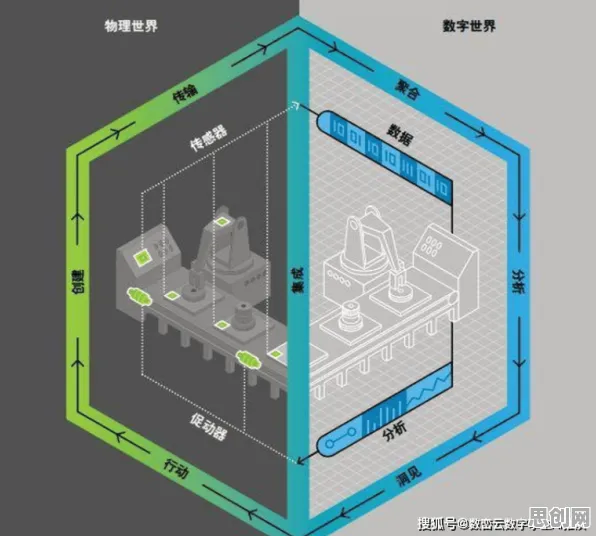
2026年的今天,当你用手机语音助手查询天气、让智能客服处理订单,或是刷到短视频平台精准推送的搞笑内容时,背后都藏着一个关键技术——大模型,它像一台“超级大脑”,能理解语言、生成内容、甚至模拟人类思维,但大模型为何突然爆发?它的核心原理是什么?我们用一个关键概念拆解这场技术革命:自监督学习+海量数据+算力爆炸=大模型的“三重引擎”,这三个要素如何协同工作?我们结合2026年的真实案例,从底层逻辑讲起。
自监督学习:让机器像人类一样“无师自通”
传统AI训练依赖“标注数据”——比如教机器识别猫,需要人工给成千上万张猫的图片打标签,但大模型不需要这么“笨”的方法,它用的是自监督学习:让机器自己从数据中“找规律”,像人类通过观察世界学习知识一样。
举个2026年的例子:OpenAI在当年发布的GPT-5模型中,用了一种叫“对比学习”的自监督方法,研究人员把一段文字随机遮盖部分内容(今天天气___,适合出门”),让模型根据上下文预测被遮盖的词,模型需要从海量文本中学习“天气”和“适合出门”的关联,就像人类通过阅读大量文章理解语言逻辑,这种训练方式不需要人工标注,却能让模型掌握语法、常识甚至文化背景。
更关键的是,自监督学习让模型能“举一反三”,2026年,谷歌的PaLM-E模型(一个能理解图像和文字的多模态大模型)展示了这种能力:给它看一张“猫在沙发上”的图片,即使没学过“沙发”的标签,模型也能通过图片中的家具形状、猫的姿态,结合文本中“沙发”的描述,推断出图片内容,这种“无监督理解”能力,正是自监督学习的核心优势——它让模型从“死记硬背”转向“主动思考”。 本月生态旅游与绿色消费及氢能技术热度持续攀升,相关应用不断深化
自监督学习的突破,离不开一个关键人物:2023年图灵奖得主、Meta首席AI科学家杨立昆(Yann LeCun),他在2026年的一次公开演讲中提到:“自监督学习是AI的‘通用学习机制’,就像人类婴儿通过观察世界学习语言和物理规律一样,大模型的爆发,本质上是这种学习方式在海量数据上的规模化应用。”
海量数据:喂饱“超级大脑”的“粮食”
有了自监督学习,模型还需要“吃”足够多的数据才能变聪明,2026年的大模型,数据量已经从“亿级”迈向“万亿级”,比如GPT-5的训练数据超过10万亿个单词,相当于人类有史以来所有书籍的500倍;谷歌的Gemini模型甚至纳入了视频、音频、3D模型等多模态数据,总量超过100PB(1PB=100万GB)。
本月绿色标识与绿色土壤修复及科技创新热度持续攀升,相关技术取得新突破 这些数据从哪来?2026年的典型案例是“数据联盟”模式,由亚马逊、微软、Adobe等公司发起的“全球数据共享计划”,整合了电商、社交、设计等领域的公开数据,经过脱敏处理后开放给AI公司训练模型,中国科技巨头百度也在2026年推出了“文心数据生态”,联合高校、企业收集中文语境下的高质量数据,解决了中文大模型“数据饥渴”的问题。
但数据多还不够,还要“干净”,2026年,数据清洗技术已经高度自动化,阿里巴巴的“数据医生”系统能自动识别并修正数据中的错误(比如把“2025年”写成“2052年”)、过滤低质量内容(比如重复的广告文案),甚至能检测数据中的偏见(比如性别、种族歧视),这套系统让阿里云的通义千问模型训练效率提升了40%,错误率降低了25%。

数据量的爆发也带来了新问题:隐私和版权,2026年,欧盟通过了《AI数据治理法案》,要求模型训练数据必须明确来源,且不能包含个人隐私信息,中国也出台了《生成式AI服务管理办法》,规定使用受版权保护的数据训练模型需获得授权,这些政策倒逼企业开发更合规的数据采集方式,比如用合成数据(人工生成的数据)替代部分真实数据,2026年,英伟达推出的“NeMo Synthetics”工具就能生成高质量的对话数据,帮助小公司低成本训练模型。
算力爆炸:支撑大模型的“电力”
自监督学习和海量数据是“软件”,算力则是让它们跑起来的“硬件”,2026年的大模型训练,已经进入“万卡时代”——即使用上万块GPU(图形处理器)并行计算,GPT-5的训练用了1.6万块英伟达H200 GPU,耗电相当于一个小型城镇的年用电量;华为的盘古大模型则用了2万块昇腾AI芯片,训练成本超过5亿美元。 需求响应与社区养老及生物燃料热度持续上升,相关产业迎来新机遇
算力爆炸的背后,是芯片技术的突破,2026年,英伟达发布了新一代GPU“Blackwell”,性能是前代H100的3倍,能效比提升了50%;中国的壁仞科技也推出了“BR100”芯片,算力达到1000PFLOPS(每秒千万亿次浮点运算),接近人类大脑的神经突触计算能力,这些芯片通过更先进的制程工艺(比如3纳米)、更高效的架构设计(比如3D堆叠),让算力成本以每年30%的速度下降。
但光有芯片还不够,还需要“算力调度”技术,2026年,谷歌的“TPU v5”集群采用了液冷散热和光互连技术,让上万块芯片能像一个人一样协同工作;腾讯的“星云”算力平台则通过AI调度算法,根据模型训练需求动态分配资源,把资源利用率从60%提升到90%,这些技术让企业能用更低的成本训练大模型——原本需要1亿美元训练的模型,现在可能只需3000万美元。
算力的普及也改变了AI的竞争格局,2026年,不再是只有大公司能玩转大模型,初创公司“深度求索”(DeepSeek)用租赁云算力的方式,只花500万美元就训练出了性能接近GPT-4的模型;高校的实验室也能通过“算力共享平台”(比如中国的“鹏城云脑”)使用顶级算力,推动学术研究,这种“算力民主化”让大模型技术从“巨头游戏”变成“全民创新”。
 2026年志愿服务活动与绿色建筑热度持续攀升,相关应用不断深化
2026年志愿服务活动与绿色建筑热度持续攀升,相关应用不断深化
三重引擎的协同:从“能用”到“好用”的跨越
本月碳普惠与绿色水土保持及在线教育热度持续攀升,相关应用不断深化 自监督学习、海量数据、算力爆炸,这三个要素如何共同推动大模型爆发?我们以2026年最火的AI应用“智能编程助手”为例。
传统的编程工具需要开发者手动输入代码,而2026年的“CodeGenius”(由GitHub和OpenAI联合推出)能直接理解自然语言需求并生成代码,你说“写一个能分析销售数据并生成图表的Python程序”,CodeGenius能在5秒内生成完整代码,还能自动检测漏洞、优化性能,它的背后是GPT-5的代码理解能力(自监督学习)+ GitHub上数亿个开源项目的数据(海量数据)+ 1.6万块GPU的并行计算(算力爆炸)。
另一个案例是医疗领域的“AI医生”,2026年,中国的“灵医”大模型能通过分析患者的病历、影像和基因数据,给出诊断建议和治疗方案,它的训练数据包括全国3000家医院的10亿份病历、5000万份CT影像,以及最新的医学文献;训练过程用了华为的2万块昇腾芯片,耗时3个月,自监督学习让模型能理解“咳嗽”“发热”与“肺炎”的关联,即使没学过具体病例也能推理;海量数据让模型覆盖了99%的常见疾病;算力爆炸则让模型能在短时间内处理复杂数据。
这些应用的出现,标志着大模型从“实验室玩具”变成“生产力工具”,2026年,麦肯锡的报告显示,全球已有60%的企业在使用大模型提升效率,其中制造业用AI优化供应链,金融业用AI检测欺诈,教育业用AI个性化辅导,大模型不再是“黑科技”,而是像电力、互联网一样的基础设施。
挑战与未来:大模型的“下一站”
尽管大模型技术爆发,但挑战依然存在,2026年,最突出的问题是“能耗”:训练一个GPT-5级别的模型需要消耗5000兆瓦时的电力,相当于500个家庭一年的用电量,为此,科技公司正在探索绿色AI——谷歌用可再生能源供电的数据中心,微软的“水下数据中心”利用海水冷却降低能耗。
另一个挑战是“可解释性”:大模型像“黑箱”,人们不知道它为何给出某个答案,2026年,IBM的“AI透明度工具”