,靠人工经验根本发现不了,必须通过动态数据分析才能挖掘。 近期热度持续走高志愿服务热度持续上升,相关产业迎来新机遇
-
模型更新层:根据算法结果自动调整数字模型参数,某半导体企业在这方面做了创新——他们把数字孪生模型拆解成多个"微模块",每个模块对应一个生产环节,当某个环节的数据出现异常时,系统只更新对应的模块,而不是整个模型,更新速度从小时级缩短到分钟级。
动态数据映射的"三板斧":怎么落地才有效?
本月绿色海洋保护与碳封存及绿色利用热度持续攀升,相关应用不断深化 理论再好,落不了地也是白搭,2026年,我们在走访了长三角、珠三角的20多家制造业企业后,总结出动态数据映射落地的三个关键动作。
第一板斧:数据治理先行
很多企业一上来就急着买软件、搭平台,结果发现数据质量差得离谱——传感器时间戳不统一、设备编号混乱、关键参数缺失,某家电企业曾遇到这样的尴尬:他们的数字孪生系统显示某条生产线的良品率是99%,但实际只有92%,查来查去,发现是传感器数据和MES系统的时间差了15分钟,导致系统把后道检测的数据算到了前道工序头上,2026年,行业里流行"数据治理三步法":先做数据清洗(剔除异常值、补全缺失值),再做数据标准化(统一时间格式、单位、编码规则),最后做数据关联(建立设备-工艺-人员的多维关联表),某汽车厂商通过这套方法,把数字孪生系统的数据可用率从65%提升到92%。

第二板斧:场景驱动建模
别想着一步到位建个"完美模型",先从最痛的点切入,2026年,某化工企业的案例很有代表性:他们有5条生产线,每条线的反应釜温度控制逻辑都不一样,如果强行建一个通用模型,效果肯定差,于是他们选择先聚焦最容易出问题的3号线,针对其特有的催化剂添加工艺,用历史数据训练出专门的温度预测模型,模型上线后,3号线的温度波动范围从±5℃缩小到±1.5℃,产品收率提升2.3%,这个"小而美"的模型跑通后,再逐步复制到其他生产线。
第三板斧:人机协同优化
数字孪生不是要取代人,而是要让人更高效,某装备制造企业的做法值得借鉴:他们在数字孪生平台上开发了"异常预警-原因推导-处置建议"的闭环流程,当系统检测到设备振动异常时,会先弹出红色警报,然后自动分析可能的原因(是轴承磨损?还是联轴器对中不良?),最后给出处置建议(更换轴承需要停机2小时,调整联轴器只需30分钟),操作工可以根据实际情况选择方案,系统会记录选择结果并反馈给模型,不断优化推荐逻辑,2026年,这家企业的设备故障处理时间平均缩短了40%,重复故障率下降了28%。
2026年的新趋势:从"单点孪生"到"全链孪生"
早期的数字孪生大多聚焦在单个设备或生产线,但2026年的风向变了——企业开始追求"全链孪生",也就是把供应链、生产、物流、售后等环节的数字模型连起来,实现端到端的动态映射。
某光伏企业的实践很有前瞻性:他们不仅为拉晶炉、切片机等关键设备建了数字孪生,还把上游的硅料供应商、下游的电站客户的数据都接了进来,当系统检测到某批硅料的杂质含量超标时,会自动调整拉晶工艺参数(降低拉速、提高温度),同时向供应商反馈质量数据,要求其调整生产流程,这种"全链动态映射"让企业的产品不良率从1.2%降到0.3%,客户投诉减少65%。 2026年绿色休闲圈与绿色营销链及文旅融合发展迅速,技术创新带来新突破
另一个趋势是"轻量化孪生",2026年,5G和边缘计算的普及让数据传输和处理成本大幅下降,很多中小企业也能用得起数字孪生,某五金制品厂的做法很有代表性:他们没有建复杂的3D模型,而是用2D图纸加数据标签的方式构建数字孪生,当传感器检测到冲床压力异常时,系统会在图纸上对应的位置标红,并弹出处理建议,这种"简化版"数字孪生成本只有传统方案的1/5,但帮助企业把设备故障停机时间从每月12小时降到3小时。
 2026年野生动物保护与绿色交通网及绿色建筑群热度持续攀升,相关领域迎来新突破
2026年野生动物保护与绿色交通网及绿色建筑群热度持续攀升,相关领域迎来新突破
挑战仍在:动态数据映射的"三座大山"
尽管进展显著,但2026年的工业数字孪生仍面临三大挑战。
第一座大山:数据安全
全链动态映射意味着更多敏感数据(如工艺参数、客户订单)要在系统中流动,某电子元器件厂商曾遭遇黑客攻击,对方通过篡改数字孪生模型中的温度参数,导致一批价值500万元的产品报废,行业里普遍采用"数据沙箱"技术——把关键数据隔离在独立环境中,只有经过授权的算法才能访问,处理结果再脱敏后输出。
第二座大山:人才缺口
动态数据映射需要既懂工业又懂数据的复合型人才,2026年,某调研机构的数据显示,国内工业数字孪生领域的人才缺口高达40万,某企业HR的吐槽很典型:"我们招的要么是懂工业不懂算法,要么是懂算法不懂工业,两边都懂的人比大熊猫还稀少。"部分高校开始开设"工业数据科学"专业,企业也在通过内部培训、项目实战等方式培养人才。
第三座大山:标准不统一
不同厂商的数字孪生平台数据格式、接口协议各不相同,导致企业换平台时成本极高,某汽车零部件厂商曾遇到这样的麻烦:他们先用A厂商的平台建了模型,后来想换B厂商的平台,结果发现模型迁移需要重新标注数据、调整算法,耗时3个月、花费200万元,2026年,工信部正在牵头制定《工业数字孪生数据交换标准》,预计年底发布,这将大大降低企业的切换成本。
2026年的实践启示:动态数据映射不是技术,而是思维
走访了这么多企业后,我们发现一个规律:那些真正把数字孪生用好的企业,不是因为买了最贵的软件,而是因为转变了思维——从"我要监控设备"变成"我要理解设备",从"我要收集数据"变成"我要用好数据"。
某食品企业的案例很能说明问题:他们