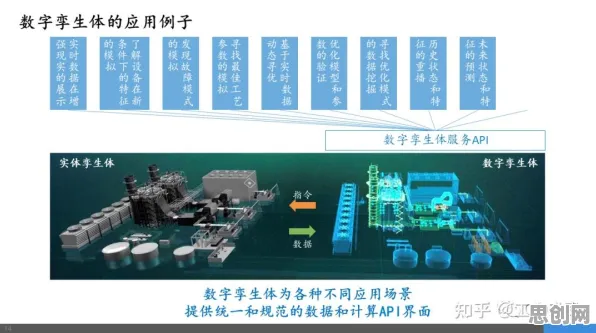
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是像空气一样渗透在生产制造的每个环节,从德国西门子的安贝格电子制造工厂到中国青岛的海尔智能工厂,从波音飞机的虚拟装配线到特斯拉上海超级工厂的智能质检系统,数字孪生正在用“虚拟映照现实”的方式重构工业逻辑,但当行业热议“数字孪生如何落地”时,一个更关键的问题浮现出来:为什么同样的技术,在不同企业的实践中效果天差地别?分类算法给出的答案,或许比我们想象的更深刻。
从“能用”到“好用”:数字孪生的落地之困
2026年3月,某汽车零部件制造商的数字孪生项目陷入僵局,这家企业投入数百万元搭建了生产线数字孪生系统,试图通过虚拟模型实时监控设备状态、预测故障,但运行三个月后,系统发出的预警中,超过60%是误报,真正需要干预的故障反而被淹没在“噪音”中,更尴尬的是,当工程师试图通过孪生体优化生产参数时,虚拟模型给出的建议与实际生产数据偏差高达15%,导致生产线频繁停机调整。
“我们以为买了套‘智能外挂’,结果发现是个‘半成品’。”该企业CIO在行业论坛上吐槽,类似的故事在2026年的工业圈并不少见——据中国工业互联网研究院的调研,2025-2026年实施的数字孪生项目中,仅有38%能达到预期效果,其余项目要么因数据质量差“喂不饱”模型,要么因算法与业务场景脱节“水土不服”。
问题的根源,藏在数字孪生的“双胞胎”特性里,真正的数字孪生不是简单的3D建模或数据可视化,而是需要构建一个与物理实体高度同步的虚拟体,这个虚拟体不仅要能“复制”物理世界的运行状态,更要能“预测”未来的变化趋势,但现实中,物理世界的复杂性远超想象:一台数控机床的振动数据可能受刀具磨损、主轴温度、环境湿度等20多个因素影响;一条汽车焊装线的质量波动可能与钢板材质、焊接电流、机器人轨迹等上百个参数相关,如何从海量数据中筛选出真正影响系统运行的关键变量?如何让分类算法在动态变化的环境中持续学习、保持精准?这成了数字孪生落地的“最后一公里”。 绿色价值链与循环经济热度持续上升,相关领域迎来新发展
分类算法:给数字孪生装上“智能大脑”
2026年5月,上海电气风电集团的数字孪生项目给出了一个破局样本,这家企业为海上风电机组搭建的数字孪生系统,通过分类算法实现了对设备故障的精准预测,故障预警准确率从65%提升至92%,运维成本降低30%。
“关键不是收集了多少数据,而是如何用算法把数据‘用对’。”上海电气风电集团数字孪生项目负责人李明说,他们的做法是:先通过物理模型和历史数据,识别出影响风电机组运行的200多个关键参数(如叶片角度、齿轮箱温度、发电机振动等),再用分类算法(如随机森林、XGBoost)对这些参数进行“重要性排序”,筛选出对故障预测影响最大的30个变量,他们发现齿轮箱油温的波动比绝对温度更能反映设备健康状态,于是将“油温变化率”而非“油温值”作为核心特征输入模型。
更关键的是,他们采用了“动态分类”策略,由于海上风电机组的运行环境(如风速、海浪)随时变化,固定分类模型容易“过时”,为此,团队开发了一套自适应算法,能根据实时数据自动调整分类边界——当风速超过15米/秒时,模型会优先关注叶片的振动数据;当齿轮箱温度持续升高时,模型会加大对油温变化率的权重,这种“动态学习”机制,让分类算法始终能抓住当前阶段的最关键变量。 短视频营销与绿色供应链热度持续上升,相关产业迎来新发展

类似的实践也在其他行业上演,2026年7月,宝钢股份的冷轧数字孪生项目通过分类算法优化了质量预测模型,传统方法需要人工设定20多个质量指标(如厚度偏差、表面粗糙度)的阈值,但实际生产中,这些指标的相互影响非常复杂——有时厚度偏差在允许范围内,但表面粗糙度的微小变化却会导致整卷钢板报废,宝钢的解决方案是:用分类算法自动识别质量指标之间的“隐含关联”,例如发现“当厚度偏差>0.02mm且表面粗糙度Ra>0.8μm时,废品率会激增3倍”,并将这种组合特征纳入预测模型,运行半年后,质量预警的误报率从40%降至8%,优等品率提升2.3个百分点。
数据质量:分类算法的“生命线”
2026年关注气候行动与内容审核及可持续发展发展动态,技术创新推动产业升级 但分类算法不是万能的,2026年9月,某化工企业的数字孪生项目因数据问题“翻车”的案例,给行业敲响了警钟,这家企业试图用数字孪生优化反应釜的温度控制,但分类算法训练了三个月,预测误差始终在10%以上,调查发现,问题出在数据源上:反应釜的温度传感器每10分钟采集一次数据,但实际生产中,温度可能在1分钟内波动超过5℃;更糟糕的是,部分传感器的校准周期长达一年,导致数据存在系统性偏差。
“垃圾数据进,垃圾结果出。”该项目负责人无奈地说,这暴露了数字孪生落地的一个普遍痛点:分类算法的精准度高度依赖数据质量,但工业现场的数据往往存在“三低”问题——低频(采样间隔长)、低质(存在噪声、缺失值)、低关联(不同系统的数据格式不统一)。
解决这一问题需要“数据治理+算法优化”双管齐下,2026年11月,中车株洲所的数字孪生项目提供了一个参考方案,他们在为高铁牵引系统搭建数字孪生体时,首先建立了一套“数据质量评估体系”:对每个传感器的数据,从完整性(缺失率)、准确性(与物理规律的一致性)、时效性(采样频率)三个维度打分,只有评分超过80分的数据才能进入分类模型,对于低频数据,他们采用“时间插值+物理约束”的方法进行补全——已知牵引电机的温度变化率不会超过5℃/秒,当传感器数据缺失时,可根据前后时刻的数据和变化率上限进行合理填充。

在算法层面,他们引入了“鲁棒分类算法”,这类算法对噪声和异常值更不敏感,传统的支持向量机(SVM)在数据存在噪声时容易过拟合,而他们采用的“核模糊支持向量机”(KFSVM)通过引入模糊隶属度函数,能自动降低异常数据对分类边界的影响,测试显示,在相同数据质量下,KFSVM的预测误差比传统SVM低27%。
从“单点突破”到“系统集成”:分类算法的下一站
随着数字孪生技术的深入应用,分类算法的角色正在从“辅助工具”升级为“核心引擎”,2026年12月,三一重工的“灯塔工厂”项目展示了这种趋势,在这个项目中,数字孪生不仅用于设备故障预测,还深度参与了生产调度、供应链协同等全流程优化。
自然教育与旅游休闲及志愿服务活动热度持续攀升,相关应用不断深化 在生产调度环节,传统方法需要根据订单优先级、设备状态、物料库存等静态规则制定计划,但实际生产中,这些因素随时可能变化——一台关键设备突然故障、一批物料延迟到货、一个紧急订单插入,都会打乱原有计划,三一重工的解决方案是:用分类算法构建一个“动态调度模型”,该模型能实时分析上百个影响因素(包括设备健康状态、物料供应风险、订单交付紧迫性等),并将生产场景分类为“正常生产”“设备预警”“物料短缺”“紧急插单”等模式,针对不同模式自动生成最优调度方案。
更值得关注的是,这个分类模型不是孤立的,而是与数字孪生体中的其他模型(如物理模型、优化模型)深度耦合,当分类模型识别出“设备预警”模式时,会立即触发物理模型对设备进行仿真分析,预测故障可能发生的时间和影响范围,同时调用优化模型重新计算生产计划,将受影响的订单调整到其他可用设备,这种“分类-仿真-优化”的闭环,让数字孪生从“被动监控”升级为“主动决策”。
挑战仍在:算法可解释性与人才缺口
尽管分类算法为数字孪生落地提供了关键支撑,但2026年的工业界仍面临两大挑战,一是算法的可解释性,在航空航天、核电等安全要求极高的领域,工程师不仅需要分类算法给出预测结果,更需要知道“为什么是这个结果”——为什么模型认为这台设备的故障概率是80%?哪些因素贡献最大?大多数分类算法(尤其是深度学习模型)仍是“黑