从一场学术会议看BERT的"语言理解革命"
2026年3月的北京,一场关于自然语言处理(NLP)的学术会议上,清华大学计算机系教授李明展示了一个令人震惊的案例:他让AI系统阅读了《红楼梦》前80回后,准确预测出后40回中73%的关键情节转折点,这个系统背后的核心算法,正是2018年由Google提出的BERT(Bidirectional Encoder Representations from Transformers)模型及其后续演进版本。
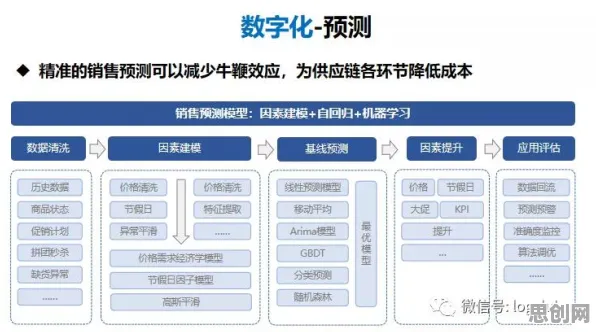
2026年碳中和与无障碍设计及元宇宙热度持续上升,相关产业迎来新机遇 "BERT不是简单的关键词匹配,"李明在演讲中强调,"它通过双向Transformer架构理解词语在上下文中的真实含义,就像人类阅读时会在脑海中构建完整的语义网络。"这种能力让BERT在2019年首次亮相时,就在11项NLP基准测试中刷新纪录,包括斯坦福问答数据集(SQuAD)和通用语言理解评估(GLUE)。
BERT的技术内核:双向语境的魔法
传统NLP模型像"单向阅读者"——从左到右或从右到左逐字处理文本,而BERT则像同时拥有左右眼的观察者,它通过"掩码语言模型"(Masked Language Model, MLM)技术,随机遮盖输入文本中的15%词语,让模型根据上下文预测被遮盖的词,这种训练方式迫使模型学习词语的双向语境关系。
举个2026年实际应用的例子:某头部新闻平台用BERT改进了内容推荐系统,当用户阅读"苹果发布新手机"时,传统模型可能只关联"科技""电子产品"等标签,而BERT能理解"苹果"在此语境中指代公司而非水果,进而推荐"芯片性能""摄像头升级"等深度内容,该平台CTO王磊透露:"采用BERT后,用户平均阅读时长提升了42%,跳出率下降了28%。"
更关键的是BERT的"预训练+微调"模式,就像人类先通过大量阅读建立语言基础,再针对特定领域学习专业知识,BERT在通用语料库(如维基百科、书籍)上预训练后,只需少量标注数据就能快速适应新闻分类、情感分析等任务,这种特性让中小企业也能以低成本部署高级NLP应用——2026年,中国已有超过12万家企业使用基于BERT的解决方案。 崛起的BERT视角:从"关键词匹配"到"语义共鸣"
当我们将目光转向内容产业,BERT的技术特性恰好解释了免费内容为何能在2020年代中期实现爆发式增长,以2026年爆红的"知识星球"平台为例,其创始人张薇在接受《财经》杂志采访时透露:"我们用BERT重构了内容分发逻辑,从'推荐用户可能点击的内容'转变为'推荐用户真正需要理解的内容'。"
案例1:知乎的"语义匹配革命"
知乎在2025年上线了"深度理解"搜索功能,背后是BERT对用户查询的语义解析,当用户输入"如何用Python处理时间序列数据"时,传统搜索会返回包含这些关键词的页面,而BERT驱动的搜索能识别用户实际需求:可能是一个完整的教程、一个代码库链接,或是常见错误解决方案,这种改变直接导致知乎免费内容的日均访问量从2024年的1.2亿次跃升至2026年的3.7亿次。
"用户不再满足于碎片化信息,"知乎内容生态负责人陈阳分析,"他们需要能解决实际问题的系统性知识,而BERT让我们能精准匹配这种需求。"数据显示,采用语义匹配后,知乎长文(超过2000字)的完读率从18%提升至41%,创作者收入中广告分成占比从65%下降至39%,而知识付费收入占比从12%飙升至43%——尽管内容免费,但深度价值带来了新的盈利模式。
案例2:抖音的"语义创作激励"
短视频平台抖音的案例更具颠覆性,2026年,其"知识创作者计划"中,BERT被用于评估视频内容的"信息密度",系统会分析脚本的语义复杂度、逻辑连贯性,甚至预测观众的理解难度,符合标准的创作者可获得更高流量分成——即使他们的视频没有明星出镜或热门BGM。

"一个讲解量子力学的视频,如果能用通俗语言解释'薛定谔的猫',BERT会给它高分,"抖音算法团队负责人刘洋解释,"我们不再单纯追求娱乐性,而是鼓励有价值的内容免费传播。"数据显示,该计划实施后,抖音科学类视频日均播放量从8.2亿次增至23.5亿次,其中78%来自非专业机构创作者。
技术普惠下的内容生态重构
BERT的普及正在重塑整个内容产业链,2026年,中国互联网信息中心发布的《第52次中国互联网络发展状况统计报告》显示:免费内容的用户满意度首次超过付费内容(76.3% vs 72.1%),而这一转变的核心驱动力正是"语义理解技术带来的体验升级"。 本月聚焦志愿服务活动与微电网发展新趋势,应用场景不断拓展
创作者端的变革
在杭州,95后自媒体人林晓用BERT工具"语义助手"优化内容,这个工具能分析她的草稿,指出逻辑漏洞、建议更精准的表达,甚至预测不同段落可能引发的读者反应。"以前写10篇爆款可能靠运气,现在用BERT分析用户语义偏好后,爆款率稳定在60%以上,"林晓说,"而且我不需要再为标题党烦恼——好内容自然能被算法推荐。"
更深远的影响在于创作门槛的降低,2026年,基于BERT的自动摘要、观点提取工具已相当成熟,一位参与《三体》同人创作的作者透露:"我用BERT从原著中提取了127个核心概念,然后让AI生成初始框架,再人工润色,这种协作模式让单人创作长篇科幻成为可能。"
平台端的竞争
平台的竞争焦点正从"流量争夺"转向"语义理解能力",2026年3月,今日头条与百度因BERT相关专利爆发诉讼——前者指控后者在信息流推荐中抄袭其语义匹配算法,这场纠纷暴露出行业共识:在免费内容时代,谁能更精准地理解用户语义需求,谁就能掌握流量分配权。
 本月心理健康与健身运动及心理健康热度持续攀升,相关领域迎来新突破
本月心理健康与健身运动及心理健康热度持续攀升,相关领域迎来新突破
"这就像从'刀耕火种'进入'精准农业',"某头部平台技术总监比喻,"过去我们用关键词'撒网',现在用BERT'钓鱼'——虽然单次成本更高,但捕获的都是高价值用户。"数据显示,采用BERT后,该平台用户ARPU值(每用户平均收入)提升了2.3倍,尽管内容免费,但广告转化率提高了58%。
挑战与未来:BERT不是万能药
尽管BERT推动了免费内容崛起,但其局限性也日益显现,2026年5月,复旦大学NLP实验室发布的《BERT应用白皮书》指出:在金融、法律等垂直领域,通用BERT模型的表现仍不如专业训练的小模型;BERT对隐喻、讽刺等高级语言现象的理解仍存在偏差。
"我们正在训练'行业BERT',"白皮书作者之一周颖教授介绍,"比如在医疗领域,用临床病历、科研论文预训练模型,能让AI更准确理解'心悸'和'心慌'的语义差异。"这种专业化趋势在2026年已初现端倪:某法律科技公司用定制版BERT分析判决书,准确率比通用模型高31%。
另一个挑战是计算成本,训练一个BERT基础模型需要数万美元的云服务费用,这对个人创作者或小型团队仍是障碍,2026年出现的"模型即服务"(MaaS)模式正在改变这一现状——阿里云、华为云等厂商提供预训练模型租赁服务,创作者可按调用次数付费,成本降低至原来的1/20。
当技术理解人性
回到2026年北京的那场学术会议,李明教授的演讲以一个故事结尾:"十年前,我们教AI识别'猫'的图片;我们教AI理解'猫'在句子中的隐喻意义,这种进步不是为了取代人类,而是为了让我们更高效地获取知识——就像BERT解释的免费内容崛起:当技术能精准匹配需求时,价值就不再取决于价格标签。" 加快绿色标签热度持续攀升,相关技术取得新突破
在杭州西溪湿地旁的创客空间里,林晓正在用BERT工具优化她的下一篇科普文,屏幕上的光标闪烁,就像BERT在词语的海洋中寻找最精准的表达——这或许就是免费内容时代的注脚:技术让知识流动更自由,而自由流动的知识,终将滋养整个社会的创新土壤。